现有基因重组表达的糖蛋白想进行以下几项委托检测, C端氨基酸测序、氨基酸组分分析、肽图、质谱分子量、糖基化分析如果有意者请联系,将样品要求、检测费用以及合作流程发到邮箱,如有疑问可以加qq联系。 qq:278569901 邮箱:wbz5102@gmail.com
蛋白测序和质谱的区别
不过短短数十年,基因测序的价格从近30亿美元步入千元时代,这让你有没有恍如隔世的感觉?如果全基因组测序的价格降到非常低,你会选择测自己的基因序列吗?商家说做基因测序可以预知孩子有哪些天赋,你相信吗?Illumina、Life Tech、罗氏、华大基因,基因测序仪器市场谁主沉浮?中科院北京基因组研究所、中科院半导体所、北京大学、东南大学,学院派能否挑起测序仪器国产化的大梁?质谱技术也可以用来做基因测序,你听说过吗?虽然基因测序越来越容易,但我们得到的却是一本生命天书,要完全读懂它我们还需要多少时间?更多关于基因测序的信息,请访问:http://www.instrument.com.cn/news/subject/s325/
听说蛋白酶解肽段二级质谱图可以通过de novo方法测序,请问,除了手工解析,用哪些软件可以快速鉴定辅助解析
Edman降解法是测定蛋白质序列的经典方法,该方法由瑞士生物化学家佩尔维克托于1950年创立。Edman降解法通常是以周期的形式来表征。对于一个完整的周期,异硫氰酸苯酯标记上指定肽段的N末端,环化,之后被标记的氨基酸在酸性条件下从肽链中游离出来,进一步酸化后形成一个更加稳定的乙内酰苯硫脲-氨基酸(PTH-AA)衍生物。PTH-AA衍生物可以通过高效液相色谱鉴定。埃德曼降解周期就是通过反复地将多肽的氨基酸依次降解下来,从而鉴定氨基酸序列。 1982年,美国应用生物系统(ABI)公司了将第一台商用自动多肽测序仪推向市场,并被实践证明是可靠和耐用的。实际上,在过去几十年中,自动多肽测序仪只有屈指可数的一些改进,但此类自动肽测序仪仍是测定肽序列的黄金标准。然而,串联质谱的使用已经成为日益重要的肽序列测定工具。质谱,特别是串联飞行时间(TOF-TOF 和QTOF)质谱仪可以对少量样本进行更快速的分析。 与质谱相比,自动Edman降解测序的明显优势在于:已被化学验证的精确性、系统初始投资较小 然而,它的缺点是:分析时间较长、测得序列数有限,典型的测量长度范围是20~50个氨基酸序列。而对于低丰度的肽、无法获得N末端的肽,或者需要更短的分析时间,质谱则是理想的工具。但是,质谱价格高且无法区分同分异构的氨基酸。 虽然美国应用生物系统(ABI)公司主导了自动多肽测序仪的市场,但由于市场疲软,ABI于2008年6月停止生产自动多肽测序仪。然而岛津公司看准了机会,在2009年匹兹堡会议上将其PPSQ自动多肽测序仪推向北美市场,PPSQ已在日本广泛应用超过20年。另一方面,对用质谱测定蛋白质序列的方法改进的需求保持旺盛,布鲁克道尔顿公司最近推出了Edmass Micro MALDI-TOF和 Edmass Ultra TOF-TOF 系统,这是专门为没有质谱使用经验的多肽化学家们设计的。 自动多肽测序仪的市场主要来自于科研机构,但过去几年中自动多肽测序仪的市场需求增长处于某种停滞状态,尤其是质谱变得容易获得。但是,随着肽自动测序仪在连续使用过程中的老化,Edamn化学家们正在准备购买新设备。售后服务、附件、耗材及试剂有望在短期内对自动多肽测序仪市场产生推动作用。
测序都是从5'端进行的,正向和反向测序是指对DNA的两条互补链分别测序,通常两个方向测序结果经校读后完全一致才能认为得到可靠结果。生工测序结果一般都提供两个文档,一个是TEXT的序列文档,一个是用Chromas软件打开的ABI文档。1.寻找引物http://blast.ncbi.nlm.nih.gov/Blast.cgi 比对,去除引物序列,找到目的片段。在DNAMan上进行比对,看引物能不能比对上(一个不变,一个反向互补),如果比不上,那可能就不是你要的序列,如果能比上,上游以引物第一个为分界线,去除前面的;下有一最后一个为分界线,去除后面的,剩下的就是目的序列。然后在NCBI上Blast.就OK了。批注:PCR产物进行测序的结果可能不包含引物序列2.将找到的对应目的片段转成*.txt格式3.下载BioEdit软件第一:打开Bioedit软件,导入拼接好的样品序列与标准亚型参考序列File—New Alignment—Sequence—New Sequence—导入拼接好的样品序列和标准参考序列(从TEXT文档利用复制粘贴工具)—Apply and close —保存结果—关闭窗口第二:点击菜单栏上按钮“Accessory Application”,选择“Clustalw Multiple Alignment”File—Open—Accessory Application—Clustalw Multiple Alignment第三:比对结束后,删除比对序列两端的多余序列,使所有序列等长选择需要编辑的序列—Sequence—Edit Sequence—进行序列的编辑—保存修改后结果第四:选择“Sequence”菜单下的“Gaps”,点击“Lock Gaps”第五:将比对后的序列保存为Fasta 格式文档4.下载MAGE4.0软件1) 打开MEGA软件,选择“File”菜单栏中的“Convert To MEGA Format”,把序列文件的格式转换为meg文档保存;2) 双击序列的meg文档,选择“Nucleotide Sequences”,点击“OK”;3) 程序运行中询问是否为蛋白编码序列,选择“NO”;4) 在MEGA操作界面选择“Phylogeny”菜单栏下“Bootstrap Test of Phylogeny”中的“Neibour-Joining”;5) 选择“Test of Phylogeny”栏中的“Bootsrap”,“Replications”设定为1 000;在“Options Summary”栏中的“Model”项中,设定参数为“Kimura 2-Paramete”r,最后选择“Compute”;6) 将分析结果采用Los Alamos HIV序列库提供的HIV-BLAST和Subtyping工具进行验证。
大家好,氨基酸分析仪与蛋白质测序仪有主要区别在什么地方呢?目前实验室需要进行氨基酸的测序分析,究竟买一台蛋白质测序仪好呢,还是氨基酸分析仪好呢?价格大概有多少呢?这些仪器有没有国产的呢 QQ:2392795357
蛋白质是生物体中含量最高,功能最重要的生物大分子,存在于所有生物细胞,约占细胞干质量的50%以上, 作为生命的物质基础之一,蛋白质在催化生命体内各种反应进行、调节代谢、抵御外来物质入侵及控制遗传信息等方面都起着至关重要的作用,因此蛋白质也是生命科学中极为重要的研究对象。关于蛋白质的分析研究,一直是化学家及生物学家极为关注的问题,其研究的内容主要包括分子量测定,氨基酸鉴定,蛋白质序列分析及立体化学分析等。随着生命科学的发展,仪器分析手段的更新,尤其是质谱分析技术的不断成熟,使这一领域的研究发展迅速。 自约翰.芬恩(JohnB.Fenn)和田中耕一(Koichi.Tanaka)发明了对生物大分子进行确认和结构分析的方法及发明了对生物大分子的质谱分析法以来,随着生命科学及生物技术的迅速发展,生物质谱目前已成为有机质谱中最活跃、最富生命力的前沿研究领域之一[1]。它的发展强有力地推动了人类基因组计划及其后基因组计划的提前完成和有力实施。质谱法已成为研究生物大分子特别是蛋白质研究的主要支撑技术之一,在对蛋白质结构分析的研究中占据了重要地位[2]。 1.质谱分析的特点 质谱分析用于蛋白质等生物活性分子的研究具有如下优点:很高的灵敏度能为亚微克级试样提供信息,能最有效地与色谱联用,适用于复杂体系中痕量物质的鉴定或结构测定,同时具有准确性、易操作性、快速性及很好的普适性。 2.质谱分析的方法 近年来涌现出较成功地用于生物大分子质谱分析的软电离技术主要有下列几种:1)电喷雾电离质谱;2)基质辅助激光解吸电离质谱;3)快原子轰击质谱;4)离子喷雾电离质谱;5)大气压电离质谱。在这些软电离技术中,以前面三种近年来研究得最多,应用得也最广泛[3]。 3.蛋白质的质谱分析 蛋自质是一条或多条肽链以特殊方式组合的生物大分子,复杂结构主要包括以肽链为基础的肽链线型序列[称为一级结构]及由肽链卷曲折叠而形成三维[称为二级,三级或四级]结构。目前质谱主要测定蛋自质一级结构包括分子量、肽链氨基酸排序及多肽或二硫键数目和位置。 3.1蛋白质的质谱分析原理 以往质谱(MS)仅用于小分子挥发物质的分析,由于新的离子化技术的出现,如介质辅助的激光解析/离子化、电喷雾离子化,各种新的质谱技术开始用于生物大分子的分析。其原理是:通过电离源将蛋白质分子转化为[url=https://insevent.instrument.com.cn/t/Mp]气相[/url]离子,然后利用质谱分析仪的电场、磁场将具有特定质量与电荷比值(M/Z值)的蛋白质离子分离开来,经过离子检测器收集分离的离子,确定离子的M/Z值,分析鉴定未知蛋白质。 3.2蛋白质和肽的序列分析 现代研究结果发现越来越多的小肽同蛋白质一样具有生物功能,建立具有特殊、高效的生物功能肽的肽库是现在的研究热点之一。因此需要高效率、高灵敏度的肽和蛋白质序列测定方法支持这些研究的进行。现有的肽和蛋白质测序方法包括N末端序列测定的化学方法Edman法、C末端酶解方法、C末端化学降解法等,这些方法都存在一些缺陷。例如作为肽和蛋白质序列测定标准方法的N末端氨基酸苯异硫氰酸酯(phenylisothiocyanate)PITC分析法(即Edman法,又称PTH法),测序速度较慢(50个氨基酸残基/天);样品用量较大(nmol级或几十pmol级);对样品纯度要求很高;对于修饰氨基酸残基往往会错误识别,而对N末端保护的肽链则无法测序[4]。C末端化学降解测序法则由于无法找到PITC这样理想的化学探针,其发展仍面临着很大的困难。在这种背景下,质谱由于很高的灵敏度、准确性、易操作性、快速性及很好的普适性而倍受科学家的广泛注意。在质谱测序中,灵敏度及准确性随分子量增大有明显降低,所以肽的序列分析比蛋白容易许多,许多研究也都是以肽作为分析对象进行的。近年来随着电喷雾电离质谱(electrospray ionisation,ESI)及基质辅助激光解吸质谱(matrix assisted laser desorption/ionization,MALDI)等质谱软电离技术的发展与完善,极性肽分子的分析成为可能,检测限下降到fmol级别,可测定分子量范围则高达100000Da,目前基质辅助的激光解吸电离飞行时间质谱法(MALDI TOF MS)已成为测定生物大分子尤其是蛋白质、多肽分子量和一级结构的有效工具,也是当今生命科学领域中重大课题——蛋白质组研究所必不可缺的关键技术之一 [5] 。目前在欧洲分子生物实验室(EMBL)及美国、瑞士等国的一些高校已建立了MALDI TOF MS蛋白质一级结构(序列)谱库,能为解析FAST谱图提供极大的帮助,并为确证分析结果提供可靠的依据[6]。
大家好最近在做DNA点突变的研究,由于基因很大,有七十几个外显子,如果一一扩增测序的话成本和时间上都不划算.所以在考虑能否用质谱的方法,或者其他什么分析的方法先进行下初筛。和标样比较,如果看到了某个峰有异常的话,再专门扩增这个外显子去测序外显子一般200-300bp。想请教大家,不知道用质谱的方法可不可以?另外,国内有哪里用质谱进行DNA序列的研究的吗?我知道用MALDI-TOF-TOF这个进行SNP的研究,但是对于我们这个200-300bp来说量程上就太小了。期待大家的回答~~~~
