
[align=center][color=#ff0000][b][b]号外![/b][img]https://simg.instrument.com.cn/bbs/images/default/em09505.gif[/img]号外![b][img]https://simg.instrument.com.cn/bbs/images/default/em09505.gif[/img][/b][/b][/color][/align][align=center][b][color=#ff0000]日立多变量分析软件3D SpectAlyze免费试用活动来啦!!![/color][/b][/align][align=center]为荧光光谱、液相色谱等数据解析而特别开发![/align][align=center]申请免费试用时间:[color=#ff0000]6月1日-7月1日![/color][/align][align=center]还有各种[b][color=#000099]精美礼品拿哈![/color][/b][/align][align=center]还等什么,赶紧戳以下活动页面申请吧![/align][align=center]或点击活动链接:[url]https://www.instrument.com.cn/zt/3DSpectAlyze[/url][/align][align=center][url=https://www.instrument.com.cn/zt/3DSpectAlyze][img=,690,293]https://ng1.17img.cn/bbsfiles/images/2020/05/202005261825126372_6202_2817550_3.png!w690x293.jpg[/img][/url][/align]
求助大家有没有知道用unscramber软件做PLSR多变量图的教程
ARL,SPECTRO,OBLF内置的校准曲线也均是通过多变量回归数学模型建立的吧,如何通过多变量回归数学模型建立校准曲线?大家从数学及物理的角度谈谈对多变量回归的理解。
这是我总结中南大学梁逸曾教授的一次讲座《智能光谱分析的前景展望》的内容,和大家分享下 近红外光谱,拉曼光谱,紫外可见光谱,LIBS(激光诱导击穿光谱技术,laser induced breakdown spectroscopy),X-射线荧光谱等,都是目前光谱分析出现的新型快速无损分析的新工具。借助化学计量学,它们在复杂体系的定性定量分析及模式识别和模式分析中提供了最新的光谱分析新仪器。不同光谱反映了不同样本层次的分子信息:外可见:分子中电子跃迁能量谱;红外、拉曼与近红外:分子的振动-转动光谱;X-射线荧光谱:样本中样本中原子分布信息;LIBS:样本中元素分布信息,等 一般说来,常用的波谱(包括紫外可见、红外光谱、近红外光谱、拉曼光谱、LIBS谱、质谱和核磁共振谱)包含了样本中化学物种的结构与特征信息。不同的化学物质一般都有不同的波谱,而这些差别将为以多变量分析为基础的化学计量学提供新的机遇。智能光谱分析的新任务 1)样本的多变量定性分析 这样的例子就是不同种类的中药材(或植物物种的化学分类与鉴别)分类与真伪鉴别,天然香精香料提取物的分类与鉴别,不同疾病患者的代谢组学分析,不同土壤,不同纤维,不同烟草及卷烟等的识别。对于这些样本的分析,人们不在乎是否能对其进行穷尽的化学组分定性定量分析,而主要追求样本之间整体性(包括共同性与差异性)分析,可对不同样本进行区分并进而找到区分样本之间的主要化学因素(或特征变量,或生物化学标志物),化学计量学为此提供了相应的基于多变量的解析方法,这些方法亦将是我们主要进行讨论的复杂体系的分析方法,也为智能光谱分析提供了新思路。 2)谱学的多变量定量分析 农产品中的不同种类的粮食或烟草中的蛋白质、脂肪、糖类的总量分析,原先大都采用化学分析方法来完成,都耗时耗力;另外,人们往往不是对样本中某种化学物质的定量感兴趣,而是关注该样本的某一性质和特质,如能源化学中汽油的辛烷值(或油品标号)、食品化学中的某种感官定量指标、不同的塑料制品的鉴别等。这些也都有一些传统的方法进行测量,大都耗时耗力或主观性太强。值得提出的是,一般象这样的化学分析,其结果都是有很多因素共同形成,不是由某单个化合物决定。随着仪器分析进入实验室,大都趋向于采用既无损且简便的方法来替代原有分析方法,由于化学计量学中主成分回归(PCR)和偏最小二乘(PLS)多变量解析方法的引入,使得对这些样本的快速分析成为可能。 人们采用多变量的波谱分析(主要是近红外光谱,红外光谱、拉曼光谱、 LIBS,质谱,NMR等)来替代原先的传统分析方法,继采用PCR、PLS或其他多变量解析方法(包括支撑向量机、人工神经网络)来校正建模,以达到快速分析的结果。注意到,这类样本的分析并不只局限于对某种化合物的定性定量,它们是多种化学物质的综合效应,故其校正模型不确定(线性或非线性未知,无有类似Lambert-Beer定律作为其分析校正基础),波谱中的响应变量亦不能确定,且它还需要用原先传统化学或物理方法所得的定量数据来作为标竿建模,这类样本实质上也是一种复杂多组分体系。对此类体系的定量分析也可通过借助化学计量学进行快速定量分析,并此技术已得到了十分广泛的实际应用。……………………很多图文的例子,不一一述说,大家详细看附件的PPT吧

【仪器微课堂·第2期】过程分析技术在中药制药品质均一性评价研究与应用 2016年,仪器论坛将陪伴大家多年的线上讲座与微信直播相结合,推出【仪器微课堂】栏目!4月20日晚八点,【仪器微课堂·第2期】过程分析技术在中药制药品质均一性评价研究与应用如期举行。分享嘉宾:北京中医药大学 副研究员硕士生导师 吴志生分享形式:微信群中ppt图片+语音参与人数:357人内容整理:近红外光谱(NIR)版面版主 Rambo 吴志生老师在仪器微课堂群中进行了微信直播,主题为:过程分析技术在中药制药品质均一性评价研究与应用,网友们反应热烈,表示受益非浅。为了让更多的版友看到这期讲座,Rambo版主整理了吴志生老师的讲课内容,内容包括图片与文字,图片为吴志生老师的PPT课件,文字为吴志生老师的口述,分享给大家。大家对讲课内容有什么疑问,可在近红外光谱(NIR)版块发帖,吴志生老师会去回复。嘉宾分享环节http://ng1.17img.cn/bbsfiles/images/2016/04/201604202125_590966_2542239_3.jpg讲述: 这个题目包括了三个关键词:关键词1 过程分析技术,它的定义是“应用分析科学检测和控制工业化学过程“。但从学科来看过程控制和过程分析是分开的。 参考褚小立主编的过程分析专著;关键词2 均一性;关键词3 中药制药品质,研究对象中药生产过程而不在于种植过程和炮制过程等。http://ng1.17img.cn/bbsfiles/images/2016/04/201604202144_590968_2542239_3.jpg讲述: 这次报告围绕以上三个关键词,从研究背景、研究思路和方法应用、主要技术平台、总结四方面介绍研究工作http://ng1.17img.cn/bbsfiles/images/2016/04/201604202147_590969_2542239_3.jpg讲述: 一是政策方面,对于制药行业来说,2004年是特殊而且具有历史性的一年,这一年美国FDA发布了PAT工业指南,制药行业者开始纷纷投入这一领域。第二个政策纲领是2008年,ICH提出了质量源于设计,设计空间等理念和方法,进一步使先进过程分析和过程控制推向一个更加清晰的位置。 简单来说过程分析和过程控制,它是通过对关键质量属性和工艺指标进行实时测量,实现对产品质量设计、分析和控制的目标。制药过程分析与控制能够解决产品质量的稳定均一问题。 第二,我们国家也在政策上提出制药领域的先进过程分析技术和过程控制方法应用。在十一五和十二五期间,立了不少重大科研课题,对于这个领域起到积极推动作用。 特别是当前,在我国加速医药工业化进程,实施医药制造2025关键时期。制药行业智能制造是《中国制造2025》计划的重点领域。结合当前国际制药行业对过程质量控制新要求(PAT、QbD),“中药制药4.0”已引起中药行业和各企业的高度关注。http://ng1.17img.cn/bbsfiles/images/2016/04/201604202204_590972_2542239_3.jpg讲述: 首先,分析化学技术的飞速发展,涌现了许多分析仪器,这些仪器满足了过程分析技术要求,快速、无损、简便和可靠的特性,从技术储备上为本领域提供了支撑。 同样也使得分析化学从静态分析到快速动态分析,从破坏试样分析到无损分析,从离线分析到在线分析的发展。http://ng1.17img.cn/bbsfiles/images/2016/04/201604202209_590973_2542239_3.jpg讲述: 图片中两个人是质量的鼻祖,朱兰提出的质量三部曲影响现代质量学的研究进程,克劳士比提出零缺陷的概念,从这里,我们会问质量和品质有什么关系?质量是符合要求,而品质是高于符合要求。药品也不例外。药品质量围绕中心四个词安全、有效、稳定、均一。也就是从这个四个方面提高质量,提升品质。制药过程也是如此。http://ng1.17img.cn/bbsfiles/images/2016/04/201604202217_590974_2542239_3.jpg讲述: 围绕稳定、均一开展中药质量实时分析方面研究,围绕中药原料、生产过程、中间体、成品、工艺信息、质量信息开展研究工作,建立在线分析方法和快速分析方法。这些年,我们对一些共性检测指标,比如浓度、湿度、密度、包衣厚度、粒度等建立实时评价方法,对一些典型剂型单元环节建立实时评价方法。