求助大家有没有知道用unscramber软件做PLSR多变量图的教程
ARL,SPECTRO,OBLF内置的校准曲线也均是通过多变量回归数学模型建立的吧,如何通过多变量回归数学模型建立校准曲线?大家从数学及物理的角度谈谈对多变量回归的理解。
分析工作中接触到的化学试剂一般都是少量的,易处理。但如果有大量化学试剂倾覆到地面,像氢氟酸、硝酸类的,应该如何处理?欢迎大家发表自己的看法。
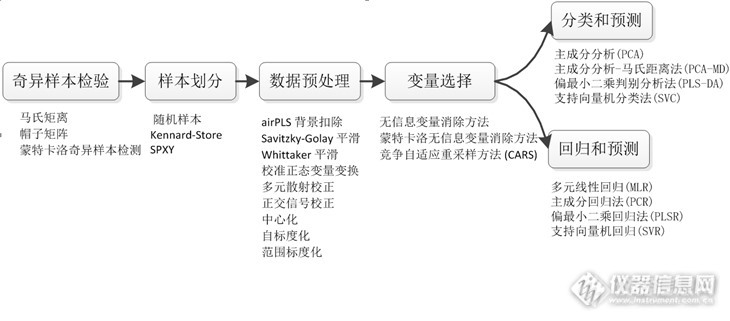
化学计量学建模步骤 梁逸曾教授在Modern Scietific Instruments 1998里的《化学计量学》一文中把化学计量学概括为,"化学计量学运用数学、统计学、计算机科学、以及其他相关学科的理论与方法,优化化学量测过程,并从化学量测数据中最大限度地获取有用的化学信息,可以说是一门化学量测的基础理论与方法学"。 从定义可以了解到,化学计量学主要是帮助我们从各种化学量测手段即不同的仪器获得的数据转化为有用的信息,这些有用的化学信息才是用户终极目标。故化学计量学在整个化学量测过程中起到至关重要的作用,而最终硬件结合软件的运用才可以最大化化学测量仪器的作用。 随着现代的仪器的发展,量测仪器获得的数据日趋复杂,从单变量到多变量,从一维到多维的发展,还有很多其他干扰因子的影响,化学计量学也变成了一个复杂的建模过程,而不是简单的化学方程式可以解决的。 一般我们建立一个化学计量学模型,我们要求模型稳健、可靠和精度高。能满足这些要求已经很不简单了,因为数据中不可避免存在的噪音、背景、漂移、颗粒大小影响。下面通过分子光谱的建模过程进行讲解:如下图所示,是整个建模过程和所用到的经典方法http://ng1.17img.cn/bbsfiles/images/2013/08/201308200859_458687_2761650_3.png 建模之前血建模之前需要对偏离整体的一些奇异样本进行剔除以保证模型的稳健性;为了检验模型的有效性应该对样本划分为训练集和预测集需要的样本划分的方法;数据中不可避免存在的噪声、背景、漂移、颗粒大小影响等问题或者多元校正方法中需要的标度化方法等需要有数据预处理方法;为建立稳健和更加简洁的模型中需要的变量选择的方法;最终是为预测未知物中感兴趣的指标的回归和对未知物类别归属的多元校正方法。 简单的来说可以这样理解每个建模的步骤,奇异样本检验,是看在整个建模的样本中有没有坏的样本,如果坏的样本进入建模集,会使得模型失真;而样本划分是为把数据分为建模子集和预测子集,预测子集是用来检测模型建立的好坏的;数据预处理就是解决仪器的不理想不可避免的一些随机误差的影响;变量选择是提取特征,使得模型更加清晰;分类是模式识别,如检测真假,或检测类别的归属等;回归是定量化学信息的含量等。 如果对图中算法感兴趣的,算法详细的介绍在附件里,请查阅,若有疑问可以一起交流探讨。
定量化学分离方法》.pdf

[align=center][color=#ff0000][b][b]号外![/b][img]https://simg.instrument.com.cn/bbs/images/default/em09505.gif[/img]号外![b][img]https://simg.instrument.com.cn/bbs/images/default/em09505.gif[/img][/b][/b][/color][/align][align=center][b][color=#ff0000]日立多变量分析软件3D SpectAlyze免费试用活动来啦!!![/color][/b][/align][align=center]为荧光光谱、液相色谱等数据解析而特别开发![/align][align=center]申请免费试用时间:[color=#ff0000]6月1日-7月1日![/color][/align][align=center]还有各种[b][color=#000099]精美礼品拿哈![/color][/b][/align][align=center]还等什么,赶紧戳以下活动页面申请吧![/align][align=center]或点击活动链接:[url]https://www.instrument.com.cn/zt/3DSpectAlyze[/url][/align][align=center][url=https://www.instrument.com.cn/zt/3DSpectAlyze][img=,690,293]https://ng1.17img.cn/bbsfiles/images/2020/05/202005261825126372_6202_2817550_3.png!w690x293.jpg[/img][/url][/align]