质谱技术在蛋白鉴定等实验中具有不可忽视的作用,应用前景十分广泛。那么,有问题了怎么解决呢?问题1. 一级质谱和二级质谱有什么区别?什么时候做一级,什么时候做二级?答:一级质谱鉴定的方式主要指胎指纹图谱(peptide-mass mapping, PMF),即利用质谱仪精确测量酶解片段的分子量并搜库比较实现蛋白质的鉴定,二级质谱是在一级质谱的基础上再选择部分肽段做进一步的破碎并对碎片进行深入分析和比较,鉴定出该肽段的序列并结合PMF的结果从而实现蛋白质的鉴定。二级质谱能够得到部分肽短的序列,具有更高的可靠性。随着现在杂志对数据的要求越来越严格,二级质谱鉴定是蛋白鉴定的大趋势,而且即使目前做一级质谱鉴定的结果,也需要挑选部分PMF结果做二级质谱验证。问题2. 研究的物种不是模式生物怎么办?答:可以参考亲缘关系最近的模式生物做比对而实现蛋白质的成功鉴定,如果质谱图很好而没有鉴定结果说明这是一个全新的蛋白,可以采用de-novo等技术做深入分析与鉴定。问题3. 该如何评价质谱效果的好坏?答:做PMF一般得分超过60分(P0.05)就算成功鉴定,而串联质谱,得分超过60分或者虽然没有超过60分,但是有最少一条肽段的得分超过30分就算成功鉴定。问题4. 一些特殊的质谱方法有什么用途?答:质谱的其它用途包括修饰位点分析、蛋白测序、混合蛋白鉴定以及分子量精确测定、二硫键位置分析等等。问题5. 用什么染色方法比较好?答:最好用考马斯亮蓝法进行染色,银染也可以,但鉴定成功率稍低,并且推荐用串联质谱对银染蛋白进行鉴定可以大大提高鉴定成功率。问题6 质谱鉴定取胶点有什么注意事项?答:离心管最好用进口离心管,以免塑料污染;水最好用去离子水或者双蒸水;取点的时候带好口罩与手套,以免角蛋白污染。问题7. 凝胶是否可以长期保存?该如何保存?如何运送?答:蛋白凝胶可以长期保存而不影响质谱鉴定效果,一般而言,如果在一两个星期以内,最好用保鲜膜包好,放到4度冰箱保存,如果保存时间超过一个月,可以把蛋白点取下后放入-20度或者-80度冰箱,不会影响后续质谱鉴定效果。运送胶点的时候采用常温运送即可,三五天内都不会有太大的影响。问题8. 质谱鉴定大致是什么流程?质谱鉴定主要包括蛋白酶解、质谱数据获取、对库检索三个步骤。问题9. 串联质谱鉴定和质谱测序有什么区别?质谱鉴定往往采用软件对已有数据库进行自动检索匹配得到结果,而质谱测序则需要根据质谱峰图中相邻或者相近峰的分子量差异直接推算出肽段的序列。问题10. 未知蛋白质是通过质谱还是蛋白质测序仪来测序的呢?现在比较简单的方法是质谱法。如果质谱法不能确定的话还可以结合N端测序,可测10几个氨基酸。两个数据结合分析基本可以确定目的蛋白了,现在的蛋白质组数据库相当强大了。不知道看完这10个FAQ,各位有没有些许受益,如果还有好的想法或者意见,欢迎给小编留言!(来源:互联网)
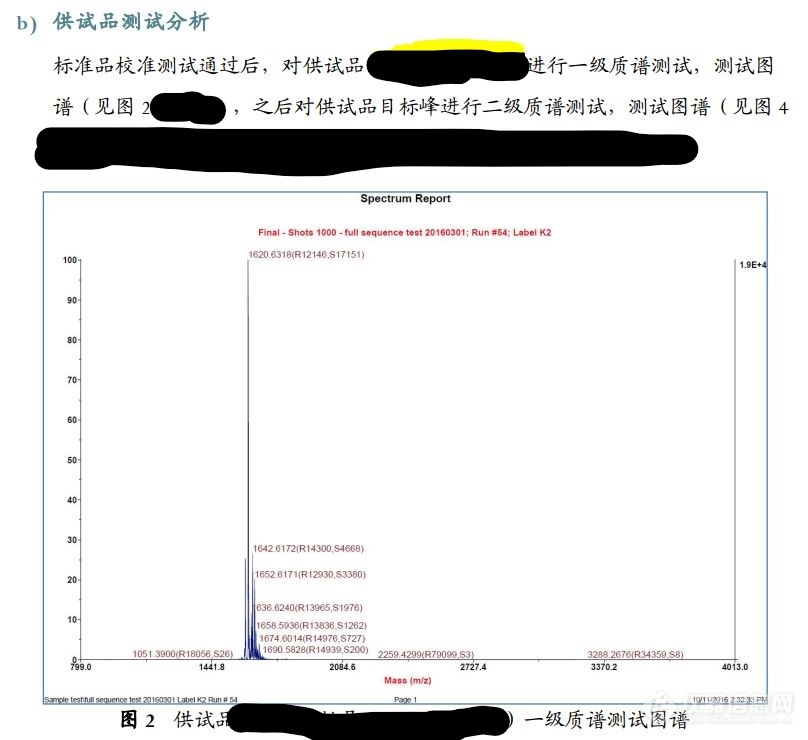
[img=一级质谱,690,631]https://ng1.17img.cn/bbsfiles/images/2019/01/201901101456009376_9858_3402538_3.jpg!w690x631.jpg[/img]上图是供试品的一级质谱图[img=二级质谱,690,509]https://ng1.17img.cn/bbsfiles/images/2019/01/201901101456034028_554_3402538_3.jpg!w690x509.jpg[/img]上图是供试品的二级质谱图[img=,690,468]https://ng1.17img.cn/bbsfiles/images/2019/01/201901101509174178_4191_3402538_3.jpg!w690x468.jpg[/img]上图为数据检索得分[img=,690,296]https://ng1.17img.cn/bbsfiles/images/2019/01/201901101512324593_2256_3402538_3.jpg!w690x296.jpg[/img]上图为二级质谱数据匹配情况[img=,690,614]https://ng1.17img.cn/bbsfiles/images/2019/01/201901101515133048_785_3402538_3.jpg!w690x614.jpg[/img]上图为数据匹配列表。[img=,690,328]https://ng1.17img.cn/bbsfiles/images/2019/01/201901101520040075_9080_3402538_3.jpg!w690x328.jpg[/img]根据实验结果多肽的氨基酸全序列为:Trp1-Asn2-Asp3-Thr4-Gly5-Orn6-Asp7-Ala8-Asp9-Gly10-Ser11-3MeGlu12-Kyn13注:Thr(4), Kyn(13)形成内酯请问各位高人:1、MASCOT2.2 是一个质谱谱图的数据库吗?2、供试品 MASCOT 二级质谱数据检索得分16 算高吗? 得分越高越精准还是越低越精准? 它通常的得分值是多少?3、图7所示的二级质谱数据匹配图示是如何看的呢?每个值上面的系数代表什么意思呢?4、表 1所示的 二级质谱数据匹配列表是如何看的呢?首行和首列的参数各代表什么意思呢?表中标红的数值表示匹配度高吗?5、请问有没有关于多肽二级质谱测序的教科书或文献能推荐的?谢谢各位了,因为本人虽然学过质谱解析,但刚刚接触到多肽的二级质谱测序,所以问题较多,也比较幼稚。还望各位能不吝赐教。再次感谢。
蛋白质结构分析:制备、鉴定与微量测序
DNA序列测定分手工测序和自动测序,手工测序包括Sanger双脱氧链终止法和Maxam-Gilbert化学降解法。自动化测序实际上已成为当今DNA序列分析的主流。美国PE ABI公司已生产出373型、377型、310型、3700和3100型等DNA测序仪,其中310型是临床检测实验室中使用最多的一种型号。本实验介绍的是ABI PRISM 310型DNA测序仪的测序原理和操作规程。【原理】ABI PRISM 310型基因分析仪(即DNA测序仪),采用毛细管电泳技术取代传统的聚丙烯酰胺平板电泳,应用该公司专利的四色荧光染料标记的ddNTP(标记终止物法),因此通过单引物PCR测序反应,生成的PCR产物则是相差1个碱基的3'''端为4种不同荧光染料的单链DNA混合物,使得四种荧光染料的测序PCR产物可在一根毛细管内电泳,从而避免了泳道间迁移率差异的影响,大大提高了测序的精确度。由于分子大小不同,在毛细管电泳中的迁移率也不同,当其通过毛细管读数窗口段时,激光检测器窗口中的CCD(charge-coupled device)摄影机检测器就可对荧光分子逐个进行检测,激发的荧光经光栅分光,以区分代表不同碱基信息的不同颜色的荧光,并在CCD摄影机上同步成像,分析软件可自动将不同荧光转变为DNA序列,从而达到DNA测序的目的。分析结果能以凝胶电泳图谱、荧光吸收峰图或碱基排列顺序等多种形式输出。它是一台能自动灌胶、自动进样、自动数据收集分析等全自动电脑控制的测定DNA片段的碱基顺序或大小和定量的高档精密仪器。PE公司还提供凝胶高分子聚合物,包括DNA测序胶(POP 6)和GeneScan胶(POP 4)。这些凝胶颗粒孔径均一,避免了配胶条件不一致对测序精度的影响。它主要由毛细管电泳装置、Macintosh电脑、彩色打印机和电泳等附件组成。电脑中则包括资料收集,分析和仪器运行等软件。它使用最新的CCD摄影机检测器,使DNA测序缩短至2.5h,PCR片段大小分析和定量分析为10~40min。由于该仪器具有DNA测序,PCR片段大小分析和定量分析等功能,因此可进行DNA测序、杂合子分析、单链构象多态性分析(SSCP)、微卫星序列分析、长片段PCR、RT-PCR(定量PCR)等分析,临床上可除进行常规DNA测序外,还可进行单核苷酸多态性(SNP)分析、基因突变检测、HLA配型、法医学上的亲子和个体鉴定、微生物与病毒的分型与鉴定等。【试剂与器材】1.BigDye测序反应试剂盒 主要试剂是BigDye Mix,内含PE专利四色荧光标记的ddNTP和普通dNTP,AmpliTaq DNA polymerase FS,反应缓冲液等。 2.pGEM-3Zf(+)双链DNA对照模板0.2g/L,试剂盒配套试剂。 3.M13(-21)引物TGTAAAACGACGGCCAGT,3.2μmol/L,即3.2pmol/μl,试剂盒配套试剂。 4.DNA测序模板 可以是PCR产物、单链DNA和质粒DNA等。模板浓度应调整在PCR反应时取量1μl为宜。本实验测定的质粒DNA,浓度为0.2g/L,即200ng/μl。 5.引物 需根据所要测定的DNA片段设计正向或反向引物,配制成3.2μmol/L,即3.2pmol/μl。如重组质粒中含通用引物序列也可用通用引物,如M13(-21)引物,T7引物等。 6.灭菌去离子水或三蒸水。 7.0.2ml或和0.5ml的PCR管,盖体分离,PE公司产品。 8.3mol/L 醋酸钠(pH5.2)称取40.8g NaAc·3H2O溶于70ml蒸馏水中,冰醋酸调pH至5.2,定容至100ml,高压灭菌后分装。 9.70%乙醇和无水乙醇。 10.NaAc/乙醇混合液 取37.5ml无水乙醇和2.5ml 3mol/L NaAc混匀,室温可保存1年。 11.POP 6测序胶 ABI产品。 12.模板抑制试剂(TSR)ABI产品。 13.10×电泳缓冲液 ABI产品。 14.ABI PRISM 310型全自动DNA测序仪。 15.2400型或9600型PCR仪。 16.台式冷冻高速离心机。 17.台式高速离心机或袖珍离心机。
广州:无症状感染者测序溯源分析完成,感染源来自隔离酒店输入病例;
公司现有1台ABI3100 测序仪,成色较新,价格优惠,质量保证,可预约试机。电话:13717963569自动化程度高:提供连续,无监控的操作,自动灌胶,上样,电泳分离,检测及数据分析,可连续运行24小时无需人工干预。样品分析量大:可同时对16个样品进行全自动分析,一天可完成数百个样品的测序或片段分析工作先进的荧光检测系统:采光栅分光,CCD摄像机成像技术,实现多色荧光同时检测应用广泛:除了新基因测序或比较测序工作外,可进行多种片段分析,包括微卫星DNA分析,比较基因型分析,单核苷酸多态性(SNP)研究
[align=center][b][font=宋体]利用[/font][font='Times New Roman']MGI[/font][font=宋体]平台对大豆进行全基因组重测序分析[/font][/b][/align][b][font=宋体]摘要[/font][/b][font=宋体][font=宋体]:本研究建立了[/font][font=Times New Roman]MGI[/font][font=宋体]平台全基因重测序的方法。[/font][font=Times New Roman]MGI[/font][font=宋体]平台对大豆的全基因进行重测序结果显示,测序数据质量良好,且与参考基因组比对率较高,符合后续分析要求,对其进行[/font][font=Times New Roman]SNP[/font][font=宋体]和[/font][font=Times New Roman]Indel[/font][font=宋体]的变异检测和注释,此结果说明今后可利用[/font][font=Times New Roman]MGI[/font][font=宋体]平台对其它样品进行全基因重测序分析。[/font][/font][b][font=宋体]关键词[/font][/b][font=宋体][font=宋体]:[/font][font=Times New Roman]MGI[/font][font=宋体]平台;全基因重测序[/font][/font][align=center][font='Times New Roman']Whole genome resequencing analysis of soybeans using the MGI platform[/font][/align][b][font='Times New Roman']Abstract:[/font][font=宋体] [/font][/b][font=宋体][font=Times New Roman]In this study, a method for whole gene resequencing on the MGI platform was established. The results of resequencing the whole genes of soybean by MGI platform showed that the sequencing data was of good quality and had a high comparison rate with the reference genome, which met the requirements of subsequent analysis, and the variation detection and annotation of SNP and Indel were carried out, which indicated that the MGI platform could be used to perform whole gene resequencing analysis on other samples in the future.