http://ng1.17img.cn/bbsfiles/images/2016/04/201604202222_590975_2542239_3.jpghttp://ng1.17img.cn/bbsfiles/images/2016/04/201604202223_590976_2542239_3.jpg讲述: 过程分析技术大多数是多变量分析技术,多变量分析技术需要建立多变量模型,建立多变量模型需要化学计量学,这个领域里我们给他一个研究子领域叫过程化学计量学。 在这里我分享一下,我在多变量建模方法方面一些工作: 举个例子:大家多清楚,PLS模型在领域内运用广泛,但是实际在使用过程中,很多人对于数据预处理、变量选择和潜变量选择是单独考虑。 什么意思呢?比如:数据预处理,大家是否是基于一个固定了的潜变量和变量范围的模型,来选择数据预处理方法,而这个潜变量和变量范围往往不是最终模型最优的参数。 其实,从系统科学的角度很好解释了这一点,以前是基于元素的局部优化构建模型,现在我们考虑元素和元素的关系,构建模型。 因此,我们建立的PLS模型,比原来绿色的区域模型质量更高,不单单用我们的数据,用网上开源数据也是这个结论。http://ng1.17img.cn/bbsfiles/images/2016/04/201604202236_590977_2542239_3.jpg讲述: PLS实际使用过程用RPD和RMSEP指标评价模型,对于药学工作者,按照美国药典、中国药典、药品标准标准方法建立方法的可靠性和准确性的,因此,制药行业提出过程分析技术方法验证问题,建立PLS模型,统计学β期望参数90%、95%的置信区间来建立模型方法验证,包括方法验证的准确度、精密、不确定度等指标。也探讨中药不同体系、不同样本集、不同过
[b]1. 从光谱维度观看样品[/b] [url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]的对象是样品。对样品的定义和标记,可以有千万种,例如从样品的理化属性,在光、电、磁场刺激的响应,样品的聚集形式,各类谱图,甚至人为定义的各种编码。大部分对样品的定义变成了分析化学工作者手中具体的任务,例如密度、折光率、红外、紫外、核磁和近红外等的测量。样品从一个抽象的对象实例化为具体的物质,就注定了其独一无二的属性。人以群分,物以类聚,相似的样品可能体现在相似的元素构成、分子结构、构象、晶型等上面。而分析工作者所要做的就在各种条件下,当存在各种干扰时,准确通过样品的某些属性,获取样品中组分的浓度,或者根据组分对样品进行聚类或判别。因此能够充分描述样品组分差异、获取成本低是大部分优秀的检测手段的特征。 [url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]从分子水平上为人们打开了一扇通往样品组成的窗户。[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]是样品在复色光照射下,在780-2526 nm范围内的光谱吸收曲线,包含了了大量含氢集团的信息。通常气态和液态样品采样近红外吸收光谱法,而固态或不透明膏状样品采用近红外漫反射光谱。而近红外漫反射的优势决定了只需要简单的粉碎、混匀等样品处理、甚至可以直接检测光谱。[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]的这些优势奠定了在快检领域的重要地位。[b]2. [url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]建模的基础[/b] 朗伯比尔定律是[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]分析的基础。组分浓度与光谱吸收强度在一定范围内呈线性关系。因此,理论上,[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]可以和大部单变量分析光谱一样,通过某个波长的吸收和对应官能团建立工作曲线。然而,每种含氢基团在近红外区响应并非是离散的点,而是具有一定宽度,形状介于高斯曲线和洛伦兹曲线的吸收带。近红外区丰富的信息导致了大量基团的吸收带都互相重叠,从而难以分理处每个基团纯净的吸收。相较于单变量校正,多变量校正具有两大显著优势。1)多元校正一般是对多个变量同时拟合的残差平方和的最小化。而同基团的多个变量相当于单个变量的多次量测(背景干扰在后面讨论,在此忽略),而量测噪声则相互独立,因此量测结果通过多次重复测量得到提升。2)多元校正能够对抵抗校正集中出现的部分干扰。单变量校正不能抵抗干扰组分,即使出现干扰组分,也必须要求其浓度不随样本变化,才能在工作曲线中通过截距项将其干扰抵消。而大部分分析任务很难保证所有样本的干扰组分都固定不变,而多元校正试图通过一列线性组合的系数,该系数尽可能与干扰组分光谱正交,而与目标组分光谱平行。因此即使干扰组分光谱强度有一定的变量,由于其与系数正交,最终仍然难以对校正结果产生较大影响。[b]3. [url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]分析的发展3.1高维数据分析[/b] 多变量分析(多元校正)在[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]分析中取得了很大的成功。然而在更复杂的分析任务中,干扰组分可能并不一定出现在校正集中。高维数据分析的出现大大提高了[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]解析的准确性。样本中各组分在光谱维度上的分布为深入物质内部观察打开一扇窗户,温度、PH值、电场、磁场扰动等为[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]分析打开了另一扇窗。从此,近红外分析不再是平面,而是立体的。高维数据分解通过提出样品在不同维度上唯一的轮廓实现。尽管高维数据表现出在分解中物理意义明确、解唯一、抗干扰等优势,但是在实际应用中,仍然存在不符合实际的情况。例如,外加的扰动程度不足以得到唯一的可行解。或者解析轮廓在某些扰动下存在畸变,导致数据失去线性规律。[b]3.2多种数据融合[/b] 高维数据分析是拓宽了分析的维度、而数据融合则延伸了分析的深度。所谓数据融合是将样本不同类型的量测数据同时分析的一种方法。任何一种技术都难以对物质属性进行足够充分的描述,而互补的另一种技术可能为单一数据分析带来质的飞跃。多种数据通过一种纽带(例如:浓度)连接,在数据分解上可能将原来无法区分的组分分离。进而带来更准确和稳健的分析结果。
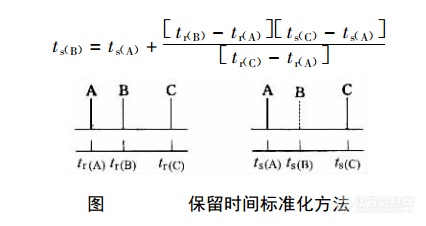
1、裂解产物的定量分析 在Py-GC发展早期,由于使用各种各样实验室自制的裂解器,所以,同一样品在不同实验室的分析数据常常有很大的偏差。这使得很多人认为Py-GC的定量分析是不可靠的。经过几十年的发展,现在Py-GC的分析重现性己今非昔比,定量分析的重现性可以达到小于3%(相对标准偏差)。裂解产物的定量分析是Py-GC研究的基本要求,也是解析谱图的原始数据。具体的定量方法与常规GC是相同的,即基于峰高或峰面积的归一化法、内标法和外标法。但这些 方法用于Py-GC时应注意如下几个问题:(1)裂解产物的良好分离是准确定量的前提。这意味着要尽可能完全地分离裂解产物,而且色谱峰形要对称。故在裂解产物的定量测定之前必须更仔细地优化色谱分离条件。(2)在定量分析时还必须对实验重复性进行评价。如果误差太大,说明仪器系统的存在条件未能严格重复。若色谱峰分离良好,那么造成重复性差的原因可能有:①样品量太大;②样品在裂解器中的位置不重复;③裂解器加热特性变化;④仪器系统被污染;⑤残留溶剂的影响。这时应逐项检查,找到问题加以解决。直到获得满意的重复性,方可进行可靠的定量分析。(3)通过裂解谱图上某一碎片峰的定量来估算样品中某一组分的含量(如测定共聚物的组成)。这时所选的特征碎片峰应该是完全分离的和峰形对称的,而且这一碎片还应是通过单分子反应得到的初级反应产物,这样才能保证所测的峰高或峰面积与样品的组成呈线性关系。在这种情况下,更要严格控制裂解条件,抑制二次反应的发生。减少样品量有利于防止二次反应。(4)正如在常规GC中那样,内标法定量的精度是最高的。在裂解样品中定量加入另一种物质,只要其裂解产物不干扰样品的裂解和色谱分离,就可用该裂解产物作为内标物,从而大大提高定量结果的可靠性。2、数据处理基本方法 数据处理是Py-GC系的最后一步,也是分析成功的关键性一步。比如作样品鉴定时,在裂解产物较少的情况下,谱图比较简单,仅凭直观就能判断两张谱图是否相同,但在大多数情况下,裂解谱图相当复杂,色谱峰多达几十甚至上百,这时仅靠直观就不能解决问题了,而必须用定量的方法来描述两张谱图的相似程度。但Py-GC还需要一些特殊的数据处理方法,特别是化学计量学的应用,如模式识别、因子分析、多元曲线和相似指数等方法可以揭示谱图间的微小差异。(1).保留时间标准化 在Py-GC中,由于色谱柱效和操作参数会逐渐有所变化,故同一裂解产物的保留时间不可能在每次分析中都严格重复。这样在计算机进行谱图自动比较时,为保证准确识别相应的色谱峰,就必须设定一个保留时间范围而不是一个特定值。解决这一问题的方法就是保留时间的标准化。 所谓保留时间标准化就是选择一些参照色谱峰对裂解产物的保留时间进行校正,这与GC中的保留指数有相似之处。所不同的是保留指数采用正构烷烃作参照峰,而Py-GC所保留值标准化则是选择谱图上的色谱峰作参照。具体方法如图所示。其中裂解产物A和C是选定的参照峰,t[sub]r[/sub]和t[sub]s[/sub]分别为组分的原始保留时间和标准化的保留时间。 [img=,426,226]http://ng1.17img.cn/bbsfiles/images/2017/12/201712151555_10_2384346_3.png!w426x226.jpg[/img] 在理想情况下,所选择的参照峰应存在与所有被比较的谱图上,且是完全分离的、峰高值较大的,容易识别的。