
高光谱成像技术对祁门红茶等级的无损检测


茶是世界上最有价值和最流行的饮品之一,茶叶不仅可以提高机体免疫力,而且可以对抗疾病。红茶在世界茶产品中是主流的消费产品,中国生产的祁门红茶是世界三大高香红茶之一,它具有独特的果香气味,受到很多人的青睐。随着人们对红茶需求的不断增加,红茶的品质越来越受到重视。目前,茶叶市场存在以次充好的现象,但仅凭感官评价正确分辨茶叶品质好坏是比较困难的,而无损检测具有快速、精确和评价标准稳定的特点,因此实现茶叶的快速无损鉴别是十分必要的。
本文利用近红外高光谱成像系统(900~1700 nm)对祁门红茶的6个等级进行分类,比较分析了PCA、MDS、t-SNE和Sammon四种不同降维技术,建立SVM和极限学习机(Extreme Learning Machine,ELM)模型并生成高光谱图像像素空间分类图。应用的900-1700nm高光谱相机,可采用杭州彩谱科技有限公司产品FS-15。短波近红外高光谱相机,采集速度全谱段可达200FPS,被广泛应用于成分识别,物质鉴别,机器视觉,农产品品质,屏幕检测等领域。


1.2实验方法
1.2.1数据采集
近红外高光谱采集仪的光谱范围为900~1700 nm,光谱分辨率为3nm,共256个波段。在实验中将茶叶样本均匀的平铺在直径为5cm,高为2cm的圆形容器中,放在前进速度为1.68 cm/s的移动台上进行图像采集,曝光时间为20 ms,镜头与样本之间的距离为32 cm。为避免外部光线影响,高光谱图像的采集过程在暗箱中进行。原始高光谱图像噪声较大,故对其进行图像校正。本文采用黑白校正和最小噪声分离变换(Minimum Noise Fraction,MNF)方法对原始数据进行去噪处理。使用ENVI5.3软件,提取50×50像素中心区域作为感兴趣区域(Region of Interest,ROI),计算其平均光谱作为样本的原始光谱。各等级的茶叶样本按照3:2分为训练集和测试集,训练集包含288个样本,测试集包含192个样本。
1.2.2数据处理
1.2.2.1数据预处理
图像采集过程中受到暗电流噪声、探测器灵敏度和光学传输特性等因素影响,导致采集的图像质量受到影响,需要对采集图片进行黑白校正。在相同的采集条件下,分别采集反射率接近100%的白帧图像和反射率接近为0%的黑帧图像。
2结果与分析
2.1 样本光谱特征
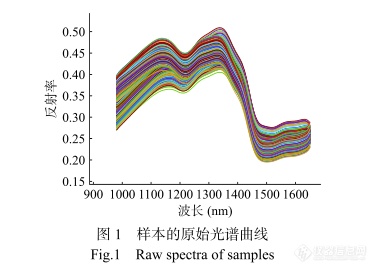