[/font][/font][b][font='Times New Roman']Keywords:[/font][font=宋体] [/font][/b][font=宋体][font=Times New Roman]MGI platform Whole gene resequencing[/font][/font][font='Times New Roman'] [/font][b][font='Times New Roman']1 [font=宋体]研究背景[/font][/font][/b][font='Times New Roman'][font=宋体]大豆是重要的粮食作物和油料作物,也是人类最主要的植物蛋白来源[/font][/font][font=宋体][font=Times New Roman][1][/font][/font][font=宋体][font=宋体]。我国是野生大豆的发源地,有着极其丰富的大豆种质资源基础,但是育种和产量较其他大豆主产国显得略有不足,究其原因是我国对大豆的研究和发掘力度存在不足,因此,对大豆育成品种的改良势在必行。自[/font][font=Times New Roman]2010[/font][font=宋体]年起,大豆群体水平的重测序也全面开展,在大豆的全基因组变异图谱上也得到了一定的研究进展[/font][/font][font=宋体][font=Times New Roman][2][/font][/font][font=宋体][font=宋体]。本研究利用[/font][font=Times New Roman]MGI[/font][font=宋体]平台对大豆全基因组进行重测序分析,挖掘全基因组水平上的突变。[/font][/font][b][font=宋体][font=Times New Roman]2 [/font][font=宋体]实验仪器[/font][/font][/b][font=宋体]主要实验仪器:[/font][font=宋体][font=Times New Roman]MGISP-960[/font][font=宋体]、[/font][font=Times New Roman]MGIDL-T7[/font][font=宋体]、[/font][font=Times New Roman]DNBSEQ-T7[/font][/font][b][font=宋体][font=Times New Roman]3 [/font][font=宋体]实验结果[/font][/font][font=宋体][font=Times New Roman]3.1 [/font][font=宋体]测序数据质量[/font][/font][/b][font=宋体][font=宋体]根据[/font][font=Times New Roman]MGI[/font][font=宋体]平台的测序特点,使用双端测序的数据,要求[/font][font=Times New Roman]Q30[/font][font=宋体]平均比例在[/font][font=Times New Roman]85%[/font][font=宋体]以上,可以看出大豆重测序数据[/font][font=Times New Roman]Q30[/font][font=宋体]平均比例在[/font][font=Times New Roman]94.72%[/font][font=宋体]以上,说明大豆测序数据质量良好,满足分析要求。[/font][/font][font='Times New Roman'] [/font][font='Times New Roman'] [/font][b][font=黑体][font=黑体]表[/font][font=Times New Roman]1 [/font][font=黑体]测序数据统计表[/font][/font][/b][table][tr][td][align=center][font='Times New Roman']Samples[/font][/align][/td][td][align=center][font='Times New Roman']ID[/font][/align][/td][td][align=center][font='Times New Roman']Clean reads[/font][/align][/td][td][align=center][font='Times New Roman']Clean bases[/font][/align][/td][td][align=center][font='Times New Roman']GC Content[/font][/align][/td][td][align=center][font='Times New Roman']%[/font][font=等线]≥[/font][font='Times New Roman']Q20[/font][/align][/td][td][align=center][font='Times New Roman']%[/font][font=等线]≥[/font][font='Times New Roman']Q30[/font][/align][/td][/tr][tr][td][align=center][font='Times New Roman']P117[/font][/align][/td][td][align=center][font='Times New Roman']P117[/font][/align][/td][td][align=center][font='Times New Roman']169494922[/font][/align][/td][td][align=center][font='Times New Roman']25424238300[/font][/align][/td][td][align=center][font='Times New Roman']36.18%[/font][/align][/td][td][align=center][font='Times New Roman']98.49%[/font][/align][/td][td][align=center][font='Times New Roman']95.27%[/font][/align][/td][/tr][tr][td][align=center][font='Times New Roman']P118[/font][/align][/td][td][align=center][font='Times New Roman']P118[/font][/align][/td][td][align=center][font='Times New Roman']166483906[/font][/align][/td][td][align=center][font='Times New Roman']24972585900[/font][/align][/td][td][align=center][font='Times New Roman']36.47%[/font][/align][/td][td][align=center][font='Times New Roman']98.61%[/font][/align][/td][td][align=center][font='Times New Roman']95.70%[/font][/align][/td][/tr][tr][td][align=center][font='Times New Roman']P119[/font][/align][/td][td][align=center][font='Times New Roman']P119[/font][/align][/td][td][align=center][font='Times New Roman']186127112[/font][/align][/td][td][align=center][font='Times New Roman']27919066800[/font][/align][/td][td][align=center][font='Times New Roman']35.89%[/font][/align][/td][td][align=center][font='Times New Roman']98.57%[/font][/align][/td][td][align=center][font='Times New Roman']95.61%[/font][/align][/td][/tr][tr][td][align=center][font='Times New Roman']P120[/font][/align][/td][td][align=center][font='Times New Roman']P120[/font][/align][/td][td][align=center][font='Times New Roman']192397276[/font][/align][/td][td][align=center][font='Times New Roman']28859591400[/font][/align][/td][td][align=center][font='Times New Roman']36.46%[/font][/align][/td][td][align=center][font='Times New Roman']98.22%[/font][/align][/td][td][align=center][font='Times New Roman']94.72%[/font][/align][/td][/tr][tr][td][align=center][font='Times New Roman']P198[/font][/align][/td][td][align=center][font='Times New Roman']P198[/font][/align][/td][td][align=center][font='Times New Roman']141636468[/font][/align][/td][td][align=center][font='Times New Roman']21245470200[/font][/align][/td][td][align=center][font='Times New Roman']37.11%[/font][/align][/td][td][align=center][font='Times New Roman']98.67%[/font][/align][/td][td][align=center][font='Times New Roman']95.84%[/font][/align][/td][/tr][tr][td][align=center][font='Times New Roman']P199[/font][/align][/td][td][align=center][font='Times New Roman']P199[/font][/align][/td][td][align=center][font='Times New Roman']169468714[/font][/align][/td][td][align=center][font='Times New Roman']25420307100[/font][/align][/td][td][align=center][font='Times New Roman']36.55%[/font][/align][/td][td][align=center][font='Times New