此外,在所比较的谱图上这些参照峰的相对大小还应大致相同。如果这些条件不能满足,还可以在裂解样品中加入内标物,如脂肪酸甲酷或烃类化合物。就参照峰的个数而言,最少需要两个。(2).响应值归一化 样品量的不同会引起裂解产物色谱峰响应值的明显变化,因此,每一张裂解色谱图都应作归一化处理,以消除样品量的影响。归一化方法一般有两种,一是将谱图上每个峰的峰高或峰面积(用I[sub]i[/sub]表示)表示为总峰高或总峰面积(∑I[sub]i[/sub])的分数,即为该色谱峰的归一化值(I[sub]i[/sub][sup]n[/sup]):[img=,145,53]http://ng1.17img.cn/bbsfiles/images/2017/12/201712151555_2187_2384346_3.png!w145x53.jpg[/img]二是将每个峰的峰高或峰而积(用I[sub]i[/sub]表示)表示为谱图上最高或峰而积最大的峰(I[sub]B[/sub])百分数:[img=,154,79]http://ng1.17img.cn/bbsfiles/images/2017/12/201712151555_7492_2384346_3.png!w154x79.jpg[/img] 两种归一化值的关系为:[img=,168,46]http://ng1.17img.cn/bbsfiles/images/2017/12/201712151556_1047_2384346_3.png!w168x46.jpg[/img] 对于谱图比较来说,第一种方法给出的结果更为可靠,因为前者可以消除峰高或峰面积波动的影响,而后者仅是相对于一个瞬时测定值的归一化。对于非常相似的样品,有人还提出一种更适合的归一化方法,即假定标准谱图上7个指定参照峰的总峰面积(∑I[sub]s[/sub])与未知样品相应的色谱峰总峰面积(∑I[sub]i[/sub][sup]n[/sup])是相当的,故可用下式计算未知样品的色谱峰响应值(峰高或峰面积)的归一化值:[img=,183,71]http://ng1.17img.cn/bbsfiles/images/2017/12/201712151557_4284_2384346_3.png!w183x71.jpg[/img](3).特征峰的选择 经过归一化的裂解谱图通常包括一组选定的色谱峰,即所谓特征峰。谱图的比较就是比较特征峰,而不是比较所有的峰。在Py-GC中,特征峰是指那些同样品的化学组成和结构有着确定对应关系的碎片峰。在进行谱图比较时,应选择那些响应值大的、完全分离的、且能重现的色谱峰。对于共聚物的鉴定,只比较三个特征峰就可以了,而在鉴定微生物时则要比较多达13个峰。 经过上述数据处理后,便可对裂解谱图进行比较。比较的方法有多种,从简单的峰计数到复杂的模式识别技术,其目的就是要描述谱图间的相似程度,从而对未知样品进行分类鉴定。常用的参数有相似系数、相似值、匹配因子、T测试、多变量预计方法等。
使用基于电子鼻的质谱仪对香料进行日常质量控制关键词:化学计量学,化学传感器,电子鼻,质谱仪(MS),水果香料,区分,顶空分析,质量控制,臭味,指纹质谱图摘要:Gerstel 化学传感器4440A是将顶空自动进样器直接与四极杆质谱仪连接而成。每个样品的分析时间仅仅为3-4分钟。在进行多变量分析时,使用Infometrix’Pirouette公司的模式识别软件包对数据进行分类。 使用该仪器对几种不同的水果香料进行分类。这些香料中一般含有大量的丙二醇和乙醇作为载体。 使用这种化学传感器进行日常分析意味着考察不同香料的定性和定量的化学组成。在定性分析中,使用一种多变量分析程序-SIMCA。SIMC将香料样品的组成谱变成三维图中的一个点。从相似香料的投射在三维图中聚集成束,那些挥发性成分不同的香料的投射聚集在不同的地方。 使用PLS作定量分析。在预测模式,采用PLS运算法则比较未知香料样品和已知质量好的香料样品的质谱指纹图。化学传感器可以区分香料的指纹质谱图在组成上的差别,得出通过/失败的结论。香料分析的结果可以作为食品加工业的客观指导,如评价原料,中间和最终产品的质量。 本研究的最大目的是考察在仪器的漂移或必须的保养情况下化学计量学模型的长期稳定性。
AromaOffice2D[font=DengXian]风味物质数据库软件有来着十万条以上的参考文献的上万条化合物的保留指数和气味信息,可以进行快速方便检索。例如通过名称,[/font]CAS[font=DengXian]号码,化合物化学式,关键词等来检索不同色谱柱[/font]RI[font=DengXian]值和气味(或风味)信息,相关来源文献等。也可以同时应用保留指数([/font]RI[font=DengXian])和质谱([/font]MS[font=DengXian])来快速方便的鉴定香气香味化合物。软件可以嵌合在安捷伦的[/font]MS[font=DengXian]化学工作站或[/font]Masshunter[font=DengXian]的未知物分析上面进行质谱谱库检索和自动计算保留指数值,并对比保留指数。并可以给出化合物的香气描述。还可以进行解卷积处理。[/font][font=DengXian]香气搜索的结果可以输出为[/font]Excel[font=DengXian]格式的文件,可以使用多变量分析软件[/font]Agilent MPP[font=DengXian]([/font]Mass Profiler Professional[font=DengXian])读取,多变量分析。[/font]

http://ng1.17img.cn/bbsfiles/images/2016/02/201602151614_584417_2045325_3.jpg2016中国代谢组学暨多元变量统计分析培训班 第十期Training course of Metabolomics & MVDAin China,2016(10th)时间:2016.4.12-2016.4.19 语言:中文主办单位:Biotree中国、Umetrics瑞典培训地址:上海.中国官方网址:http://study.biotree.cn/代谢组学(Metabolomics)是继基因组学和蛋白质组学之后的最新组学技术之一,近十年来,代谢组学迅速发展并渗透到众多领域,目前在疾病诊断、病理研究、新药开发、药物毒理学、植物、营养学等与人类健康和疾病密切相关的领域有着广泛的应用,是系统生物学的重要组成部分。由中国上海阿趣生物科技有限公司(Biotree),MKS Umetrics联合主办的“第十期中国代谢组学暨多元变量统计分析培训班”将在2016年4月12日-19日于上海举行,届时我们会邀请一些国内外代谢组学领域的知名专家和教授,对代谢组学技术的发展,国际上哪些先进经验可以借鉴,国内代谢组学发展碰到的问题,如何借助代谢组学技术为科研成果转化提供有力支持等一系列现实的问题进行深入的探讨。同时我们邀请一些奋战在代谢组学一线的资深技术老师对代谢组学的样本提取、试验检测、质量控制、数据分析及处理等进行深入浅出的讲解与培训。另外,我们还邀请MKS Umetrics知名专家,对多元变量统计分析进行高阶培训。通过最新的多元变量技术,您将学习到如何更高速、自信地解释、处理复杂的数据。发现在数据中奥秘,学习如何建立可靠的预测模型,并将数据转化为决策。我们鼓励您带着您的数据参与课程教授、实体演练和实际操作,从而确保快速得到与您的需求相关和可利用的结果。代谢组学培训班内容(4月12日-13日):√基于质谱的代谢组学应用√代谢组学与药物代谢√脂质组学介绍√LC-MS在代谢组学中的应用和数据分析解析√GC-MS在代谢组学中的应用和数据分析解析√NMR在代谢组学中的应用和数据分析解析√多元变量统计分析(MVDA)解析及上机实践√层次聚类及代谢通路分析解析MVDA for Omics (4月14日-15日):√多元变量统计分析(MVDA)介绍√什么是主成分分析?√SIMCA软件演示√PCA的应用√SIMCA14软件上机实践√多元变量统计分析回归技术√判别分析的介绍√OPLS-DA,找寻Biomarker的利器√S-Plot和SUS-plot的作用√模型结果验证√上机实战√学员自带数据分析讨论MVDA for General(4月18日-19日):√多元变量统计分析(MVDA)介绍√什么是主成分分析(PCA)?√MVDA与PCA的必要性√PCA对数据表的概述,PCA的价值√SIMCA14 软件上机实践√关注OPLS√关于PLS和OPLS模型的诊断和验证√根据X变量参数预测响应变量Y√OPLS的应用以及价值√模型结果的验证√上机实战√学员自带数据分析讨论培训注册:(官网在线注册或邮箱报名:marketing@biotree.cn,报名截止日期:2016年4月10日)代谢组学培训班(4月12日-13日):(包括学费、资料费、上机费、午餐及欢迎晚宴)1.注册费:General3000元/人;Student2500元/人2.多人优惠:两人注册优惠价9折、四人及以上优惠价8折;3.本培训人数限制为100人,报满截止,不接受现场报名缴费;4.由于大班授课,座位按照注册付款先后排列,敬请谅解!多元变量统计分析培训班:(包括学费、资料费、上机费、午餐及欢迎晚宴,另外赠送一次学习巩固机会)MVDAfor Omics(4月14日-15日):9800元/人。MVDAfor General(4月18日-19日):9800元/人。1.注册截止日期为2016年4月10日,及早注册价格(2016年3月10日前到款):8800元/人2.本培训小班授课,人数限制为20人,报满截止,不接受现场报名缴费。3.温故而知新,特赠送一次复习机会,包您学会掌握(仅限本人使用)!详情可来电垂询: 021-61531195 联系人:叶老师
在上次现场评审时,评审老师说道我们检测项目,涉及痕量分析,但网上查阅,痕量分析大致意思是指待测物质中成分低于百万分之一,但是也有说是介于万分之一至百万分之一之间的,有点迷糊,还请各位老师指教一下!是否有具体出处!
