
德思特分享 | TS-M4i系列数字化仪利用GPU加速实现高效块平均处理

一、应用背景
块或分段内存平均模式常用于在不同应用当中,移除信号中不相干的噪声。不管是哪家的数字化仪制造商,几乎所有基于FPGA实现的块平均模式都会受到块或者段内存大小的限。该限制一般取决于FPGA的容量,最大样品量通常在32k到500k之间。
本白皮书将展示如何使用德思特TS-M4i系列数字化仪的高速PCIe流模式来在软件中实现块平均处理,从而突破FPGA的限制。我们用了TS-M4i.2230(1通道,5 GS/s,8位垂直分辨率,1.5 GHz带宽)作为例子,对比硬件和软件进行块平均处理的效果。
二、什么是块平均?
块平均模式可以用来移除随机噪声成分,提高重复信号的保真度。该模式允许对多次单段采集进行处理、累积和平均。这个过程减少了随机噪声,提高了重复信号的可见性,平均后的信号具有增强的测量分辨率和更高的信噪比(SNR)。
块平均模式可用于改善雷达测试、天文学、质谱学、医学成像、超声波测试、光纤测试和激光测距等各种不同应用中的测量。
下面截图显示了一个较低电平的信号(大约2mV),完全被随机噪声覆盖的情形,以及使用不同平均因子获得的信号质量改进。虽然在原始单次采集中源信号基本无法看到,但10x平均时,能显示出实际上有5个信号峰。执行1000x的块平均可以进一步改善信号质量,揭示出带有二次最大值和最小值峰的完整信号形状。
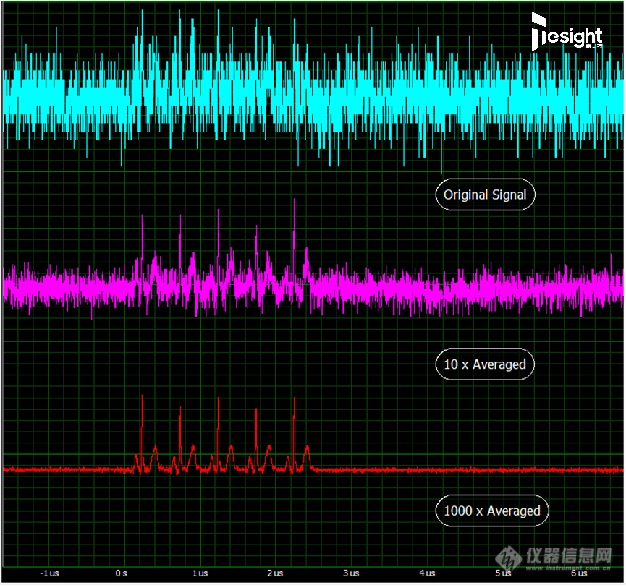
通过块平均改善噪声问题,该示例使用了一个500MS/s采样率(每个采样点2ns)和14位分辨率的数字化仪制作
三、系统配置
为了兼顾更多老旧设备的性能状况,测试系统选用了一台德思特公司内的旧办公电脑,大致配置如下:
● 主板:技嘉GA-H77-D3H
● CPU:Intel i7-3770,4核3.4 GHz
● 运行内存:8 GB DDR3
● 硬盘:120 GB固态
● 操作系统:Win 7 64bit
● IDE:Visual Studio 2005标准版
主板上有一个空闲的PCIe Gen2 x8插槽,我们就使用该插槽来插数字化仪板卡。此时,德思特的TS-M4i板卡的流式传输可以达到满速,约3.4 GB/s(不考虑数据处理的情况下)。