Roman']98.60%[/font][/align][/td][td][align=center][font='Times New Roman']95.66%[/font][/align][/td][/tr][tr][td][align=center][font='Times New Roman']P200[/font][/align][/td][td][align=center][font='Times New Roman']P200[/font][/align][/td][td][align=center][font='Times New Roman']155078286[/font][/align][/td][td][align=center][font='Times New Roman']23261742900[/font][/align][/td][td][align=center][font='Times New Roman']37.90%[/font][/align][/td][td][align=center][font='Times New Roman']98.77%[/font][/align][/td][td][align=center][font='Times New Roman']96.14%[/font][/align][/td][/tr][/table][font=Calibri] [/font][font=宋体][font=宋体]样品原始数据碱基质量值可由图[/font][font=Times New Roman]1[/font][font=宋体]看出不存在异常碱基,[/font][font=Times New Roman]6[/font][font=宋体]个大豆碱基测序错误率分布均如图[/font][font=Times New Roman]1[/font][font=宋体]。[/font][/font][align=center][img=,321,]file:///C:/Users/xuxu/AppData/Local/Temp/ksohtml9716/wps1.jpg[/img][font=Calibri] [/font][/align][align=center][b][font=黑体][font=黑体]图[/font] [font=Times New Roman]1 [/font][font=黑体]碱基测序错误率分布图[/font][/font][/b][/align][font=宋体][font=宋体]碱基类型分布检查可用于检测有无[/font][font=Times New Roman]AT[/font][font=宋体]、[/font][font=Times New Roman]GC[/font][font=宋体]分离现象,若有碱基分离现象可能是测序或建库所带来的,并会影响后续分析。高通量所测序为基因组随即打断后的[/font][font=Times New Roman]DNA[/font][font=宋体]片段,由于位点在基因组上的分布是近似均匀的,同时,[/font][font=Times New Roman]G/C[/font][font=宋体]、[/font][font=Times New Roman]A/T[/font][font=宋体]含量也是近似均匀的。因此,根据大数定理,在每个测序循环上,[/font][font=Times New Roman]GC[/font][font=宋体]、[/font][font=Times New Roman]AT[/font][font=宋体]含量应当分别相等,且等于基因组的[/font][font=Times New Roman]GC[/font][font=宋体]、[/font][font=Times New Roman]AT[/font][font=宋体]含量。同样因为重叠等的关系会导致样品前几个碱基[/font][font=Times New Roman]AT[/font][font=宋体]、[/font][font=Times New Roman]GC[/font][font=宋体]不等波动较大,高于其他测序区段,而其它区段的[/font][font=Times New Roman]GC[/font][font=宋体]、[/font][font=Times New Roman]AT[/font][font=宋体]含量相等,且分布均匀无分离现象,如图[/font][font=Times New Roman]2[/font][font=宋体]所示。[/font][/font][align=center][img=,321,]file:///C:/Users/xuxu/AppData/Local/Temp/ksohtml9716/wps2.jpg[/img][font=Calibri] [/font][/align][b][font=黑体][font=黑体]图[/font][font=Times New Roman]2 ATGC[/font][font=黑体]含量分布图[/font][/font][font=宋体][font=Times New Roman]3.2 [/font][font=宋体]与参考基因组的序列比对[/font][/font][font='Times New Roman']3.2.1 [font=宋体]比对结果[/font][/font][/b][font=宋体][font=宋体]将测序得到的大豆样品与参考基因进行序列比对,[/font][font=Times New Roman]bwa[/font][font=宋体]软件主要用于二代高通量测序得到的短序列与参考基因组进行比对,比对结果见表[/font][font=Times New Roman]2[/font][font=宋体],根据比对结果可评估测序数据是否满足后续分析。[/font][/font][align=center][b][font=黑体][font=黑体]表[/font][font=Times New Roman]2 [/font][font=黑体]比对效率统计表[/font][/font][/b][/align][table][tr][td][align=center][font='Times New Roman']Sample_ID[/font][/align][/td][td][align=center][font='Times New Roman']Mapped(%)[/font][/align][/td][td][align=center][font='Times New Roman']Properly_mapped(%)[/font][/align][/td][td][align=center][font='Times New Roman']Averge_depth[/font][/align][/td][/tr][tr][td][align=center][font='Times New Roman']P117[/font][/align][/td][td][align=center][font='Times New Roman']99.99%[/font][/align][/td][td][align=center][font='Times New Roman']98.53%[/font][/align][/td][td][align=center][font='Times New Roman']25.44[/font][/align][/td][/tr][tr][td][align=center][font='Times New Roman']P118[/font][/align][/td][td][align=center][font='Times New Roman']99.99%[/font][/align][/td][td][align=center][font='Times New Roman']98.55%[/font][/align][/td][td][align=center][font='Times New Roman']24.9[/font][/align][/td][/tr][tr][td][align=center][font='Times New Roman']P119[/font][/align][/td][td][align=center][font='Times New Roman']99.99%[/font][/align][/td][td][align=center][font='Times New Roman']98.63%[/font][/align][/td][td][align=center][font='Times New Roman']27.75[/font][/align][/td][/tr][tr][td][align=center][font='Times New Roman']P120[/font][/align][/td][td][align=center][font='Times New Roman']99.98%[/font][/align][/td][td][align=center][font='Times New Roman']98.28%[/font][/align][/td][td][align=center][font='Times New Roman']28.58[/font][/align][/td][/tr][tr][td][align=center][font='Times New Roman']P198[/font][/align][/td][td][align=center][font='Times New Roman']99.99%[/font][/align][/td][td][align=center][font='Times New Roman']98.58%[/font][/align][/td][td][align=center][font='Times New Roman']21.26[/font][/align][/td][/tr][tr][td][align=center][font='Times New Roman']P199[/font][/align][/td][td][align=center][font='Times New Roman']99.98%[/font][/align][/td][td][align=center][font='Times New Roman']98.50%[/font][/align][/td][td][align=center][font='Times New Roman']25[/font][/align][/td][/tr][tr][td][align=center][font='Times New Roman']P200[/font][/align][/td][td][align=center][font='Times New Roman']99.99%[/font][/align][/td][td][align=center][font='Times New Roman']98.13%[/font][/align][/td][td][align=center][font='Times New Roman']23.13[/font][/align][/td][/tr][/table][font=宋体][font=宋体]将比对到不同染色体的[/font][font=Times New Roman]Reads[/font][font=宋体]进行位置分布统计,绘制[/font][font=Times New Roman]Mapped Reads[/font][font=宋体]在参考基因组上的覆盖深度分布图,见图[/font][font=Times New Roman]3[/font][font=宋体]。