由于卤素灯在初始阶段光照强度不均匀以及仪器噪声影响,为了保证数据的准确性和实验结果的可靠性,剔除900~980 nm和1650~1700 nm,选取光谱范围在980~1650 nm的203条光谱带作为祁门红茶的原始光谱数据。所有样本的原始光谱曲线如图1所示,光谱数据受到随机噪声和散射效应的干扰,需要对其进行预处理。本文对原始光谱分别采用SG平滑滤波(Savitzky-Golay Filtering,SG)、标准正交变换(Standard Normal Variate,SNV)、多元散射校正(Multiplicative Scatter Correction,MSC)、SG-SNV和SG-MSC等算法对数据进行预处理。SG可以消除或减弱随机噪声,SNV和MSC用来校正散射现象,SG-SNV和SG-MSC对原始算法进行了优化。
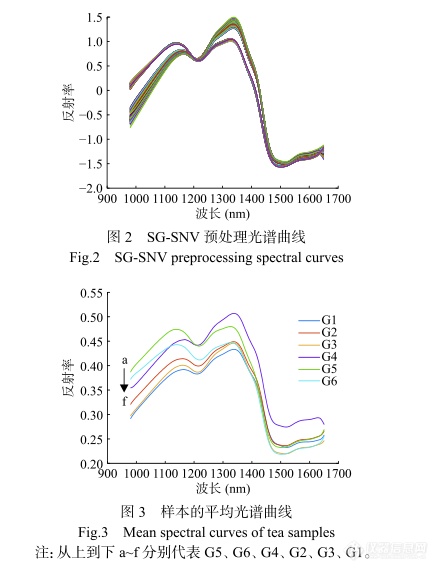
实验结果表明,SG-SNV预处理效果优于其他算法。该算法有效地修正了光散射引起的光谱基线漂移问题,使光谱的吸收峰位置更加突出,光谱曲线如图2所示。祁门红茶6个等级的平均光谱曲线如图3所示,不同等级的茶叶在三个峰处反射率差别较明显。由此可知,高光谱成像技术可建立分类模型对6个等级的祁门茶叶进行识别。
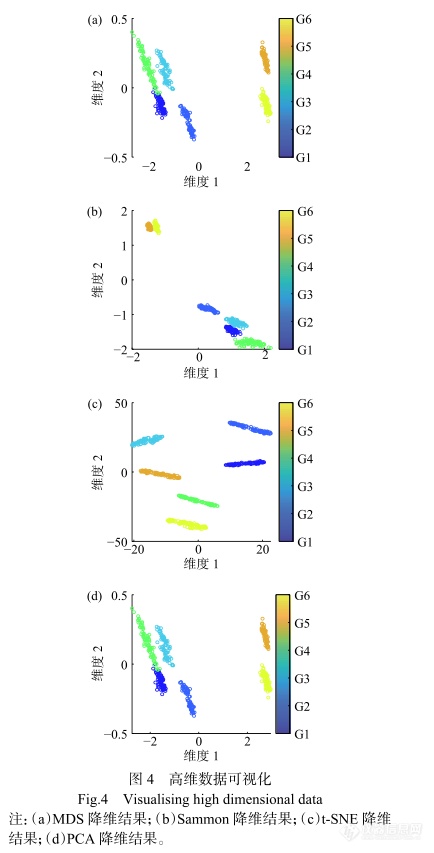
2.2 高维数据可视化
利用MDS、Sammon、t-SNE和PCA等算法对高光谱图像进行高维数据的低维可视化。实验结果如图4所示,不同颜色的聚类代表不同的茶叶等级,只有t-SNE可以将6个等级的茶叶明确区分。如图4(a)、图4(b)、图4(d)所示,MDS和PCA不能将G1和G4完全区分开,Sammon不能将G5、G6以及G1、G3完全区分开,主要原因是该样本具有相似的光谱特征。与PCA和MDS相比,Sammon对6个等级祁门红茶的可视化效果较差。由于Sammon映射没有显式地表示转换函数.该算法只是提供了一种度量方法来衡量转换结果,故分离簇的能力不强。PCA和MDS无法保持高维空间的数据结构,因其只利用了远处数据点的信息,所以分离簇能力较弱。如图4(c)所示,与其他算法相比,t-SNE能够捕获数据的非线性和邻域信息,故可呈现较好的可视化效果。由实验结果可知,t-SNE识别最大分离簇数的能力优于PCA、MDS和Sammon。光谱数据进行判别的实验结果。其中,SVM模型惩罚系数c为1.2,核函数系数g为2.8,ELM模型的隐层节点数为5。由实验结果知,SVM和SG-SNV-SVM模型,训练集和测试集的准确率分别为100%。ELM模型的识别效果较差,ELM模型的训练集和测试集准确率分别为90.27%和85.93%,SG-SNV-ELM模型的训练集和测试集识别率分别为98.61%和96.35%。预处理之后的SVM模型分类精度没有发生变化,而经过预处理的ELM模型分类精度显著提高。由此可知,SG-SNV预处理对ELM得到有效应用。