四、软件实现
测试软件使用纯C++编写,并基于德思特流式传输示例。数字化仪板卡通过外部触发采集,板卡会自动在每个触发事件后获取一段数据。数据会先存储在板载内存中,然后通过分散聚集式式DMA直接传输到PC的运行内存,并在运行内存中进行累积,进而执行块平均操作。我们针对不同的配置方式和优化策略进行了测试,来看看分别能达到什么样的性能水平。
摘录出来的一小段源代码显示了多线程版本的主求和循环,这正是软件处理的关键部分,也是决定速度的部分。

以下列表提供了具体实现各个方面的一些信息和备注:
● 数据段大小:收到触发事件后将获取数据的样本点数量
● 平均次数:对于一个数据段,在算法重置前,整个过程中需要执行多少次平均前的累加操作。
● 通知大小:硬件生成中断所需的数据量。该参数决定了整个平均循环的速度。如果通知大小大于数据段大小,则会在一次中断中传输多个数据段的内容,这将减少线程通信和中断处理的额外开销。
● 缓冲区大小:DMA传输的目标缓冲区整体大小。在我们的实验中,这个缓冲区固定等于通知大小的16倍。
● 触发速率:作为外部触发的信号发生器的信号重复频率。在结果表格中,我们给出的是在不填满(溢出)缓冲区的情况下可以达到的最大触发速率。
● 线程数:为了加快求和过程,我们对该任务进行并行化优化,将其分割成多个不同的软件线程。如果线程为1,则表示求和过程不使用额外线程,而是直接在主循环中直接执行。
● CPU负载:由于平均过程是用软件完成的,具体来说就是CPU进行了所有的工作。幸好现代CPU往往包含多个内核,我们实际上可以轻松地在它们之间共享工作任务。
● SSE/SSE2指令:乍一看,这些命令似乎非常适合并行化求和过程,并似乎可以在不需要任何线程编程的情况下加快软件的速度。但不幸的是,SSE命令集都是基于相同类型的数据的,而由于获取的数据是8bit宽度,而平均缓冲区是32位宽,因此在本例中无法利用该指令集进行加速。
五、效果和比较
所有的测量都是使用一个采样率高达5GS/s、垂直分辨率为8位,并且带有外部触发通道的数字化仪进行的。我们在表格中还列出了不同的程序配置以对比效果差异。
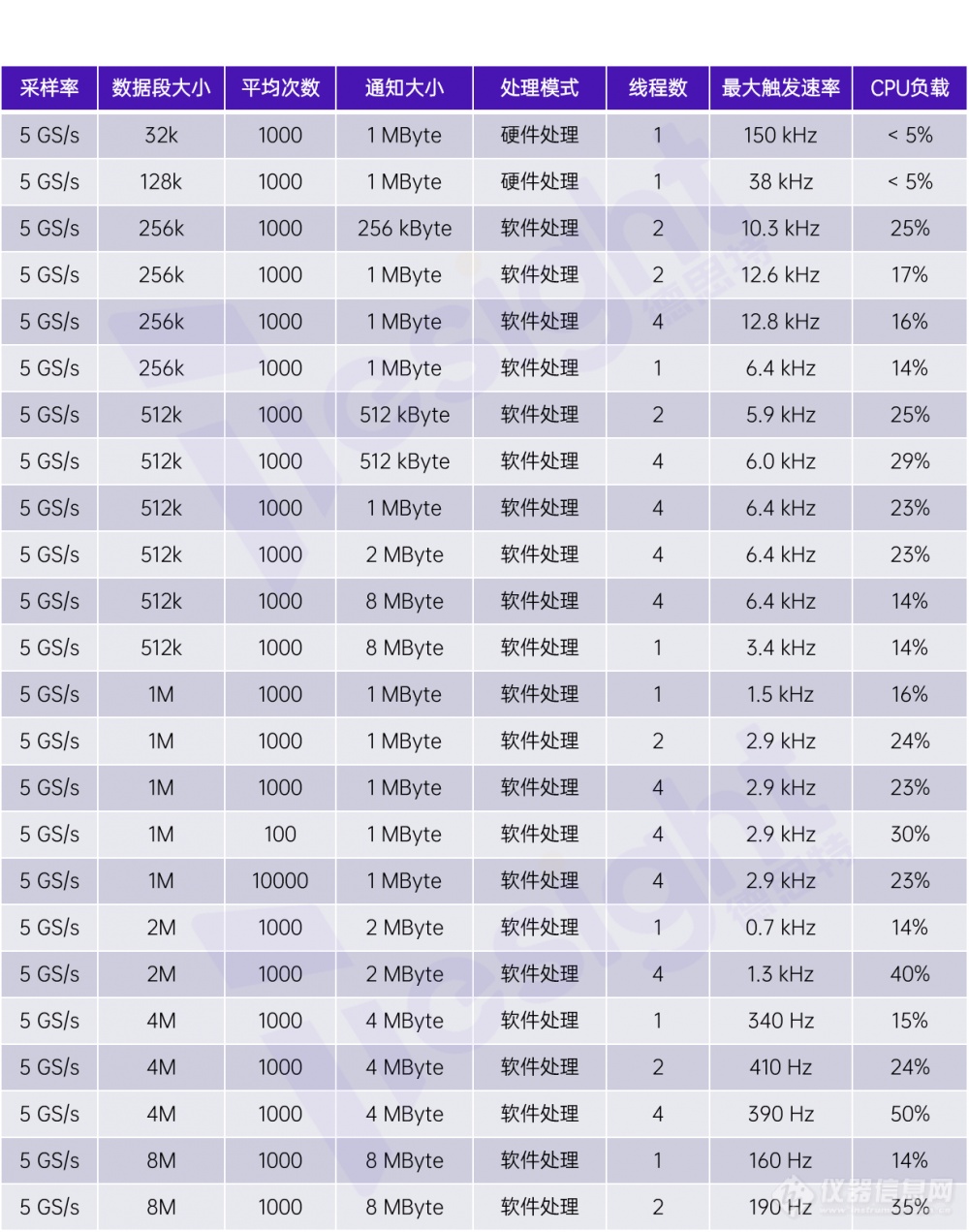