[/font][/font][align=center][img=,321,]file:///C:/Users/xuxu/AppData/Local/Temp/ksohtml9716/wps3.jpg[/img][font=Calibri] [/font][/align][align=center][b][font=黑体][font=黑体]图[/font][font=Times New Roman]3 Mapped Reads[/font][font=黑体]在参考基因组上的位置及覆盖深度分布图[/font][/font][/b][/align][font=宋体][font=宋体]统计[/font][font=Times New Roman]Mapped Reads[/font][font=宋体]在指定的参考基因组不同区域的数目,绘制基因组不同区域样品[/font][font=Times New Roman]Mapped Reads[/font][font=宋体]的分布图,见图[/font][font=Times New Roman]4[/font][/font][align=center][img=,321,]file:///C:/Users/xuxu/AppData/Local/Temp/ksohtml9716/wps4.jpg[/img][font=Calibri] [/font][/align][b][font=黑体][font=黑体]图[/font][font=Times New Roman]4 [/font][font=黑体]基因组不同区域[/font][font=Times New Roman]Reads[/font][font=黑体]分布图[/font][/font][font=宋体][font=Times New Roman]3.2.2 [/font][font=宋体]插入片段长度检验[/font][/font][/b][font=宋体][font=宋体]通过检测双端序列在参考基因组上的起止位置,可以得到样品[/font][font=Times New Roman]DNA[/font][font=宋体]打断后得到的测序片段的实际大小,即插入片段大小([/font][font=Times New Roman]Insert Size[/font][font=宋体]),它是信息分析时的一个重要参数。插入片段大小的分布一般符合正态分布,且只有一个单峰,[/font][font=Times New Roman]Insert Size[/font][font=宋体]分布图可以展示各个样品的插入片段的长度分布情况。各样品的插入片段长度模拟分布图见图[/font][font=Times New Roman]5[/font][font=宋体]。[/font][/font][align=center][img=,321,]file:///C:/Users/xuxu/AppData/Local/Temp/ksohtml9716/wps5.jpg[/img][font=Calibri] [/font][/align][align=center][b][font=黑体][font=黑体]图[/font][font=Times New Roman]5 [/font][font=黑体]插入片段长度模拟图[/font][/font][/b][/align][b][font=宋体][font=Times New Roman]3.2.3[/font][/font][font='Times New Roman'][font=宋体]深度分布统计图[/font][/font][/b][font='Times New Roman']Reads[font=宋体]定位到参考基因组后,可以统计参考基因组上碱基的覆盖情况。参考基因组上被[/font][font=Times New Roman]reads[/font][font=宋体]覆盖到的碱基数占基因组的百分比称为基因组覆盖度;碱基上覆盖的[/font][font=Times New Roman]reads[/font][font=宋体]数为覆盖深度。基因组覆盖度可以反映参考基因组上变异检测的完整性,覆盖到的区域越多,可以检测到的变异位点也越多。[/font][/font][font='Times New Roman'][font=宋体]覆盖度主要受测序深度以及样品与参考基因组亲缘关系远近的影响。基因组的覆盖深度会影响变异检测的准确性,在覆盖深度较高的区域(非重复序列区),变异检测的准确性也越高。[/font][/font][font='Times New Roman'][font=宋体]另外,若基因组上碱基的覆盖深度分布较均匀,也说明测序随机性较好。样品的碱基覆盖深度分布曲线和覆盖度分布曲线见图[/font][/font][font=宋体][font=Times New Roman]6[/font][font=宋体]。[/font][/font][align=center][img=,321,]file:///C:/Users/xuxu/AppData/Local/Temp/ksohtml9716/wps6.jpg[/img][font=Calibri] [/font][/align][align=center][b][font=黑体][font=黑体]图[/font] [font=Times New Roman]6 [/font][font=黑体]深度分布统计图[/font][/font][/b][/align][b][font=宋体][font=Times New Roman]3.3 [/font][font=宋体]变异检测[/font][/font][font=宋体][font=Times New Roman]3.3.1 SNP[/font][font=宋体]检测与注释[/font][/font][/b][font='Times New Roman'][font=宋体]根据变异位点在参考基因组上的位置以及参考基因组上的基因位置信息,可以得到变异位点在基因组发生的区域(基因间区、基因区或[/font]CDS[font=宋体]区等),以及变异产生的影响(同义非同义突变等)。软件可以使用[/font][font=Times New Roman]vcf[/font][font=宋体]格式文件作为输入和输[/font][/font][font=宋体][font=宋体]出,见图[/font][font=Times New Roman]7[/font][font=宋体]和图[/font][font=Times New Roman]8[/font][font=宋体]。[/font][/font][align=center][img=,321,]file:///C:/Users/xuxu/AppData/Local/Temp/ksohtml9716/wps7.jpg[/img][font=Calibri] [/font][/align][align=center][b][font=黑体][font=黑体]图[/font][font=Times New Roman]7 SNP[/font][font=黑体]突变类型分布图[/font][/font][/b][/align][align=center][img=,344,]file:///C:/Users/xuxu/AppData/Local/Temp/ksohtml9716/wps8.jpg[/img][font=Calibri] [/font][/align][b][font=黑体][font=黑体]图[/font][font=Times New Roman]8 SNP[/font][font=黑体]注释分类图[/font][/font][font=宋体][font=Times New Roman]3.3.2 Indel[/font][font=宋体]检测与注释[/font][/font][/b][font=宋体][font=宋体]根据所有样品在[/font][font=Times New Roman]CDS[/font][font=宋体]区和全基因范围的[/font][font=Times New Roman]Indel[/font][font=宋体]长度进行统计,其长度分布如图[/font][font=Times New Roman]9[/font][font=宋体]。[/font][/font][align=center][img=,355,]file:///C:/Users/xuxu/AppData/Local/Temp/ksohtml9716/wps9.jpg[/img][font=Calibri] [/font][/align][align=center][b][font=黑体][font=黑体]图[/font][font=Times New Roman]9 [/font][font=黑体]全基因和编码区[/font][font=Times New Roman]Indel[/font][font=黑体]长度分布图[/font][/font][/b][/align][font='Times New Roman'][font=宋体]根据样品检测得到的[/font]Ind[/font][font=宋体][font=Times New Roman]el[/font][/font][font='Times New Roman'][font=宋体]位点在参考基因组上的位置信息,对比参考基因组的基因、[/font]CDS[font=宋体]位置等信息,可以注释[/font][font=Times New Roman]Indel[/font][font=宋体]位点是否发生在基因间区、基因区或[/font][font=Times New Roman]CDS[/font][font=宋体]区、是否为移码突变等。发生移码突变的[/font][font=Times New Roman]Indel[/font][font=宋体]可能会导致基因功能的改变,具体注释结果见[/font][/font][font=宋体][font=宋体]图[/font][font=Times New Roman]10[/font][font=宋体]。[/font][/font][align=center][img=,344,]file:///C:/Users/xuxu/AppData/Local/Temp/ksohtml9716/wps10.jpg[/img][font=Calibri] [/font][/align][align=center][b][font=黑体][font=黑体]图[/font] [font=Times New Roman]10 Indel [/font][font=黑体]注释分类图[/font][/font][/b][/align][b][font=宋体][font=Times New Roman]4 [/font][font=宋体]结论[/font][/font][/b][font=宋体][font=宋体]本文基于[/font][font=Times New Roman]MGI[/font][font=宋体]对大豆进行重基因测序,实验结果可看出,大豆样品测序产出数据良好,与参考基因组序列比对率较高,符合后续分析,对其进行变异检测可得到[/font][font=Times New Roman]SNP[/font][font=宋体]和[/font][font=Times New Roman]Indel[/font][font=宋体]的结果。其它研究表明[/font][/font][font=宋体][font=Times New Roman]MGISEQ-2000[/font][font=宋体]全基因组重测序表现性能稳定、质量可靠,在实际应用上有明显的优势和应用价值[/font][font=Times New Roman][3][/font][font=宋体]。对[/font][/font][font=宋体][font=宋体]本次实验说明[/font][font=Times New Roman]MGI[/font][font=宋体]平台对样品进行重测序效果良好,后续可对其它植物进行重测序。[/font][/font][font=宋体] [/font][font=宋体] [/font][font=宋体]参考文献:[/font][font=宋体][font=Calibri][1] [/font][/font][font='Times New Roman'][font=宋体]张永芳[/font],[font=宋体]钱肖娜[/font][font=Times New Roman],[/font][font=宋体]王润梅[/font][/font][font=宋体][font=Times New Roman],[/font][font=宋体]等[/font][font=Times New Roman]. [/font][font=宋体]不同大豆材料的抗旱性鉴定及耐旱品种筛选[/font][font=Times New Roman][J].