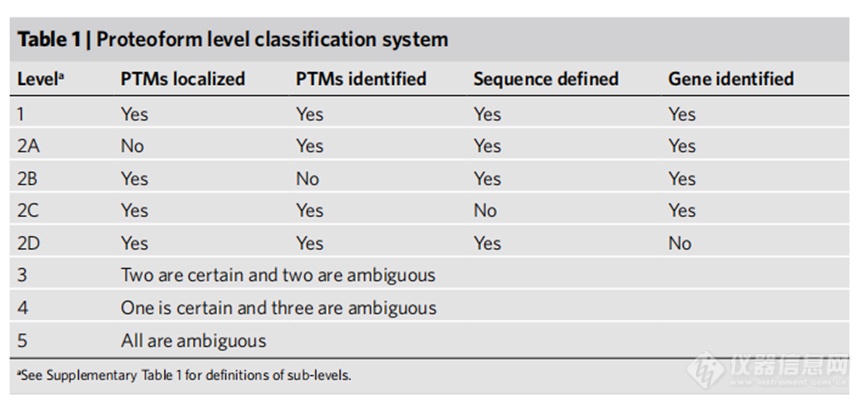
Nature Methods | Proteoform: A Single Term Describing Protein Complexity & Nature Methods | A Five-level Classification System for Proteoform Identifications
在 2013 年的文章 Proteoform: A Single Term Describing Protein Complexity 中,作者提出,随着人类基因组计划的成功,人们认识到生物机制所提供的复杂性在很大程度上是由于在蛋白质水平上的变异,而不是大量的基因水平上的不同导致的。高度相关但化学性质不同的蛋白质分子之间的差异源于群体、细胞、组织类型以及亚细胞定位的差异。在 DNA、RNA 和蛋白质水平上,蛋白质的复杂性分别来自等位基因变异、RNA 转录物的选择性剪接和翻译后修饰。这些事件产生不同的蛋白质分子,调节各种各样的生物过程,例如:细胞信号传导、基因调控和蛋白质复合物的激活。
Proteoform: a single term describing protein complexity | Nature MethodsDOI https://doi.org/10.1038/nmeth.2369A five-level classification system for proteoform identifications | Nature Methods