究竟什么叫痕量分析,使样品浓度范围吗?如果是,那低于多少为痕量分析,如果不是,那痕量分析究竟指什么?
请问怎样划分常量分析天平、微量分析天平和半微量分析天平?
加权最小二乘法建立豆制品中游离甲醛含量分析标准曲线的研究摘要化学分析工作中,两个变量之间的关系普通采用最小二乘法建立标准曲线,如果分析测定的变量范围宽,在低浓度区域则分析结果的相对误差较大,本文主要讨论了以加权最小二乘法建立标准曲线的优越性,并以DB35/T638-2005乙酰丙酮法测豆制品中游离甲醛为应用实例,介绍了加权最小二乘法的原理、计算公式、权重因子在提高低浓度测定相对误差的作用。关键词 加权最小乘法;标准曲线;权重因子;游离甲醛Weighted Least SquaresMethod to Establish Formaldehyde Content in Bean Products Analysis of Standard CurveZheng Jin-wen (Nanping Product Quality Inspection Institute, Fujian Nanping, 353000)AbstractIn chemical analysis, therelationship between the two variables, ordinary least squares method isadopted to establish the standard curve, if the analysis determination ofvariable scope wide, in low concentration region are the results of theanalysis of relative error is larger, this paper mainly discusses with theweighted least squares method to establish the superiority of the standardcurve, and acetyl acetone method DB35/T638 free formaldehyde in bean productsas an example, this paper introduces the principle of weighted least squaresmethod, calculation formula and weighting factor in low concentration bymeasuring relative error of the function. Keywords weighted least square; Standard curve;Weighting factor; Free formaldehyde 1 前言在豆制品制品的分析工作中,对其游离甲醛的含量进行定量分析一般是采用标准曲线法进行数据处理,通过对系列浓度的甲醛标准溶液依DB35/T638-2005 进行吸光度的测定,得到吸光度(Xi)与浓度(Yi)的对应数据,再运用最小二乘法进行回归运算,得到线性回归标准曲线方程。然而,在实际工作中,由于豆制品制品中游离甲醛含量变化大,需检测的浓度范围宽,若使用最小二乘法建立的回归标准曲线,会导致低浓度所得结果的相对误差较大。为解决这一问题,本文以豆制品制品中游离甲醛分析方法为例,讨论了加权最小二乘法在建立标准曲线(线性方程)中的应用。2 实验所得的相关原始数据依DB35/T638标准对系列已知浓度的游离甲醛浓度进行吸光度的测定,所得的相关数据见表1。
重量分析法本章教学目的:1、了解沉淀中沉淀式和称量式的概念。2、明确沉淀剂选择的条件。3、掌握沉淀形成的条件。教学重点与难点:沉淀的条件教学内容: 一、重量分析法原理什么是重量分析法?重量分析法(gravimetric analysis):根据反应生成物的质量来测定欲测组分含量的定量分析方法。分类如下: 沉淀重量法分类 气化法电解分析法 热重量分析本章重点讲解讨论沉淀重量法和气化法。1、沉淀重量法(precipitation method):利用沉淀反应,加过量沉淀剂于试样溶液中,使被测组分定量地形成难溶的沉淀于试样溶液中,经过滤、洗涤、烘干或灼烧、称量,根据称得的重量计算出被测组分的含量。溶解 BaCl2沉淀剂 过滤、洗涤、烘干或灼烧例如:测定试液中硫酸根离子含量:试样 试液 BaSO4 称量BaSO4恒重 计算百分含量Fe3+ → Fe(OH)3 → Fe2O3
[font=宋体][url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]的定量建模目标是连续变量,例如,某化学组分的浓度或可连续取值的理化性质。根据《多元分子光谱校正定量分系统则》[/font][font='Times New Roman']GB/T 29858-2013[/font][font=宋体][font=宋体],定量分析建模过程主要包括:样本选择、可行性模型的建立、奇异样本剔除、光谱预处理、波长选择和多元校正建模等,如图[/font][font=Times New Roman]5-12[/font][font=宋体]所示。[/font][/font][align=center][img=,419,252]https://ng1.17img.cn/bbsfiles/images/2024/06/202406281011086827_3238_4070220_3.png!w690x414.jpg[/img][font='Times New Roman'] [/font][/align][align=center][font=宋体][font=宋体]图[/font][font=Times New Roman]5-12 [/font][font=宋体]建立定量校正模型与预测分析的流程示意图[/font][/font][/align][b][font=宋体]一、样品的选择[/font][/b][font=宋体]样本的选择应遵循代表性和均匀覆盖的原则。校正集中的样本应包含使用该模型预测的待测样本中可能存在的所有化学成分,且校正集的化学成分浓度范围应涵盖使用该模型预测的待测样本中可能遇到的浓度范围,以保证待测样本的预测是通过模型内插进行分析的;校正集浓度或性质范围最好还应大于或等于参考方法的再现性标准偏差,即再现性除以[/font][font='Times New Roman']2.77[/font][font=宋体]大小的[/font][font='Times New Roman']5[/font][font=宋体]倍,至少不低于[/font][font='Times New Roman']3[/font][font=宋体]倍。在整个变化范围内,校正集中样本的化学成分浓度是均匀分布的;校正集中的样本数量应足够多,以能统计确定光谱变量与校正成分浓度或性质之间的关系。[/font][font=宋体]根据待测样本的复杂性,确定建立校正模型所需样本数量。如待测样本含有较少的浓度变化成分,则存在的光谱变量数较少,使用相对数量较少的校正样本便可确定光谱与样本成分浓度或性质之间的关系。如待测样本含有较多的浓度变化成分,则需较多的校正样本建立校正模型。对复杂的混合物,获得理想的校正集非常困难。只有通过建立模型初步确定模型所需光谱变量,才能确定校正样本数量是否足够。对于应用多元校正方法建模,如果使用[/font][font='Times New Roman']3[/font][font=宋体]个或更少的因子数[/font][i][font='Times New Roman']k[/font][/i][font='Times New Roman'][font=宋体](又名隐变量数、或潜变量数)[/font][/font][font=宋体]建立校正模型,剔除奇异样本后校正集应至少含有[/font][font='Times New Roman']24[/font][font=宋体]个样本;如果使用大于[/font][font='Times New Roman']3[/font][font=宋体]的变量数[/font][i][font='Times New Roman']k[/font][/i][font=宋体]建立校正模型,剔除异常样本后校正集应至少含有[/font][font='Times New Roman']6[/font][i][font='Times New Roman']k[/font][/i][font=宋体]个样本,如果建模数据进行了均值中心化预处理,剔除异常样本后校正集应至少含有[/font][font='Times New Roman']6([/font][i][font='Times New Roman']k[/font][/i][font='Times New Roman']+1)[/font][font=宋体]个样本,这样,才能够保证模型中含有至少[/font][font='Times New Roman']20[/font][font=宋体]个自由度以进行统计检验,同时保证有足够的样本数量确定光谱变量与校正成分浓度或性质之间的关系。上述样本数量要求仅为满足统计学的最低要求,实际中应根据影响建模影响因素(如环境温湿变化等)和可行性分析,探索确定合适的样本数量。[/font][font=宋体]验证集中的样本应包含使用模型分析的待测样本中可能存在的所有化学组成和浓度范围。在整个变化范围内,验证集中样本的化学成分浓度是均匀分布的。验证集中的样本数量应足够多,以便能统计确定光谱变量与待校正的成分浓度或性质之间的关系。对复杂的混合物,获得一个理想的验证集非常困难。验证集中的样本数量取决于模型的复杂性。如待测样本含有较少浓度变化的成分,则光谱变量较少,使用数量较少的验证样本便可确定光谱与浓度或性质之间的关系。如待测样本含有较多浓度变化的成分,验证模型时需较多数量的验证样本。在验证过程中最好使用能通过模型内插进行分析的样本。如果模型使用了[/font][font='Times New Roman']5[/font][font=宋体]个或更少的潜变量([/font][i][font='Times New Roman']k[/font][/i][font=宋体]),内插样本数不能少于[/font][font='Times New Roman']20[/font][font=宋体];如果模型使用了大于[/font][font='Times New Roman']5[/font][font=宋体]的潜变量,则验证集中的内插样本数应不少于[/font][font='Times New Roman']4[/font][i][font='Times New Roman']k[/font][/i][font=宋体],请读者参阅[/font][font='Times New Roman']GB/T 29858-2013[font=宋体]。[/font][/font][font=宋体]此外,根据参考值范围内样本分布的概率密度对样本加权也是一种有效的方法,以保证建立一个在整个参考值范围内都有效的模型。[/font][b][font=宋体]二、可行性模型的建立[/font][/b][font=宋体]对于一个新的应用领域,当不能确定能否利用[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]建立多元校正模型时,应进行可行性研究,以确定样本[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]与其成分浓度或性质间是否存在相关关系,是否能够建立满足实际需求的模型。若可行,则扩充完善模型并验证模型。请读者可参阅[/font][font='Times New Roman']GB/T 29858-2013[font=宋体]。