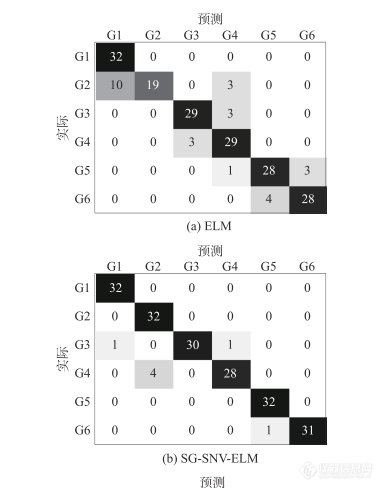
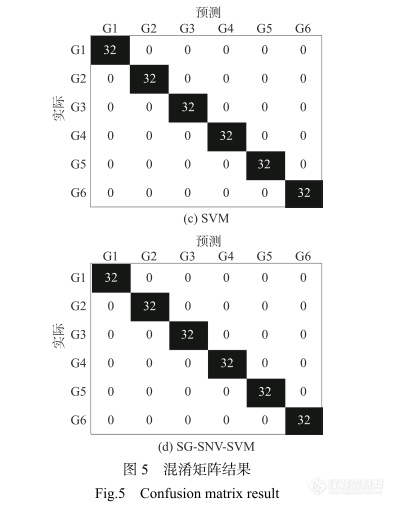
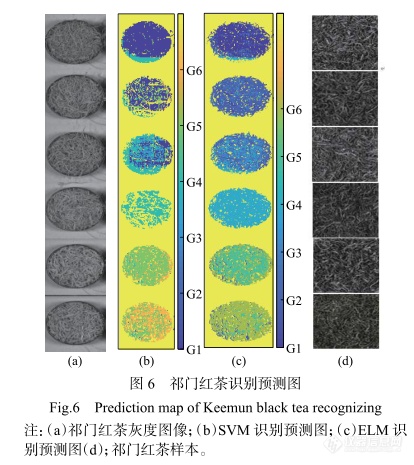
图5是不同模型的混淆矩阵结果。图5(a)混淆矩阵结果存在较多识别错误,G2中10个样本和3个样本被分别识别为G1和G4,G3中3个样本被识别为G4,G4中3个样本被识别为G3,G5中1个样本和3个样本被分别识别为G4和G6,G6中4个样本被识别为G5。图5(b)混淆矩阵结果出现少量识别错误,G3中1个样本被识别为G1,G4中4个样本被识别为G2,G6中1个样本被识别为G5。图5(c)和图5(d)的混淆矩阵结果完全正确。为了可视化6个等级祁门红茶的差异,对不同等级茶叶的像素光谱信息建立SVM和ELM识别模型,实验结果如图6示。如图6(a)所示,提取灰度图像,如图6(b)、图6(c),祁门红茶等级分类图由上到下依次为一级、二级、三级、四级、五级和六级。由图6(b)所示,SVM模型将6个等级的祁门红茶识别为各自相应的等级,但也存在一些像素点分类错误,特别是圆形容器边缘的误分类尤为明显。由图6(c)所示,ELM模型的分类图中不仅边缘像素存在误分类,而且各等级之间存在严重误分类。除去边缘分类错误,造成不同等级茶叶误分类的主要原因是光谱的相似性。误分类的另一个原因可能是茶叶的纯度,例如,将低等级的茶叶掺入高等级茶叶中进行混合售卖盈利。SVM模型的识别结果优于ELM模型。因此,SVM有较好的识别效果和性能。
3结论
本文利用近红外高光谱成像技术,结合SNV-SG、PCA、MDS、Sammon及t-SNE算法,基于光谱特征,分别建立祁门红茶等级快速无损识别的SVM模型和ELM模型。结果显示,t-SNE能更好地分离不同等级的祁门红茶,其高维空间邻近数据点的信息可以保持低维空间中的数据结构。基于光谱特征的SVM模型和ELM模型的测试集识别率分别为100%和96.35%。因此,近红外高光谱成像技术结合机器学习在茶叶产品分类的应用领域具有很大潜力。
来源于:杭州彩谱科技有限公司














热门评论
最新资讯
厂商动态
新闻专题