[/font][font=宋体]作物杂志[/font][font=Times New Roman],2019(5): 41-45.[/font][/font][font=宋体][font=Calibri][2] [/font][font=宋体]邬启帆[/font][font=Calibri]. [/font][font=宋体]基于基因组重测序黄淮海大豆育成品种遗传结构及重要家族遗传基础研究[/font][font=Calibri][D]. [/font][font=宋体]南昌[/font][/font][font=宋体][font=宋体]大学[/font][font=Times New Roman], 2023.[/font][/font][font=宋体][font=Calibri][3] [/font][/font][font=宋体][font=宋体]李伟宁[/font][font=Times New Roman],[/font][font=宋体]刘刚[/font][font=Times New Roman],[/font][font=宋体]周荣等[/font][font=Times New Roman]. MGISEQ-2000[/font][font=宋体]、[/font][font=Times New Roman]HiSeq 2000[/font][font=宋体]与[/font][font=Times New Roman]NovaSeq 6000[/font][font=宋体]平台全基因组重测序数据的比较分析[/font][font=Times New Roman][J]. [/font][font=宋体]中国畜牧杂志[/font][font=Times New Roman],2021,57(11):156-162.[/font][/font]
各位大神: 最近有个朋友跟我提到了一个测序电泳槽,想问问各位大神什么事测序电泳槽啊?它的工作原理是怎么样的,电泳基本知识我知道,但测序电泳它是如何实现测序和微卫星分析等等功能的?
最近,来自美国加利福尼亚大学圣地亚哥分校、克雷格·文特尔研究院和Illumina公司的科学家对现代基因测序算法进行了改良,只需从一个细菌细胞中提取的DNA(脱氧核糖核酸)就可组装成接近完整的基因组,准确率达到90%,而传统的测序方法至少需要10亿个相同的细胞才能完成。这一突破为那些无法培养的细菌提供了测序方法。研究发表在9月18日的《自然·生物技术》网络版上。 实验室无法培养的细菌范围极广,约占99.9%,从产生抗体和生物燃料的微生物,到人体内的寄生菌。它们的生存条件特殊,比如必须和其他菌种共生,或只能生存在动物皮肤上,因此很难进行人工培养。 论文合著者、文特尔研究院的罗杰·拉斯肯教授10年前曾开发出一种多重置换扩增(MDA)技术,可对实验室无法培养的细菌测序,能恢复70%的基因。其工作原理是对一个细胞的基因片断多次复制,直到其数量相当于10亿个细胞那么多。不过,这种技术却给测序软件带来很多麻烦,它在复制DNA时会出现各种错误,而且并非完全统一放大,有些基因组被复制数千次,有一些却只被复制一两次。但测序算法不能处理这些不一致,而是倾向于舍弃那些只复制了少数次的基因,即使它们对整个基因组来说很关键。 加州大学圣地亚哥分校雅各布工程学院计算机科学教授、现代基因测序技术算法创建人帕维尔·帕夫纳和同事改进了这一方法,保留了那些少量复制的基因片断,并用新方法对一个大肠杆菌测序以检验其精确性,发现它能恢复91%的基因,接近传统的培养细胞水平。这已足够解答许多重要的生物学问题,比如该细菌能产生什么抗体。 人体细菌占体重的约10%,它们有些会造成传染病,但也有的能帮助消化,最近研究还发现,它们能改变人的行为方式,比如引诱人吃更多的东西。新方法也有助于科学家理解细菌行为,研究人体内细菌能产生哪种蛋白质和多肽,这些蛋白质和多肽是细菌之间、细菌和宿主之间互相沟通的工具。 研究小组还用新方法对一种以前未曾测序过的海洋细菌进行了测序,获得了相当完整而且能解释的基因组,掌握了它是如何生存和运动的,该基因组将被存入美国国家卫生研究院的基因银行(GenBank)。研究人员表示还将对更多迄今未知的细菌进行测序。
[size=16px][color=#ff0000][b][url=https://www.instrument.com.cn/job/position-93012.html]立即投递该职位[/url][/b][/color][/size][b]职位名称:[/b]质谱分析岗位-郑州市[b]职位描述/要求:[/b]岗位职责:1.负责质谱仪器的管理2.负责串联质谱平台的测试分析3.负责研发相关项目的其他任务要求:1.熟练掌握质谱仪器2.能够对质谱数据分析,定量测定3.质谱测试质量控制、合规文件整理[b]公司介绍:[/b] 基因测序,代谢组学...[url=https://www.instrument.com.cn/job/position-93012.html]查看全部[/url][align=center][img=,178,176]https://ng1.17img.cn/bbsfiles/images/2021/08/202108160948175602_3528_5026484_3.png!w178x176.jpg[/img][/align][align=center]扫描二维码,关注[b][color=#ff0000]“仪职派”[/color][/b]公众号[/align][align=center][b]即可获取高薪职位[/b][/align]
性能介绍: 377型全自动遗传分析仪采用经典的聚丙烯酰胺凝胶的电泳方式,结合PE公司专利的四色荧光标记,激光检测的方法,具有测序精确度高,每个样品判读序列长(800-1200bp),一次电泳可测定样品数多(96个),快速方便,不需要同位素,测序方法灵活多样等特点,已成为全球应用最多最广的全自动DNA测序仪,尤其在人类基因组测序cDNA文库测序及比较基因组测序研究中应用极其广泛,此外377型全自动DNA测序仪在各种应用软件的辅助下,还可以进行DNA片段大小分析和定量分析,应用于基因突变分析SSCP,DNA指纹图谱分析(AFLP、RAPD、VNTR、STR),基因连锁图谱分析以及基因表达水平的研究,在临床遗传病、传染性病和癌症基因诊断、农业畜牧业的动植物育种、法医鉴定等领域有极其广泛的应用前景。 377型全自动遗传分析仪特点: 专利设计: 采用PE公司专利四色荧光标记,一个泳道测序的方法,避免单一标记(如:同位素标记)四个泳道测序因泳道间迁移率不同对精确度的影响,同时一个样品只占用一个泳道,使一次测定样品数目大大增加(至96个),因而具有精确度高,一次测定样品数多的特点。 测序能力强: 377型全自动遗传分析仪的荧光检测器采用激光激发、CCD摄像机同步成像技术,代表不同碱基信息的不同颜色荧光先经光栅分光,再经CCD摄像机成像,具有一次扫描可检测多种荧光的特点,测序速度高达200bp/小时,此外一个样品一次可测定800-1200个碱基,而同位素测序一次只能测定200-300个碱基。 电脑单点控制整个DNA测序仪的功能: 包括电泳参数设置,数据收集和分析以及结果输出。此外电脑可在电泳过程中对仪器运行状态进行同步监测,电泳结果也可以凝胶电泳图谱、荧光吸收峰图或碱基排列顺序等多种形式输出。新增加的用户界面卡功能强且简便易学,无论进行DNA序列分析还是DNA片段大小和定量分析,都可在各种软件辅助下方便地进行。 电泳的精确控温: 采用上下缓冲液环泵和温度检测器,使电泳温度恒定在51℃,这样可提高测序精度,调节温度,还可进行特殊应用研究,如:SSCP。此外采用恒定电压,而非恒定功率,可减少迁移率的变化,进一步提高电泳结果的重复性。 新改变的电泳胶板设计和电泳胶配方: 简化了灌胶操作,使灌胶更方便快捷,此外电泳胶的聚合可在最短的时间内完成。 测序方法灵活多样: 采用两种荧光染料标记方法(标记终止物ddNTP法和标记引物5'端法),两种DNA聚合酶(Sequenase和AmpliTaq),提供20钟测序试剂盒,可满足各种DNA模板(单链DNA,双链DNA,PCR产物)和测序策略(鸟枪法、缺失法、基因行走法)的要求。 丰富的应用软件: 有GeneScanTM、GenotyperTM、AutoAssemblerTM、Sequence NavigatorTM等软件,可进行DNA片段大小和定量分析,遗传基因的组型分析,DNA亚克隆序列拼接,DNA和蛋白序列比较。 多功能: 提供三种不同长度的凝胶电泳板,可根据对电泳时间和样品分辨率的不同要求选择,进行DNA序列分析,DNA片段大小分析(碱基分辨率可达1bp)和DNA片段定量分析(可检测从单一分子扩增的产物)。
美国加州的山景城是“硅谷”的重要组成部分。现在,一个与硅芯片相关的潜力大产业正在这里兴起,那就是基因组测序技术产业。这个产业的发展是随着多家大公司的激烈竞争开始的。不过,一家名为“整合基因”(Complete Genomics,CG)的公司不像别的公司一样研发和销售测序仪器,而是为科学家提供外包的测序服务,更绝的是,在这家公司里做测序的,并不是研究人员,而是一排排的机器人。近日,《新科学家》杂志探秘了这家充满科幻意味的公司。前台都是“机器人”走进CG公司,连前台都由计算机终端出任。它会主动向来客问好,询问姓名、身份和来访意图。旁边连接的一台打印机则自动打出访客挂牌。与此同时,一份电子邮件已经发送到内部接应人员的电脑上。这家公司的生产线更像科幻电影里的实验室,昏暗蓝色的房间里到处都是高级仪器,室内温度保持在28℃和相对较高的湿度,几名穿着实验服,带着发罩的工作人员在监视着电脑屏幕,查看着机器人的运作状态。这儿已经成为了世界上最大的人类基因组测序工厂。只是在这里工作的不是人类,而是机器人。在一个大约只有半个网球场大的房间里,“坐着”16台机器人,不间断地进行着人类基因组测序的工作。去年,它们完成800个人的DNA测序工作其中三分之一是后半年做出来的。到了今年,它们已经可以每个月生产出400个人的基因了。CG公司只是目前迅速形成产业的诸多基因组测序公司中的一家,但是它十分独特。公司市场总监图柯特(Jennifer Turcotte)对《新科学家》杂志解释说,通常而言,DNA测序是在一个密封的机器里进行的,但在这家公司的实验室里,机器人却是在一个开放暴露的环境下做基因组测序,这是为了便于维修。实验室特定的温度和湿度是为了符合测序中出现的生化反应,微弱的蓝光是为了避免荧光探测剂在探测基因代码符号时受到其他频率光波的破坏。这儿所进行的基因组测序,已是目前最新的第三代基因组测序技术,称为“DNA纳米球测序技术”。这种新方法是将DNA链放置在一小块硅芯片上进行调节,自我组装成所谓的“纳米球”。这样的测序所需要的试剂更少,得到的数据则更多。技术人员都穿着无尘室服装,因为任何一点灰尘都会干扰测序,除非哪儿出问题了,一般而言这些技术人员不会干预机器人的工作。机器人则会自动添加试剂,操作样本,每个DNA纳米球上携带着70个核苷酸,其排列顺序会通过光信号被拍摄记录下来。费用正在逐步降低这些机器人正在做的工作,是一个浩大庞杂的工程蓝图中的第一步,所有的人类基因组中有着30亿对碱基对,而CG计划将其全部组装出来。这需要非常大的计算量,公司为此也建了一个自动数据中心。不过,这个数据中心设在距离公司大约有20分钟车程的地方那儿的电费更便宜。目前CG公司只针对研究者和制药公司开放,个人还没法购买他们的服务。在这里,每对基因组测序要价9500美元,如果购买1000对以上,则每对价格降为5000美元。这个价格是随着基因组测序技术突飞猛进而急剧下降的,要知道,十年前,第一对人类基因组序列完成时,其价格是以十几亿美元计量的。而科学家现在已经预计几年后,基因组测序的价格可能会降到一般人都可能支付得起的程度。基因组测序的流水线完全是由机器人来做的,而职员做什么呢?公司共有185名职员,部分是科研人员,忙于改善公司的测序技术,另一部分则是做市场和联络,与各类客户打交道。基因组测序工程是一项既有非常光明的前途但又异常庞大的科学工程,而自动化则可能成为处理这项工作的最佳工具。