[/font][/font][b][font=宋体]三、光谱预处理[/font][/b][font=宋体][font=宋体]为消除光谱测量过程中引入的噪声等无关信号对模型的不利影响,宜在模型建立前采用光谱预处理方法对光谱数据进行预处理。常用光谱预处理方法包括背景扣除、散射校正、噪声去除和尺度缩放四大类。每类预处理也包含很多种算法,具体内容在本章[/font][font=Times New Roman]5.4[/font][font=宋体]节有详细介绍。[/font][/font][font=宋体][font=宋体]如何从众多的光谱预处理方法中选择合适的预处理方法是个难点。预处理方法的选择一般通过两种途径:一种是观察法([/font][font=Times New Roman]Visual Inspection[/font][font=宋体]),即观察光谱信号特点选择相应的预处理方法;另一种途径是根据建模性能的优劣反过来选择预处理方法([/font][font=Times New Roman]Trial-and-error Strategy[/font][font=宋体])。不仅单一的预处理方法可以使用,组合预处理以及集成预处理方法都可以使用。[/font][/font][font=宋体]如果利用预处理后的光谱数据建立的模型在校正、交互验证和外部验证时效果接近,且接近参考方法的准确率,则预处理方法可行,否则,可尝试其他预处理方法或者方法组合。[/font][b][font=宋体]四、波长选择[/font][/b][font=宋体][font=宋体]对校正集原始光谱数据或预处理后光谱数据进行统计分析,选择随成分含量变化而变化明显的波长或频率来建立模型要比采用全波长范围建立的模型效果更好。在建立校正模型之前,宜采用波长选择方法选择校正所需的波长。波长选择方法众多,具体算法在本章[/font][font=Times New Roman]5.5[/font][font=宋体]节有详细介绍。根据保留波长数、变量分布以及性能提高程度来选择合适研究体系的波长选择方法。[/font][/font][b][font=宋体]五、校正模型的建立[/font][/b][font=宋体]对于确定能利用[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]多元校正方法的应用领域,可直接建立能符合实际需求的校正模型。收集足够数量的样本,采集样本光谱,测定样本成分浓度或性质参考值。测定参考值前,需要采用奇异样本识别方法剔除奇异样本或极为相近的样本,以避免不必要的参考值测定,降低参考值测定成本。[/font][font=宋体][font=宋体]选择合适的校正样本和验证样本分别组成校正集和验证集。根据待分析体系的复杂程度和化学计量学可提供的多元校正算法,选择合适的算法。多元校正算法包括[/font][font=Times New Roman]5.7[/font][font=宋体]部分讲到的多元线性回归([/font][/font][font='Times New Roman']MLR[font=宋体])[/font][/font][font=宋体]、主成分回归([/font][font='Times New Roman'][url=https://insevent.instrument.com.cn/t/jp][color=#3333ff]PCR[/color][/url][font=宋体])[/font][/font][font=宋体]、偏最小二乘回归([/font][font='Times New Roman']PLS[font=宋体])、人工神经网络([/font][/font][font=宋体][font=Times New Roman]ANN[/font][/font][font='Times New Roman'][font=宋体])、支持向量回归([/font][/font][font=宋体][font=Times New Roman]SVR[/font][/font][font='Times New Roman'][font=宋体])、极限学习机([/font][/font][font=宋体][font=Times New Roman]ELM[/font][/font][font='Times New Roman'][font=宋体])和深度学习算法([/font][/font][font=宋体][font=Times New Roman]DL[/font][/font][font='Times New Roman'][font=宋体])[/font][/font][font=宋体]。[/font][font=宋体]选择合适的数据预处理方法对数据进行预处理,选择合适的建模波长或波段,建立校正模型。处理校正集光谱、验证集光谱及待测样本光谱时应采用相同的光谱预处理方法和波长选择方法。利用验证集对校正模型进行验证,如果校正模型有效且模型的预测能力满足实际需求,则模型建立完毕;如果模型预测能力不能满足实际需求或模型有效性可疑,则检查模型建立中的每个步骤,选择其他算法或建模条件,重新建立模型,直至模型符合要求。[/font][b][font=宋体]六、定量模型性能的评价[/font][/b][font=宋体]多元校正模型的预测效果需要经过对样本进行预测来评价。对校正集中的样本进行预测,评价模型的自测能力。对验证集的样本进行预测,评价模型的外部预测能力。[/font][font=宋体]评价多元校正模型预测准确度的指标包括:交叉验证均方根误差[/font][font='Times New Roman'][font=宋体]([/font][/font][font=宋体][font=Times New Roman]R[/font][/font][font='Times New Roman']oot mean square error[/font][font=宋体] [font=Times New Roman]of cross validation[/font][/font][font='Times New Roman'], RMSE[/font][font=宋体][font=Times New Roman]CV[/font][/font][font='Times New Roman'][font=宋体])、预测均方根误差([/font][/font][font=宋体][font=Times New Roman]R[/font][/font][font='Times New Roman']oot mean square error[/font][font=宋体] [font=Times New Roman]of prediction[/font][/font][font='Times New Roman'], RMSE[/font][font=宋体][font=Times New Roman]P[/font][/font][font='Times New Roman'][font=宋体])[/font][/font][font=宋体]、校正集相关系数[/font][font='Times New Roman'][font=宋体]([/font][/font][font=宋体][font=Times New Roman]Correlation [/font][/font][font='Times New Roman']coefficient[/font][font=宋体] [font=Times New Roman]of calibration, R[/font][/font][sub][font='Times New Roman']c[/font][/sub][font='Times New Roman'][font=宋体])、预测集[/font][/font][font=宋体]相关系数[/font][font='Times New Roman'][font=宋体]([/font][/font][font=宋体][font=Times New Roman]Correlation [/font][/font][font='Times New Roman']coefficient[/font][font=宋体] [font=Times New Roman]of [/font][/font][font='Times New Roman']prediction[/font][font=宋体][font=Times New Roman], R[/font][/font][sub][font='Times New Roman']p[/font][/sub][font=宋体][font=宋体])、剩余预测偏差([/font][font=Times New Roman]T[/font][/font][font='Times New Roman']he ratio of the standard error of prediction to the standard deviation of thereference values[/font][font=宋体][font=Times New Roman],[/font][/font][font='Times New Roman'] RPD[font=宋体])[/font][/font][font=宋体][font=宋体]。其中,均方根误差越小([/font][font=Times New Roman]RMSECV/RMSEP[/font][font=宋体])、相关系数([/font][font=Times New Roman]Rc/Rp[/font][font=宋体])和[/font][font=Times New Roman]RPD[/font][font=宋体]越高,表明模型预测能力越好。[/font][/font][font=宋体][font=宋体]多元校正模型还容易存在过拟合和欠拟合的问题。过拟合是对校正集自身的样本预测效果很好,但是对外部样本预测效果很差。欠拟合则反之。通过对比校正集的[/font][font=Times New Roman]RMSECV[/font][font=宋体]、[/font][font=Times New Roman]Rc[/font][font=宋体]与预测集的[/font][font=Times New Roman]RMSEP[/font][font=宋体]、[/font][font=Times New Roman]Rp[/font][font=宋体]的差异程度,可以判断模型是否过拟合。[/font][/font][font=宋体][font=宋体]多元校正模型还存在稳定性的问题。模型稳定性通常将模型运行多次,计算多次建模得到的均方根误差、相关系数、[/font][font=Times New Roman]RPD[/font][font=宋体]等指标的均值以及方差。这些参数的方差越大,说明多元校正模型的稳定性越差。[/font][/font][font=宋体][font=宋体]直接作图显示模型的预测能力也是常用的模型评价方法。以目标分析物的实际测量值为横坐标,以模型的预测值为纵坐标,画散点,然后再进行线性集合。如果模型能够[/font][font=Times New Roman]100%[/font][font=宋体]地准确预测待测样本,拟合结果应该是[/font][font=Times New Roman]y=x[/font][font=宋体]的对角线,相关系数为[/font][font=Times New Roman]1[/font][font=宋体]。因此,根据散点分布情况以及拟合线的斜率、截距、相关系数等来评价模型的预测能力。[/font][/font][b][font=宋体]七、问题与回答[/font][/b]
微量天平大家都知道,但是市场上出现半微量天平,半微量分析天平与微量分析天平的区别是什么呢?