通过普通(性能偏低的)PC在时域上进行块平均的性能对比
六、新方法:使用CUDA进行平均运算
2018年11月,德思特推出了一些使用SCAPP(通过CUDA访问数据和并行处理)选项进行块平均的示例,适用于非常高速的数据处理。其基本概念与前文所述相同,即数据由数字化仪采集并通过PCIe总线连续传输。不同之处在于,平均值的计算操作不是由CPU完成,而是在GPU中完成。GPU解决方案的一个主要优点在于,GPU本身就是为并行计算而设计,这使GPU成为各种类型的块平均运算的理想选择。
在实现上,SCAPP允许用户直接将数据传送到GPU,这使用了RDMA(远程直接内存存取)技术,然后可以在GPU上执行高速时域和频域信号的平均,并突破通常在CPU和FPGA中出现的数据长度或算力限制。
比如,TS-M4i.2220数字化仪可以以2.5 GS/s的速度连续采样信号,我们可以做到在不丢失样品点的情况下,进行长达数秒的平均运算。类似地,我们还有14位垂直分辨率的TS-M4i.4451数字化仪可以以450 MS/s的速度同时对四个通道的信号进行同一功能的采样。数字化仪板卡还提供了灵活的触发、捕获和读出模式设置,从而使它们能够在触发速率极高的情况采回原始信号,进而做平均处理。相比之下,FPGA方案需要最高性能级别的FPGA来同时满足数据拉取和平均运算,而GPU方案则可以轻松跑满数字化仪的全速,即使是使用入门级GPU也不会成为瓶颈。
以下表格展示了使用GPU,并在和之前表格中板卡参数相同的情况下的测试结果:
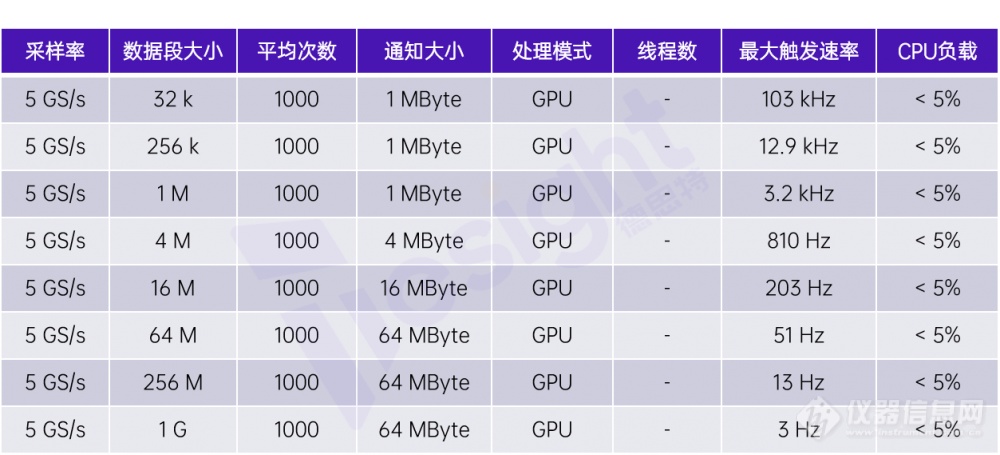
在时域上使用GPU进行块平均的测试结果
这些结果是在使用一张Quadro P2000 GPU获得的。如表所示,数据段大小和通知大小并未限制性能,我们遇到唯一限制的瓶颈是GPU内存(显存)。
七、使用GPU进行频域平均
在需要进行频域平均的情况下,也建议使用GPU,因为GPU允许比FPGA方案更大的平均块大小。频域的平均运算过程包含两个步骤,一个是针对块数据的FFT运算,另一个是对FFT结果求和(然后取平均)。其中FFT计算在处理能力方面要求非常高,因此对于频率域平均而言,除了FPGA外,GPU是唯一的可行方案,CPU并不适合在高速下进行FFT转换。