基因学家们认为,通过一些基因扫描,是可以找到导致人类易感疾病的一些基因变异,人类基因谱上,有一些常见明显变异,但是就整个遗传问题来看,还有大量的混乱的遗传变异隐藏在DNA双螺旋体中,这些也导致了世界上千奇百怪的遗传疾病。如何去捕猎这些神秘莫测的错误基因代码呢?只剩下一个方法,那就是将整个人类基因谱测序,来捕捉一些可能和疾病有关的基因变异。这个方法虽然听上去如同“大海捞针”一样不靠谱,但目前一些迹象表明,今后或许基因组序列会成为医疗记录的一部分,或者科学家可以通过家庭的基因组测序来纠正基因错误。比如,去年西雅图系统生物学研究所的胡德(Leroy Hood)及其小组与CG公司进行了合作,在《科学》杂志上刊登了一篇论文。他们对一家四口的基因组进行了测序。这是个特殊的家庭,两个孩子都患有两种隐性遗传病米勒综合征和纤毛运动障碍,而父母则完全正常,在分别测出这家人的基因序列后,研究者将父母和子女基因组序列进行比较,验证了米勒综合征这种非常罕见遗传病的致病突变。提供测序外包的服务目前,站在基因组测序产业化起跑线上的企业包括了同样位于加州的生物科学公司Pacific Bio。这个公司创立了首次可以对单个DNA进行测序的仪器。和CG公司一样,目前,这家公司也只向研究者提供服务。有一些大型的、从事基因组测序产业的公司已经将基因组测序做到医院和个人普及的地步了,如研发制造大型测序分析仪器的Illumina公司。这个公司在2008年美国成长最快的科技公司评选中,风头甚至盖过了Google。它们提供的产品甚至可以直接给病人使用。而另一位基因创业企业家罗斯伯格(Jonathan Rothberg)甚至发明了可以放在桌子上的基因解码器,可以在2小时之内以很高的精度解读出1000万个基因代码符号。大部分的基因组测序企业都站在一个竞争线上,尽力提高DNA测序的速度,降低费用。而CG公司其实并非和它们是严格意义上的竞争对手他们计划组装出所有的人类基因序列,研发也是为此目的而进行。此外,他们并不如其他公司一样开发更高级更小巧的基因组测序仪,而是为科学家提供基因组测序的外包服务,也就是说,研究人员无需购买、安装、培训、运行和维修仪器,而只要将样品交给这家公司,等待结果到来就可以。虽然很多人不理解他们的做法,但这家公司始终坚持自己的观点,认为这样的服务最能让科学家将时间从捣腾仪器设备的工作中解放出来,专心放在生物学和假说验证上。从这几年CG公司取得的成绩来看,这种做法确实是有效的。2009年,CG公司宣布其测出了第一个人类基因序列,并移交给美国生物科技信息中心数据库。同一年,他们在《科学》上刊文,发布了三个完整人类基因组序列分析的结果,当时文章还宣布,测序的成本已经可以降到1726美元。这在生物界引起了轰动。到了那一年结束,他们已经做出了50个人的基因序列。此外,他们的名字也随着来自各地的科学家一起多次登上了权威学术杂志。除了去年帮助科学家解开了米勒综合征突变难题给科学界留下难忘的印象之外,美国的罗氏公司还曾经借助CG的基因组测序技术,完成了人类科学史上第一例肺癌患者的全基因组比较。相关研究结果刊登在《自然》杂志上。而美国癌症学会也开始和CG公司联手,希望通过其服务比较正常人和癌细胞基因组序列的差异。或许在不久的将来,解开癌症之谜的第一个贡献就属于这些蓝光照耀下的机器人。
无需进行文库制备,所用DNA样本比标准方法更少2012年12月13日 来源: 中国科技网 作者: 陈丹 中国科技网讯 据物理学家组织网12月12日(北京时间)报道,英国研究人员简化了基因组测序的标准流程,首次无需进行文库制备便完成了DNA(脱氧核糖核酸)单分子测序,而且新方法只要很少量的DNA就能获得序列数据,用量可低至不到1纳克(10亿分之一克),仅为常规测序方法的500分之一到600分之一。 文库制备是指从测序前基因组样本中提取不同长度的DNA片段,这一过程不仅费力、费时,还会浪费DNA,而新技术能极大地减少DNA的损耗,并缩短测序时间。 该研究论文的第一作者、英国威康信托基金会桑格研究所的保罗·库普兰说:“我们用这种方法对病毒和细菌的基因组测序后发现,即使在相对较低的水平,我们也能够确定所检测的是何种有机物,不论样本中是否存在特定的基因或质粒(这对于确定抗生素耐药性很重要),或者其他信息,如对特定DNA碱基的修改等。”他表示,一旦技术得到优化,将在快速、高效地识别医院和其他医疗场所中的细菌和病毒方面具有很大的应用潜力。 研究小组利用第三代单分子测序系统PacBio RS演示了这种简化的直接测序方法。他们仅仅用800皮克(千分之一纳克)DNA来分析一个生物体的基因组,尽管测序仪只读取了基因组的70个序列片段,相对于常规测序方法获得的数据来说不过是很小的一部分,但这些信息足以让研究人员确定他们所检测的生物体的品种。 这项技术也使得科学家能够对此前无法识别的宏基因组(也称微生物环境基因组)样本中的生物体进行确认。“为微生物测序,首先需要能够在实验室中培养它们。”论文的主要作者、英国巴布拉汉研究所的塔米尔·钱德拉说,“这不仅耗费时间,而且有时候微生物不生长,为它们的基因组测序极其困难。”他表示,新方法可以直接对微生物测序,短时间内便可确定其“身份”。 论文的另一主要作者、威康信托基金会桑格研究所的哈罗德·斯维尔德洛说:“我们的技术可以在对所测序列没有任何先验知识、没有特定微生物试剂的条件下,在很短的时间内操作,这是一种很有前途的替代手段,可应用于控制感染等临床需要。”(记者陈丹) 总编辑圈点 长久以来,基因测序等围绕基因科学所展开的研究,都被人们贴上了从本源上解开人体生命奥秘、彻底解除遗传疾病威胁等殷切的标签。多国为提高社会健康水平,都开展了解码国民DNA的活动,有些甚至覆盖全基因组。然而,面对由30亿个碱基对构成的人类基因组,精确测序注定将是一场浩大而又漫长的工程。如何能快速、准确地将海量DNA数据转化为有帮助的实用信息,已经成为该领域科学家们面临的重大挑战之一。因而我们说,英国科学家此番取得的突破,不管是从整个学科研究的方法论层面,还是从临床应用的角度,都提高了基因研究服务于人类的速度。 《科技日报》(2012-12-13 一版)
科技日报讯 (记者王怡)中国科学院北京基因组研究所和吉林中科紫鑫科技有限公司4月18日在长春联合召开国产新一代基因测序仪样机观摩研讨会,向与会的国内基因测序领域专家和应用单位代表展示这一合作成果,同时向社会公开征集部分应用单位进行免费测试使用,测试工作将于今年下半年开展。 据了解,新一代基因测序仪样机是目前唯一技术性可以匹敌国际市场主流产品的国产基因测序系统,与国外第二代高通量测序系统相比,已经成功解决“读长较短”这一关键技术难题。该基因测序仪已经达到和部分超越国际主流设备技术指标,其成本低于进口设备1/3以上,应用成本低于进口设备1/5以上,使新一代测序技术真正达到进入广泛应用市场的经济条件,并将彻底解决我国基因测序仪完全依赖进口的局面。截至目前,该系统已获得7个发明专利和1个实用新型专利授权,还有多项专利正在申报。 中科院北京基因组研究所研究员于军介绍,新一代基因测序仪对传染性疾病的预防控制和诊疗,生物恐怖因子、食源性致病因子和转基因成分鉴定,口岸卫生和有害生物防御性检疫,以及针对人类遗传多样性而产生的疾病早期预警和个体化用药相关基因的检测分析等实践应用,提供强有力的技术支持。 据悉,测序仪今年下半年将在医疗、检验检疫、疾病防控、高校、研究院所等20家应用单位进行免费测试使用。已经确认参加测试应用的单位包括中国检验检疫科学研究院、北京出入境检验检疫局、青岛海洋大学等10余家单位。测试工作主要包括对系统性能的优化和改进,以及根据应用领域的不同进行应用产品的共同开发,即在基础试剂产品的平台上衍生出一系列专用型试剂产品,并开发相应的数据分析算法和数据库,实现测序技术实践应用的全面解决方案。来源:中国科技网-科技日报 2014年04月20日
第三张“基因变异图谱”与第二代基因组测序技术——评“千人基因组计划”首期研究成果的医学意义世界上任意两个人的基因99%都是相同的,而恰是那1%不同,负责着个体间的表型差异。《自然》杂志近期披露,当人体内携带有250到300基因变异位点的时候,相关基因就就会“沉默”。甚至,一个人只携带了 50到100基因变异位点,就可能患上某种疾病。10年前,“人类基因组计划”这一耗资30亿美元、历时10余年的伟大科学工程完成之际,人们以为得到了揭开自身生命奥秘的天书,生命科学也划时代地进入了“后基因组时代”。如今看来,当时得到的仅仅是人类基因组的“参考图谱”,对于人群里个体间的基因差异,或是更具医学意义的“基因变异图谱”来说,人们知之甚少。第三张“基因变异图谱”为了探寻个体间的基因差异,科学界在2002年启动了HapMap(人类基因组单体型图谱)计划。Hapmap在2005年完成的“第一张基因变异图谱”含有一百万个“单核苷酸多态性”(SNPs)位点;HapMap在2008年完成的“第二张基因变异图谱”含有三百一十万个SNPs位点。而此次“千人基因组”所公布的一期结果——“第三张基因变异图谱”,已经包含了一千五百万个SNPs位点。今年10月28日,《自然》杂志为此刊出的文章题目为“基于群体规模的基因变异图谱”,鲜明的指出,“千人基因组计划”首期研究成果,其最大优势在于:“第三张基因变异图谱”所采用的样本,针对了“大规模人群”。 远超过此前两张“基因变异图谱”所测定的样本数。绘制“第三张基因变异图谱”的所有数据,是基于两个核心家庭,6个个体的精确基因组测序,179个个体的低覆盖率基因组测序,以及七百多人的蛋白编码区的基因测序。检测人群数目庞大,人种涉及中国人、日本人、西欧人等。因此,第三张“人类基因变异图谱”的问世,可以从更深的层次上了解,种族之间、个体之间的基因差异。更具医学意义的是,对于人群中发生频率在1%以上的基因变异,本次研究的覆盖率达到95%以上。这就意味着:此前Hapmap计划所绘制的两张“基因变异图谱”中,没能涉及的“罕见病”致病基因,可能在“第三张基因变异图谱”中已经被标出。“基因变异图谱”的医学应用随着,“人类基因变异图谱”绘制的日臻完善,和商业化全基因组SNP 分型芯片成本的不断降低,以及新的统计方法和软件的出现, “全基因组关联分析”( Genome-Wide Associat ion Study , GWAS) 越来越多的应用于复杂疾病“易感基因”的确定。今年6月6日,安徽医科大学的张学军教授领衔的团队,通过对中国汉族和维吾尔族人群近2万份样本进行分析,在人类基因组的3个区域内发现与白癜风发病密切相关的4个易感基因。今年8月2日,中***事医学院贺福初院士领衔的蛋白质组学国家重点实验室,通过对大陆5个肝癌高发区的4500多名肝癌病例和对照的研究,发现了肝癌易感基因新区域(1p36.22)今年8月23日,新乡医学院的王立东教授联合国内18家医院,建立了数十万份的食管癌标本资料库,并首次在人类第10号和20号染色体上,发现两个食管癌易感基因(PLCE1和C20orf54)。基因变异有着很强的人种差异,相比国外此领域的研究成果,以上研究成果的临床意义,在于其是针对我国的特有人群。也就是说,以上研究成果在我国的临床上更具医学价值。更为可喜的是,以上研究成果均发表在此领域最为权威的《自然 遗传学》杂志上。我国在利用GWAS需找复杂疾病易感基因领域的研究,已经得到了世界的公认。