[b]质量分析[/b][font=&]其作用是将电离室中生成的离子按质荷比(m/z)大小分开,进行质谱检测。常见质量分析器有:[/font][b]四极质量分析器(quadrupoleanalyzer)[/b][font=&]原理:由四根平行圆柱形电极组成,电极分为两组,分别加上直流电压和一定频率的交流电压。样品离子沿电极间轴向进入电场后,在极性相反的电极间振荡,只有质荷比在某个范围的离子才能通过四极杆,到达检测器,其余离子因振幅过大与电极碰撞,放电中和后被抽走。因此,改变电压或频率,可使不同质荷比的离子依次到达检测器,被分离检测。[/font][b]扇形质量分析器[/b][font=&]磁式扇形质量分析器(magnetic-sector massanalyzer)被电场加速的离子进入磁场后,运动轨道弯曲了,离子轨道偏转可用公式表示:当H,V一定时,只有某一质荷比的离子能通过狭缝到达检测器。[/font][font=&]特点:分辨率低,对质量同、能量不同的离子分辨较困难。[/font][b]双聚焦质量分析器[/b][font=&](double-focusing massassay)由一个静电分析器和一个磁分析器组成,静电分析器允许有某个能量的离子通过,并按不同能量聚焦,先后进入磁分析器,经过两次聚焦,大大提高了分辨率。[/font]

坛里的高僧,给分析下,为什么半定量分析结果与定量分析结果差别会这么大???说好的在30%内。备注:STD---1ppb调谐液(含锂、钴、铟、铀)1、2、4批取0.1g消解后稀释至100ml检测,第3批料液为水溶液,直接进样了。http://ng1.17img.cn/bbsfiles/images/2016/08/201608032051_603285_3124053_3.pnghttp://ng1.17img.cn/bbsfiles/images/2016/08/201608032051_603286_3124053_3.png
从原理上讲,原子发射光谱可以进行定性分析、半定量分析和定量分析。过去因为电弧光源和火花光源在性能上存在缺陷,使发射光谱在定性和半定量分析方面应用非常广泛,但其定量分析受到很大限制。ICP光源的出现彻底改变了这种状况,使发射光谱定量分析的应用越来越多,现已基本上成为元素分析的常规手段。但大家在用ICP进行定量分析的同时,还经常去做定性和半定量分析吗?
[font=宋体][url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]的定量建模目标是连续变量,例如,某化学组分的浓度或可连续取值的理化性质。根据《多元分子光谱校正定量分系统则》[/font][font='Times New Roman']GB/T 29858-2013[/font][font=宋体][font=宋体],定量分析建模过程主要包括:样本选择、可行性模型的建立、奇异样本剔除、光谱预处理、波长选择和多元校正建模等,如图[/font][font=Times New Roman]5-12[/font][font=宋体]所示。[/font][/font][align=center][img=,419,252]https://ng1.17img.cn/bbsfiles/images/2024/06/202406261003597901_4086_4070220_3.png!w690x414.jpg[/img][font='Times New Roman'] [/font][/align][align=center][font=宋体][font=宋体]图[/font][font=Times New Roman]5-12 [/font][font=宋体]建立定量校正模型与预测分析的流程示意图[/font][/font][/align][b][font=宋体]一、样品的选择[/font][/b][font=宋体]样本的选择应遵循代表性和均匀覆盖的原则。校正集中的样本应包含使用该模型预测的待测样本中可能存在的所有化学成分,且校正集的化学成分浓度范围应涵盖使用该模型预测的待测样本中可能遇到的浓度范围,以保证待测样本的预测是通过模型内插进行分析的;校正集浓度或性质范围最好还应大于或等于参考方法的再现性标准偏差,即再现性除以[/font][font='Times New Roman']2.77[/font][font=宋体]大小的[/font][font='Times New Roman']5[/font][font=宋体]倍,至少不低于[/font][font='Times New Roman']3[/font][font=宋体]倍。在整个变化范围内,校正集中样本的化学成分浓度是均匀分布的;校正集中的样本数量应足够多,以能统计确定光谱变量与校正成分浓度或性质之间的关系。[/font][font=宋体]根据待测样本的复杂性,确定建立校正模型所需样本数量。如待测样本含有较少的浓度变化成分,则存在的光谱变量数较少,使用相对数量较少的校正样本便可确定光谱与样本成分浓度或性质之间的关系。如待测样本含有较多的浓度变化成分,则需较多的校正样本建立校正模型。对复杂的混合物,获得理想的校正集非常困难。只有通过建立模型初步确定模型所需光谱变量,才能确定校正样本数量是否足够。对于应用多元校正方法建模,如果使用[/font][font='Times New Roman']3[/font][font=宋体]个或更少的因子数[/font][i][font='Times New Roman']k[/font][/i][font='Times New Roman'][font=宋体](又名隐变量数、或潜变量数)[/font][/font][font=宋体]建立校正模型,剔除奇异样本后校正集应至少含有[/font][font='Times New Roman']24[/font][font=宋体]个样本;如果使用大于[/font][font='Times New Roman']3[/font][font=宋体]的变量数[/font][i][font='Times New Roman']k[/font][/i][font=宋体]建立校正模型,剔除异常样本后校正集应至少含有[/font][font='Times New Roman']6[/font][i][font='Times New Roman']k[/font][/i][font=宋体]个样本,如果建模数据进行了均值中心化预处理,剔除异常样本后校正集应至少含有[/font][font='Times New Roman']6([/font][i][font='Times New Roman']k[/font][/i][font='Times New Roman']+1)[/font][font=宋体]个样本,这样,才能够保证模型中含有至少[/font][font='Times New Roman']20[/font][font=宋体]个自由度以进行统计检验,同时保证有足够的样本数量确定光谱变量与校正成分浓度或性质之间的关系。上述样本数量要求仅为满足统计学的最低要求,实际中应根据影响建模影响因素(如环境温湿变化等)和可行性分析,探索确定合适的样本数量。[/font][font=宋体]验证集中的样本应包含使用模型分析的待测样本中可能存在的所有化学组成和浓度范围。在整个变化范围内,验证集中样本的化学成分浓度是均匀分布的。验证集中的样本数量应足够多,以便能统计确定光谱变量与待校正的成分浓度或性质之间的关系。对复杂的混合物,获得一个理想的验证集非常困难。验证集中的样本数量取决于模型的复杂性。如待测样本含有较少浓度变化的成分,则光谱变量较少,使用数量较少的验证样本便可确定光谱与浓度或性质之间的关系。如待测样本含有较多浓度变化的成分,验证模型时需较多数量的验证样本。在验证过程中最好使用能通过模型内插进行分析的样本。如果模型使用了[/font][font='Times New Roman']5[/font][font=宋体]个或更少的潜变量([/font][i][font='Times New Roman']k[/font][/i][font=宋体]),内插样本数不能少于[/font][font='Times New Roman']20[/font][font=宋体];如果模型使用了大于[/font][font='Times New Roman']5[/font][font=宋体]的潜变量,则验证集中的内插样本数应不少于[/font][font='Times New Roman']4[/font][i][font='Times New Roman']k[/font][/i][font=宋体],请读者参阅[/font][font='Times New Roman']GB/T 29858-2013[font=宋体]。[/font][/font][font=宋体]此外,根据参考值范围内样本分布的概率密度对样本加权也是一种有效的方法,以保证建立一个在整个参考值范围内都有效的模型。[/font][b][font=宋体]二、可行性模型的建立[/font][/b][font=宋体]对于一个新的应用领域,当不能确定能否利用[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]建立多元校正模型时,应进行可行性研究,以确定样本[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]与其成分浓度或性质间是否存在相关关系,是否能够建立满足实际需求的模型。若可行,则扩充完善模型并验证模型。请读者可参阅[/font][font='Times New Roman']GB/T 29858-2013[font=宋体]。[/font][/font][b][font=宋体]三、光谱预处理[/font][/b][font=宋体][font=宋体]为消除光谱测量过程中引入的噪声等无关信号对模型的不利影响,宜在模型建立前采用光谱预处理方法对光谱数据进行预处理。常用光谱预处理方法包括背景扣除、散射校正、噪声去除和尺度缩放四大类。每类预处理也包含很多种算法,具体内容在本章[/font][font=Times New Roman]5.4[/font][font=宋体]节有详细介绍。[/font][/font][font=宋体][font=宋体]如何从众多的光谱预处理方法中选择合适的预处理方法是个难点。预处理方法的选择一般通过两种途径:一种是观察法([/font][font=Times New Roman]Visual Inspection[/font][font=宋体]),即观察光谱信号特点选择相应的预处理方法;另一种途径是根据建模性能的优劣反过来选择预处理方法([/font][font=Times New Roman]Trial-and-error Strategy[/font][font=宋体])。不仅单一的预处理方法可以使用,组合预处理以及集成预处理方法都可以使用。[/font][/font][font=宋体]如果利用预处理后的光谱数据建立的模型在校正、交互验证和外部验证时效果接近,且接近参考方法的准确率,则预处理方法可行,否则,可尝试其他预处理方法或者方法组合。[/font][b][font=宋体]四、波长选择[/font][/b][font=宋体][font=宋体]对校正集原始光谱数据或预处理后光谱数据进行统计分析,选择随成分含量变化而变化明显的波长或频率来建立模型要比采用全波长范围建立的模型效果更好。在建立校正模型之前,宜采用波长选择方法选择校正所需的波长。波长选择方法众多,具体算法在本章[/font][font=Times New Roman]5.5[/font][font=宋体]节有详细介绍。根据保留波长数、变量分布以及性能提高程度来选择合适研究体系的波长选择方法。