以下表格显示了使用最大采样率为500 MS/s的TS-M4i.4451数字化仪(4通道,14位垂直分辨率)的一些测试结果。最终表明该方案能高效地实现无间隙数据采集,将每个块中的原始数据转换为对应电压值,然后再转换至频率域做平均。
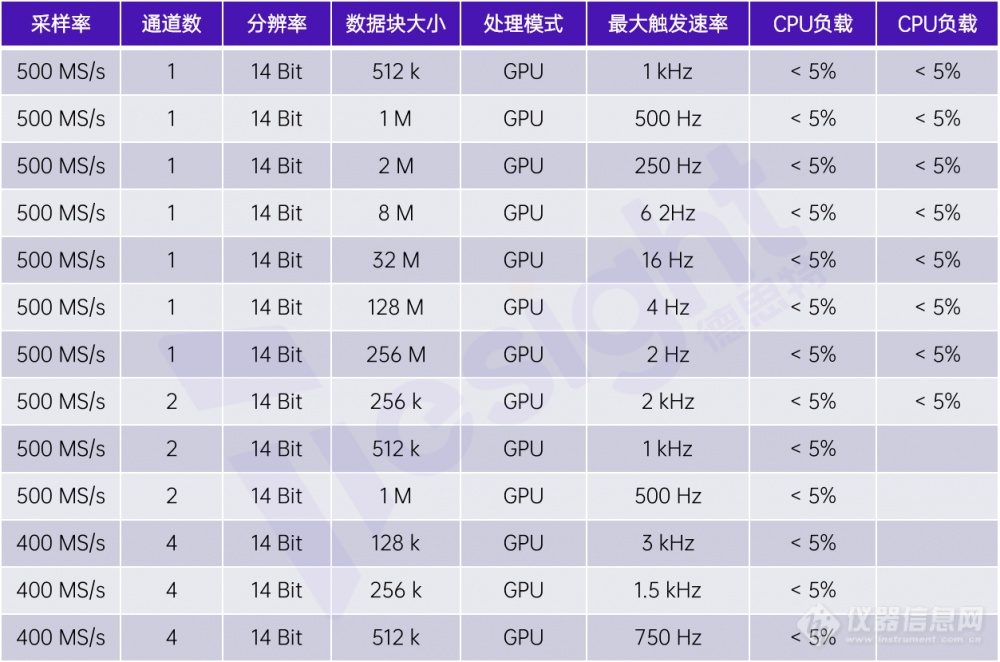
使用GPU进行频率域块平均的测试结果
八、结论
如上述结果所示,只要重复率不算太高,得益于PCIe总线的高速数据传输率,使用基于CPU的软件在进行块平均时,可以实现比FPGA更大的总数据段大小,从而平均更长时间的样本;而使用GPU时,更是可以达到PCIe总线传输所限制的上限速度。对于需要处理更高重复触发率的情况,会对总线传输速度提出更高的要求,此时基于FPGA硬件的块平均仍将是最佳选择。
上述测试程序也可以提供给您,以便您自己进行重复测试,或者作为实现其他软件程序的基础。其中GPU示例是SCAPP软件选项的一部分,在选购后,德思特的客户可按照NDA协议使用。
总的来说,通知大小设为1 MByte时,可获得最佳性能。具体执行的平均次数对测试性能并没有明显的影响。因为复制结果段和清除结果缓冲所需的时间相对于样本求和运算而言微不足道。
由于在同时采集多个通道时,整个的数据处理和求和过程并没有本质区别,因此只需等价成一个把所有数据都合并到一起的新通道即可(等效采样率= 每通道采样率 × 通道数)。以下设置对应的最大触发速率完全相同:
● 1通道5 GS/s @ 数据段大小S1
● 2通道2.5 GS/s @ 数据段大小S1/2
● 4通道1.25 GS/s @ 数据段大小S1/4
将采样速度降低到2.5 GS/s时,可以在理论上使软件针对1个通道执行平均运算的速度最大化。对于1 M样本点的数据段大小,外加死区长度为160个样本点时,理论上的最大触发速率为:(2.5 GS/s) / (1 MS+ 160 S) = 2.38 kHz。
注意,这确实会明显低于单纯采集时的最大触发速率:2.9 kHz @ 5 GS/s。
来源于:广州虹科电子科技有限公司










热门评论
最新资讯
厂商动态
新闻专题