MinION试用计划于本周一(11月25日)启动,将延续到2014年初,具体截止日期未定。根据这项试用计划,参与者须支付1,000美元的押金以及运费,而后将收到一台MinION测序仪,包括测序USB装置、流动槽和软件。在上个月的美国人类遗传学协会年会上,英国Oxford Nanopore Technologies公司宣布将启动MinION测序仪的试用计划。这次,它果然没有食言。MinION试用计划于本周一(11月25日)启动,将延续到2014年初,具体截止日期未定。根据这项试用计划,参与者须支付1,000美元的押金以及运费,而后将收到一台MinION测序仪,包括测序USB装置、流动槽和软件。除了MinION测序仪,Oxford Nanopore还在开发GridION测序仪。之前,该公司一直没有公布这两款测序仪的具体性能参数,但鉴于许多客户有意了解,它最近在网站上回答了一些常见问题。GridION和MinION系统的通量如何?据介绍,GridION系统是可以扩展的。它既可以单独作为一台仪器工作,又可以多台连接,带来更快的结果。至于仪器的通量,它会受到各种因素的影响,包括DNA的处理速度以及芯片上同时开展的实验数量。第一代商业化的仪器每天可产生几十Gb。目前的cartridge每次可开展2000个纳米孔实验,而更高配置(每次开展8000个实验)正在开发中。MinION系统是个一次性的设备,每次可开展数百个纳米孔实验,运行时间为数小时。运行时间如何?Oxford Nanopore表示没有固定的运行时间,这要取决于实验需求。由于全长的读取数据是实时流出的,故也能实时分析。初步分析可在每台仪器(节点)上本地开展,而二次分析可在用户的网络上并行开展。因此,MinION和GridION节点可持续运行,直到收集了足够的数据来回答实验问题。系统的读长是多少?据介绍,纳米孔测序仪是处理提交给它的DNA,而不是“产生”读长。它能够处理非常长的读长,大约几十kb。GridION和MinION系统的费用如何?相信这也是大家最关心的问题。Oxford Nanopore表示,GridION技术的定价不同于传统的系统。它是一个套餐,包括节点和cartridge耗材。这些套餐可满足不同需求及不同预算的客户。例如,有些客户可能有比较多的经费,而另一些则在耗材花费上更为自由;定价将让这两种类型的客户都能使用。此外,GridION系统的定价将比目前市场上的其他系统都要低。此系统是模块化的,用户可不断添加。无需服务器,因为每个节点都包含了所需的计算硬件。而且,定价透明,可在线下单。大的套餐也会有透明的折扣。对于MinION系统,零售价预计在900美元以下。不过,目前还未开始接受订单。
基因测序的基本原理是边合成边测序。在Sanger等测序方法的基础上,通过技术创新,用不同颜色的荧光标记四种不同的dNTP,当DNA聚合酶合成互补链时,每添加一种dNTP就会释放出不同的荧光,根据捕捉的荧光信号并经过特定的计算机软件处理,从而获得待测DNA的序列信息。
质谱解析程序质谱解析程序 解析未知样的质谱图,大致按以下程序进行。(一)解析分子离子区 (1) 标出各峰的质荷比数,尤其注意高质荷比区的峰。 (2) 识别分子离子峰。首先在高质荷比区假定分子离子峰,判断该假定分子离子峰与相邻碎片离子峰关系是否合理,然后判断其是否符合氮律。若二者均相符,可认为是分子离子峰。 (3) 分析同位素峰簇的相对强度比及峰与峰间的Dm值,判断化合物是否含有C1、Br、S、Si等元素及F、P、I等无同位素的元素。 (4) 推导分子式,计算不饱和度。由高分辨质谱仪测得的精确分子量或由同位素峰簇的相对强度计算分子式。若二者均难以实现时,则由分子离子峰丢失的碎片及主要碎片离子推导,或与其它方法配合。 (5) 由分子离子峰的相对强度了解分子结构的信息。分子离子峰的相对强度由分子的结构所决定,结构稳定性大,相对强度就大。对于分子量约200的化合物,若分子离子峰为基峰或强蜂,谱图中碎片离子较少、表明该化合物是高稳定性分子,可能为芳烃或稠环化合物。 例如:萘分子离子峰m/z 128为基峰,蒽醌分子离子峰m/z 208也是基峰。分子离子峰弱或不出现,化合物可能为多支链烃类、醇类、酸类等。(二)、解析碎片离子 (1) 由特征离子峰及丢失的中性碎片了解可能的结构信息。 若质谱图中出现系列CnH2n+1峰,则化合物可能含长链烷基。若出现或部分出现m/z 77,66,65,51,40,39等弱的碎片离子蜂,表明化合物含有苯基。若m/z 91或105为基峰或强峰,表明化合物含有苄基或苯甲酰基。若质谱图中基峰或强峰出现在质荷比的中部,而其它碎片离子峰少,则化合物可能由两部分结构较稳定,其间由容易断裂的弱键相连。 (2) 综合分析以上得
解析未知样的质谱图,大致按以下程序进行。(一)解析分子离子区 (1) 标出各峰的质荷比数,尤其注意高质荷比区的峰。 (2) 识别分子离子峰。首先在高质荷比区假定分子离子峰,判断该假定分子离子峰与相邻碎片离子峰关系是否合理,然后判断其是否符合氮律。若二者均相符,可认为是分子离子峰。 (3) 分析同位素峰簇的相对强度比及峰与峰间的Dm值,判断化合物是否含有C1、Br、S、Si等元素及F、P、I等无同位素的元素。 (4) 推导分子式,计算不饱和度。由高分辨质谱仪测得的精确分子量或由同位素峰簇的相对强度计算分子式。若二者均难以实现时,则由分子离子峰丢失的碎片及主要碎片离子推导,或与其它方法配合。 (5) 由分子离子峰的相对强度了解分子结构的信息。分子离子峰的相对强度由分子的结构所决定,结构稳定性大,相对强度就大。对于分子量约200的化合物,若分子离子峰为基峰或强蜂,谱图中碎片离子较少、表明该化合物是高稳定性分子,可能为芳烃或稠环化合物。 例如:萘分子离子峰m/z 128为基峰,蒽醌分子离子峰m/z 208也是基峰。分子离子峰弱或不出现,化合物可能为多支链烃类、醇类、酸类等。(二)、解析碎片离子 (1) 由特征离子峰及丢失的中性碎片了解可能的结构信息。 若质谱图中出现系列CnH2n+1峰,则化合物可能含长链烷基。若出现或部分出现m/z 77,66,65,51,40,39等弱的碎片离子蜂,表明化合物含有苯基。若m/z 91或105为基峰或强峰,表明化合物含有苄基或苯甲酰基。若质谱图中基峰或强峰出现在质荷比的中部,而其它碎片离子峰少,则化合物可能由两部分结构较稳定,其间由容易断裂的弱键相连。 (2) 综合分析以上得到的全部信息,结合分子式及不饱和度,提出化合物的可能结构。 (3) 分析所推导的可能结构的裂解机理,看其是否与质谱图相符,确定其结构,并进一步解释质谱,或与标准谱图比较,或与其它谱(1H NMR、13C NMR、IR)配合,确证结构。
以下问题是我摘抄的,当时记在我的记录本上,所以没有记下名字,很是抱歉。但是我想拿出来这是对大家的一种共享,所以祈求大家原谅。Q:我将PCR产物纯化后送测,结果说是双模板,测序峰重叠,请问是模板不纯吗?A:应该指的是模板不纯。可能是割胶纯化时,范围偏大,非目的基因片断亦混入其中。该非目的片断的大小与目的片断也类似。如果片断长度大的话,可以先连一下克隆载体,这样测序应该没有问题。 测序峰重叠不知道你讲的时双峰类型的还是指比较杂乱的而且无序的重叠: 如果是双峰(TP),有可能是标本来源是杂合子的缘故,如果是后者,原因很多,一般看打印出的测许结果大致可以判断。原因:1。有时候PCR产物可能就是失败的产物或者浓度很低。2.提纯不好,非目的片段保留。3.测序时Matrix等条件的错误。Q:测序结果不好,测序峰比较乱,基线不平,测许公司说含有复杂结构,现急需要该序列,请问高手这种情况该怎么办?有什么测许方法?A;我自己曾经亲自做过测序,对于这种情况,一般是有解决的方法的。不过公司不愿意为了你自己的一个样品去专门摸索条件。1. 最大可能是提取的质粒不纯,可以将质粒再次转化后挑单克隆重做(很奏效)。2. 直接在测序前的模板热变性使用86度,5分钟而不是大多数的96度3分钟3. 实在不行切后分别放到T载体上,一般都可以保证顺利读出序列。最后值得一提的是如果能自己根据理论序列给设计几个比较合理的测序引物可能一切就OK了。Q:上星期将我的PCR纯化产物拿到TAKARA测序,结果今天公司打电话来说测了100多个bp就读不下去了,建议我克隆后再测,我的PCR产物纯化只有很亮的一条带,不知道为什么测不出来。答:测不下去的原因主要是序列里面有困难序列,二级结构或短序列重复,比如发卡结构和AT长重复等,甲基化的影响不大清楚,本人认为不会影响测序。所以,PCR产物测不下去的话,克隆后也很难保证测过去。其实就测序来说,PCR产物还是质粒都无所谓,只要样品纯可以了。正向测不通反向再测也可能会测通,因为DNA中正链和反链二级结构不是完全一样的,正链中遇到困难序列在反链中可能相对简单,测序酶可能可以急需合成DNA。另外,还可以改一下测序PCR的反映条件等等,也可以测通。
DNA 序列分析技术是现代生命科学研究的核心技术之一,而双脱氧核苷酸链终止法(Sanger法)是目前使用最普遍的DNA 序列分析技术。在基于Sanger法的全自动DNA 测序技术中,测序反应产生的DNA 片段是荧光标记的,这些片段经过平板胶电泳或毛细管电泳得到分离,荧光分子被激发而发光,发出的光信号被检测系统检测。Sanger法的优势在于可以分析未知DNA 的序列,且单向反应的读序能力较长,目前的技术可以达到1000bp以上。 在实际工作中,很多情况需要对已知序列的DNA 片段进行序列验证,而这种分析往往测几十bp就可以满足需要.在这种情况下,Sanger法未必是最合适的DNA序列分析技术。新发展的Pyrosequencing(焦磷酸测序)技术应该是目前最适合这些应用的DNA序列分析技术。Pyrosequencing技术是新一代DNA 序列分析技术,该技术对DNA 的序列分析无须进行电泳,DNA 片段无须荧光标记,因此相应的仪器系统无须荧光分子的激发和检测装置.本文将就Pyrosequencing技术的原理和应用进行介绍和讨论.一、Pyrosequencing技术的原理首先通过PCR制备待测序的DNA模板,PCR的引物之一是用生物素标记的。PCR产物和偶连avidin的Sepharose微珠孵育,DNA双链经碱变性分开;纯化得到含生物素标记引物的待测序单链,并和测序引物结合成杂交体。Pyrosequencing技术是由四种酶催化的同一反应体系中的酶级连反应,四种酶是:DNA聚合酶(DNA polymerase)、硫酸化酶(ATP sulfurylase)、荧光素酶(luciferase)和双磷酸酶(apyrase).反应底物为adenosine 5´ phosphosulfate (APS)、荧光素(luciferin)。反应体系还包括待测序DNA单链和测序引物。反应体系配置好后就可以加入底物dNTP进行序列分析了。测序反应是这样进行的:在每一轮测序反应中,只能加入四种dNTP(dATP S,dTTP,dCTP,dGTP)之一,如该dNTP与模扳配对,聚合酶就可以催化该dNTP掺入到引物链中并释放焦磷酸基团(PPi)。掺入的dNTP和释放的焦磷酸是等摩尔数目的.注意:反应时deoxyadenosine alfa-thio triphosphate (dATP S)是dATP的替代物,因为DNA聚合酶对dATP S的催化效率比对dATP的催化效率高,且dATP S不是荧光素酶的底物。硫酸化酶催化APS和PPi形成ATP,ATP和焦磷酸的摩尔数目是一致的。ATP驱动荧光素酶介导的荧光素向氧化荧光素(oxyluciferin)的转化,氧化荧光素发出与ATP量成正比的可见光信号。光信号由CCD摄像机检测并由pyrogram™反应为峰。每个峰的高度(光信号)与反应中掺入的核苷酸数目成正比。ATP和未掺入的dNTP由双磷酸酶降解,淬灭光信号,并再生反应体系。然后就可以加入下一种dNTP。 Pyrosequencing技术的原理: 随着以上过程的循环进行,互补DNA链合成,DNA序列由Pyrogram的信号峰确定。商品化的Pyrosequncing试剂盒通过以下几点来保证反应的有效进行:底物浓度已最佳化,高质量的三磷酸腺苷双磷酸酶保证了所有的dNTP被降解,包括ATP和dATPαS;dNTP降解速率慢于掺入速率,有利于dNTP充分掺入;ATP合成速率快于ATP水解速率,使的ATP浓度和光产生正比于掺入的dNTP数目。有必要指出的是:Pyrosequencing技术可以确定一个模板的20-30bp的序列。有的研究者经过改进而使该技术的读序长度增加一倍以上。为了增加信噪比,在Pyrosequencing技术中,用dATPαS取代dATP,因为dATPαS可以比dATP被DNA聚合酶更有效利用,也更有利于阅读富含T的区域,且dATPαS不是荧光素酶的底物。但dATPαS是两种异构体SpdATPαS和RpdATPαS的混合物,聚合酶只能利用SpdATPαS。因此,为了得到最佳反应效率,必需使反应体系中保持最佳浓度的SpdATPαS,但同时增加了相应浓度的无用的RpdATPαS。dATPαS被双磷酸酶降解后的产物是双磷酸酶的抑制剂,所以随着反应进行,被双磷酸酶降解的dATPαS的降解产物浓度越来越大,双磷酸酶的活性越来越低。这可能是Pyrosequencing技术测序长度很短(20-30bp)的主要原因之一。新的革新就在于在反应体系中只加入SpdATPαS,这样一来可以大大降低dATPαS降解产物的浓度,维持双磷酸酶较长时间的活性。目前这个革新可以使Pyrosequencing技术的测序长度增加最少一倍,达到50至上百bp。







 我要推广仪器
我要推广仪器
 下载APP
下载APP