[/font][/font][b][font=宋体]五、校正模型的建立[/font][/b][font=宋体]对于确定能利用[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]多元校正方法的应用领域,可直接建立能符合实际需求的校正模型。收集足够数量的样本,采集样本光谱,测定样本成分浓度或性质参考值。测定参考值前,需要采用奇异样本识别方法剔除奇异样本或极为相近的样本,以避免不必要的参考值测定,降低参考值测定成本。[/font][font=宋体][font=宋体]选择合适的校正样本和验证样本分别组成校正集和验证集。根据待分析体系的复杂程度和化学计量学可提供的多元校正算法,选择合适的算法。多元校正算法包括[/font][font=Times New Roman]5.7[/font][font=宋体]部分讲到的多元线性回归([/font][/font][font='Times New Roman']MLR[font=宋体])[/font][/font][font=宋体]、主成分回归([/font][font='Times New Roman'][url=https://insevent.instrument.com.cn/t/jp][color=#3333ff]PCR[/color][/url][font=宋体])[/font][/font][font=宋体]、偏最小二乘回归([/font][font='Times New Roman']PLS[font=宋体])、人工神经网络([/font][/font][font=宋体][font=Times New Roman]ANN[/font][/font][font='Times New Roman'][font=宋体])、支持向量回归([/font][/font][font=宋体][font=Times New Roman]SVR[/font][/font][font='Times New Roman'][font=宋体])、极限学习机([/font][/font][font=宋体][font=Times New Roman]ELM[/font][/font][font='Times New Roman'][font=宋体])和深度学习算法([/font][/font][font=宋体][font=Times New Roman]DL[/font][/font][font='Times New Roman'][font=宋体])[/font][/font][font=宋体]。[/font][font=宋体]选择合适的数据预处理方法对数据进行预处理,选择合适的建模波长或波段,建立校正模型。处理校正集光谱、验证集光谱及待测样本光谱时应采用相同的光谱预处理方法和波长选择方法。利用验证集对校正模型进行验证,如果校正模型有效且模型的预测能力满足实际需求,则模型建立完毕;如果模型预测能力不能满足实际需求或模型有效性可疑,则检查模型建立中的每个步骤,选择其他算法或建模条件,重新建立模型,直至模型符合要求。[/font][b][font=宋体]六、定量模型性能的评价[/font][/b][font=宋体]多元校正模型的预测效果需要经过对样本进行预测来评价。对校正集中的样本进行预测,评价模型的自测能力。对验证集的样本进行预测,评价模型的外部预测能力。[/font][font=宋体]评价多元校正模型预测准确度的指标包括:交叉验证均方根误差[/font][font='Times New Roman'][font=宋体]([/font][/font][font=宋体][font=Times New Roman]R[/font][/font][font='Times New Roman']oot mean square error[/font][font=宋体] [font=Times New Roman]of cross validation[/font][/font][font='Times New Roman'], RMSE[/font][font=宋体][font=Times New Roman]CV[/font][/font][font='Times New Roman'][font=宋体])、预测均方根误差([/font][/font][font=宋体][font=Times New Roman]R[/font][/font][font='Times New Roman']oot mean square error[/font][font=宋体] [font=Times New Roman]of prediction[/font][/font][font='Times New Roman'], RMSE[/font][font=宋体][font=Times New Roman]P[/font][/font][font='Times New Roman'][font=宋体])[/font][/font][font=宋体]、校正集相关系数[/font][font='Times New Roman'][font=宋体]([/font][/font][font=宋体][font=Times New Roman]Correlation [/font][/font][font='Times New Roman']coefficient[/font][font=宋体] [font=Times New Roman]of calibration, R[/font][/font][sub][font='Times New Roman']c[/font][/sub][font='Times New Roman'][font=宋体])、预测集[/font][/font][font=宋体]相关系数[/font][font='Times New Roman'][font=宋体]([/font][/font][font=宋体][font=Times New Roman]Correlation [/font][/font][font='Times New Roman']coefficient[/font][font=宋体] [font=Times New Roman]of [/font][/font][font='Times New Roman']prediction[/font][font=宋体][font=Times New Roman], R[/font][/font][sub][font='Times New Roman']p[/font][/sub][font=宋体][font=宋体])、剩余预测偏差([/font][font=Times New Roman]T[/font][/font][font='Times New Roman']he ratio of the standard error of prediction to the standard deviation of thereference values[/font][font=宋体][font=Times New Roman],[/font][/font][font='Times New Roman'] RPD[font=宋体])[/font][/font][font=宋体][font=宋体]。其中,均方根误差越小([/font][font=Times New Roman]RMSECV/RMSEP[/font][font=宋体])、相关系数([/font][font=Times New Roman]Rc/Rp[/font][font=宋体])和[/font][font=Times New Roman]RPD[/font][font=宋体]越高,表明模型预测能力越好。[/font][/font][font=宋体][font=宋体]多元校正模型还容易存在过拟合和欠拟合的问题。过拟合是对校正集自身的样本预测效果很好,但是对外部样本预测效果很差。欠拟合则反之。通过对比校正集的[/font][font=Times New Roman]RMSECV[/font][font=宋体]、[/font][font=Times New Roman]Rc[/font][font=宋体]与预测集的[/font][font=Times New Roman]RMSEP[/font][font=宋体]、[/font][font=Times New Roman]Rp[/font][font=宋体]的差异程度,可以判断模型是否过拟合。[/font][/font][font=宋体][font=宋体]多元校正模型还存在稳定性的问题。模型稳定性通常将模型运行多次,计算多次建模得到的均方根误差、相关系数、[/font][font=Times New Roman]RPD[/font][font=宋体]等指标的均值以及方差。这些参数的方差越大,说明多元校正模型的稳定性越差。[/font][/font][font=宋体][font=宋体]直接作图显示模型的预测能力也是常用的模型评价方法。以目标分析物的实际测量值为横坐标,以模型的预测值为纵坐标,画散点,然后再进行线性集合。如果模型能够[/font][font=Times New Roman]100%[/font][font=宋体]地准确预测待测样本,拟合结果应该是[/font][font=Times New Roman]y=x[/font][font=宋体]的对角线,相关系数为[/font][font=Times New Roman]1[/font][font=宋体]。因此,根据散点分布情况以及拟合线的斜率、截距、相关系数等来评价模型的预测能力。[/font][/font]
我现在要做红外定量分析.请问,定量分析的标准曲线应如何制备?我已经配置好标准溶液了,但它的量应如何控制?
质量分析器系统由各种不同类型的电磁场组合而成,具有一定能量并聚焦良好的离子束经质量分析器后,可按质荷比的大小而分开。根据离子束的特点和分析工作的要求,质量分析器系统应具有足够的离子传输效率和分辨本领。通常,这两者是相互矛盾的。完善质量分析器离子光学系统的设计,就是要保证足够分辨本领的条件下,达到最高的离子传输效率。目前,设计良好的质量分析器系统的离子传输效率已接近100%。
磁式质量分析器又称单聚焦质量分析器,具有结构简单、操作方便等特点,见图1。由于磁式质量分析器只做方向聚焦,故分辨能力较低。在电动力学里,运动的带电粒子会受到磁场的作用力,这个力又叫作洛伦兹力。洛伦兹力定律是一个基本公理,不是从别的理论推导出来的定律,而是由多次重复完成的实验所得到的同样的结果。假设初始速度为0质量为m、电荷为z的离子,在加速电压U作用下,进入磁场强度为B的磁场内,会受到磁场力的作用发生偏转。在加速电压的作用下,离子在进入磁场时的瞬时速度v为: D=(2Uz/m)[sup]1/2[/sup]在磁场中受到与运动方向垂直的磁场力的作用发生偏离,离子运动轨道变成圆周运动,即 mu[sup]2[/sup]/r=Bzv合并两式,质荷比m/z等于: m/z=r[sup]2[/sup]B[sup]2[/sup]/2U式中,r为偏转轨道半径;m是原子量单位;z是离子的电荷量。该方程式为磁式质谱的基本方程。从方程式可知偏转轨道半径r为:r=(1/B)(2Um/z)[sup]1/2[/sup]从该式可知,只要改变加速电压U和磁场强度B的数值,就可使不同质荷比(m/z)的离子运动轨道半径相同。这就是磁式质量分析器工作的基本原理。在离子加速电压不变的条件下,改变磁场强度B的数值,就可使不同质荷比(m/z)离子沿一个固定运动轨迹到达离子接收器。[img=39f8a0dace71923d12022fcea072a59.jpg]https://i2.antpedia.com/attachments/att/image/20220126/1643179072768968.jpg[/img]图1 磁式质量分析器示意图磁式质量分析器的工作原理是依照带电粒子的质荷比来分离的,而且上面公式( D=(2Uz/m)[sup]1/2[/sup])的一个理想条件是离子的初始动能为0,进入磁场的动能完全由加速电压来决定。但实际上离子在离子化和加速过程中初始动能并不相同且不等于0,如果同一质量的离子进入磁场时能量不同,它的运动轨迹也会不同,这就无法实现同一质量数离子的正常聚焦。这种离子能量分散现象会严重影响仪器的分辨率。为了克服离子能量分散对分辨率的影响,通常会在磁分析器前面加一个静电分析器,利用静电分析器对离子进行能量聚集,这就是我们下面要介绍的双聚焦质量分析器。
质量分析器是利用电磁场(包括磁场、磁场与电场组合、高频电场、高频脉冲电场等)的作用将来自离子源的离子束中不同质荷比的[url=https://insevent.instrument.com.cn/t/Mp][color=#3333ff]气相[/color][/url]离子按空间位置、时间先后或运动轨道稳定与否等形式分离的装置。[b]1.质量分析器种类[/b]质量分析器依据不同方式将离子源中生成的样品离子按质荷比m/z的大小分开。质量分析器主要分为:扇形磁场,飞行时间质量分析器,四极杆质量分析器,离子阱,傅里叶变换离子回旋共振分析器。扇形磁场是历史上最早出现的质量分析器,其利用不同质荷比的带电离子在稳定磁场内偏转的半径不同,将离子分开检测。飞行时间质量分析器则是利用不同质荷比的离子经加速电压加速后,飞过一定距离所需的时间不同,即质荷比小的离子飞行速度快,先到达检测器,质荷比大的飞行速度慢则后到,从而获得分离。四极杆、离子阱、傅里叶变换离子回旋共振、轨道阱等质量分析器是利用离子囚禁技术来实现对带电离子的捕获、储存、筛选及分离,即根据离子振动频率的方式来区分。质荷比小的离子,频率较大,质荷比大的离子,频率较小。四极杆质量分析器由四根相互平行并均匀安置的金属杆构成,离子进入后,在交变电场作用下产生振荡,在一定的电场强度和频率下,只有较窄质荷比范围的离子有稳定的运动轨迹,能通过四极杆电极到达检测器,其他离子则由于振幅大而撞到极杆上,实现不同质荷比离子的分离检测。离子阱质量分析器由一个环形电极和两个端盖电极组成,当环电极施加射频电压,两个端电极接地时,就会形成一个电势阱,使离子能够长时间地囚禁于阱内,通过调整扫描参数,使离子运动的频率增加,当和外加频率共振时,离子从外场吸收能量、轨迹变大、抛出阱外而被检测。傅里叶变换离子回旋共振(FTICR)质量分析器是根据磁场中离子回旋频率来测量离子质荷比(m/z)。彭宁阱(Penning trap)捕获的离子被垂直于磁场的振荡电场激发形成一个更大的回旋半径,当回旋的离子束接近一对捕集板时,捕集板上会检测到感应电流信号。通过傅里叶变换,可以将这些电流信号转换成质谱信号。轨道阱(orbitrap)质量分析器是近年来发展的一种新型的质量分析器,其是利用作用在纺锤形电极上的静电场将离子束缚,通过测定离子轴向场的谐振运动频率来确定其质荷比。[b]2.质量分析器性能指标[/b]衡量一个质量分析器性能主要有5个指标:质量分析范围、分析速度、传输效率、质量精度和质量分辨率。质量分析范围决定了质量分析器可以分析离子的m/的上下限。通常用Th或u来表示一个离子带一个单位的正电荷,即z=1。分析速度又称扫描速度,用来描述质量分析器分析某段特定质量范围的速度。通常用每秒可以分析的质量单位(u/s)或每毫秒可以分析的质量单位(u/ms)表示。传输效率指的是可以到达检测器和进入质量分析器的离子数目的比值。传输效率包括在分析器的其他部分的离子丢失,如通过质量分析器前和后的电子透镜所丢失的离子。质量精度是指质谱仪测量m/z精确度的描述,它主要是指理论值m/Z理论和测量值m/Z测量值之间的差距。它可以用毫质量单位即mmu来表示,也可以用百万分之一([img=CodeCogsEqn(1).gif]https://i4.antpedia.com/attachments/att/image/20220126/1643166392876602.gif[/img])来表示。质量精度在很大程度上与仪器的稳定性和分辨率有关。质量分辨率,或者也可以说是分辨能力。分辨率指的是仪器可以获得两个具有微小质量差别的离子所对应信号的能力。两个质量峰被认为区分的条件是:当使用磁场或离子回旋共振分析器时,两个峰之间的峰谷的强度不高于两峰之间较弱峰强的10%,当使用四极杆、离子阱、TOF时,不高于50%。如果用△m来表示两个具有质量分别为m和m+△m的质谱峰可以被分开的最小质量,则分辨率R的定义为R=m/△m。[table][tr][td][b]项目[/b][/td][td][b]扇形磁场(magnetic)[/b][/td][td][b]飞行时间(TOP)[/b][/td][td][b]四级杆(quadrupole)[/b][/td][td][b]离子阱(ion trap)[/b][/td][td][b]傅里叶变换离子回旋共振(FTICR)[/b][/td][td][b]轨道阱(orbitrap)[/b][/td][/tr][tr][td]质量范围[/td][td]20000Th[/td][td]1000000Th[/td][td]4000Th[/td][td]6000Th[/td][td]30000Th[/td][td]50000Th[/td][/tr][tr][td]分辨率[/td][td]100000[/td][td]5000[/td][td]2000[/td][td]4000[/td][td]500000[/td][td]100000[/td][/tr][tr][td]质量精度[/td][td]10[img=CodeCogsEqn(19).gif]https://i4.antpedia.com/attachments/att/image/20220126/1643166392926197.gif[/img][/td][td]200[img=CodeCogsEqn(19).gif]https://i4.antpedia.com/attachments/att/image/20220126/1643166393329357.gif[/img][/td][td]100[img=CodeCogsEqn(19).gif]https://i4.antpedia.com/attachments/att/image/20220126/1643166393370078.gif[/img][/td][td]100[img=CodeCogsEqn(19).gif]https://i4.antpedia.com/attachments/att/image/20220126/1643166393225800.gif[/img][/td][td]5[img=CodeCogsEqn(19).gif]https://i4.antpedia.com/attachments/att/image/20220126/1643166393208659.gif[/img][/td][td]5[img=CodeCogsEqn(19).gif]https://i4.antpedia.com/attachments/att/image/20220126/1643166394336945.gif[/img][/td][/tr][tr][td]离子进入方式[/td][td]连续[/td][td]脉冲[/td][td]连续[/td][td]脉冲[/td][td]脉冲[/td][td]脉冲[/td][/tr][tr][td]工作压力[/td][td][img=CodeCogsEqn(20).gif]https://i4.antpedia.com/attachments/att/image/20220126/1643166394700923.gif[/img]Torr[/td][td][img=CodeCogsEqn(20).gif]https://i4.antpedia.com/attachments/att/image/20220126/1643166394998738.gif[/img]Torr[/td][td][img=CodeCogsEqn(21).gif]https://i4.antpedia.com/attachments/att/image/20220126/1643166394184126.gif[/img]Torr[/td][td][img=10的-3.gif]http://www.ewg1990.com/upload/image/20190116/10%E7%9A%84-33576495.gif[/img]Torr[/td][td][img=CodeCogsEqn(22).gif]https://i4.antpedia.com/attachments/att/image/20220126/1643166395141047.gif[/img]Torr[/td][td][img=CodeCogsEqn(22).gif]https://i4.antpedia.com/attachments/att/image/20220126/1643166395961052.gif[/img]Torr[/td][/tr][/table]表1常见质量分析器性能参数[b]3.质量分析器的特点及联用[/b]每个质量分析器都有其优缺点。如扇形磁场质量分析器重现性好,能够较快地进行扫描,但在目前出现的小型化质量分析器中,其所占的比重不大,因为如果降低磁场体积和重量将极大地影响磁场的强度,从而大大削弱其分析性能;四极杆质量分析器结构简单,易加工,成本低,但是其分辨率不高,杆体易被污染,维护和装调难度较大;离子阱质量分析器体积小,可在较高压力下(如0.1Pa)工作,能方便地进行级联质谱检测,尤其在质谱仪器小型化研制中具有无可比拟的优势;傅里叶变换离子回旋共振质量分析器具有更高的灵敏度和分辨率,但价格昂贵;飞行时间质量分析器最大的特点是检测离子的质量范围较大,适用于大分子化合物的分析。为了将质量分析器的优势最大化,可以把不同的质量分析器按一定顺序结合来实现仪器的通用性,在同一台质谱仪器上实现多种功能,如四极杆飞行时间质量分析器、离子阱-飞行时间质量分析器、离子阱-傅里叶变换离子回旋共振质量分析器等。质量分析器的联用可以分析由第一级质量分析器筛选出的离子碎裂后的碎片谱图。从筛选出的离子获得的碎片具有时间依赖性,可以在其后的质量分析器观察到。同时这些仪器允许碎裂的离子继续进行下一级的碎裂,形成多级碎片([img=CodeCogsEqn(10).gif]https://i4.antpedia.com/attachments/att/image/20220126/1643166395559110.gif[/img]),并且被检测到
进行微量分析的色谱柱是否可用于常量分析?为什么?
纤维含量分析,莫代尔和莱赛尔能定量分析吗?
什么是”质量分析手段“,要做一个质量分析手段简介培训,请大神们给予帮助。
[b]质量分析[/b]其作用是将电离室中生成的离子按质荷比(m/z)大小分开,进行质谱检测。常见质量分析器有:[b]四极质量分析器(quadrupoleanalyzer)[/b]原理:由四根平行圆柱形电极组成,电极分为两组,分别加上直流电压和一定频率的交流电压。样品离子沿电极间轴向进入电场后,在极性相反的电极间振荡,只有质荷比在某个范围的离子才能通过四极杆,到达检测器,其余离子因振幅过大与电极碰撞,放电中和后被抽走。因此,改变电压或频率,可使不同质荷比的离子依次到达检测器,被分离检测。[b]扇形质量分析器[/b]磁式扇形质量分析器(magnetic-sector massanalyzer)被电场加速的离子进入磁场后,运动轨道弯曲了,离子轨道偏转可用公式表示:当H,V一定时,只有某一质荷比的离子能通过狭缝到达检测器。特点:分辨率低,对质量同、能量不同的离子分辨较困难。[b]双聚焦质量分析器[/b](double-focusing massassay)由一个静电分析器和一个磁分析器组成,静电分析器允许有某个能量的离子通过,并按不同能量聚焦,先后进入磁分析器,经过两次聚焦,大大提高了分辨率。
请问SCAN定量分析曲线可以用在SIM定量分析中吗?







 我要推广仪器
我要推广仪器
 下载APP
下载APP