基于计量化学——GCMS研究
定量化学分析(第二版).pdf
定量化学分析(李龙泉).pdf
定量化学分析(许晓文).pdf
定量化学分析实验(胡伟光).pdf
哪位大虾谁有胡伟光主编的《定量化学分析实验》,请给本人发一份电子版的。本人邮箱chchipkh@163.com。十分感谢。
什么时候不能使用TMS作为测量化学位移的基准?
书上说:只有建模后才能了解建模所需变量数,从而进一步了解建模所需校正集样品数。如果建模需要3个以下(包括3个)的变量,那么去掉异常点后,校正集至少应有24个样品。我看的有点糊涂,既然先建模才能确定样品数,那我之前应该用多少样品建模?!
FZ/T 01026-1993 四组分纤维混纺产品定量化学分析方法[img]http://www.instrument.com.cn/bbs/images/affix.gif[/img][url=http://www.instrument.com.cn/bbs/download.asp?ID=178558]FZT 01026-1993 四组分纤维混纺产品定量化学分析方法.pdf[/url]
GBT 2910.1-2009 纺织品 定量化学分析 第1部分:试验通则[img]http://www.instrument.com.cn/bbs/images/affix.gif[/img][url=http://www.instrument.com.cn/bbs/download.asp?ID=181876]GBT 2910.1-2009 纺织品 定量化学分析 第1部分:试验通则.rar[/url]
棉/粘纤混纺产品定量化学分析的方法探讨Study on Quantitative Analysis of Cotton/ Viscose Blend Products文/瞿彩莲 董激文 胡红花 朱梦滢 卞敏摘要:文章对棉/粘纤混纺产品的定量化学分析方法进行了探讨,对JIS、AATCC标准中硫酸法溶解棉/粘纤混纺产品的测试方法进行了研究和实践,同时确定了不同试验条件下棉纤维的实际质量修正系数。关键词:棉;粘纤;定量分析;硫酸法Abstract: The article studied the quantitative analysis of cotton and viscose blend products, and compared the JIS and AATCC standard for using sulfuric acid method, and determined the quality correction coefficient of cotton fiber under different experimental conditions.Keywords: cotton; viscose; quantitative analysis; sulfuric acid method1引言粘胶纤维与棉的化学性质相似,而物理性能各有优缺点。两者混纺可以弥补双方的不足,并充分发挥各自优点,其产品既改善了纯棉产品的手感、光泽和悬垂性能,又保留了棉纤维特有的吸湿、透气等舒适性,因而受到消费者青睐。在贸易和使用过程中,纤维含量是不可缺少的重要性能指标,同时也是消费者购买纺织品时的关注点。有些服装生产企业为了提高面料的档次,往往在成分标识中有意提高天然纤维的比例,导致纤维成分的标注与实际不符。因此,正确检验、标注纺织品纤维含量对保护消费者的利益,维护生产者的合法权益,保障纺织品质量安全,提高正当竞争促销手段有着重要的意义。一直以来,由于粘纤与棉的化学性能有很大的相似之处,两者混纺产品的定量化学分析方法和试验条件等都备受检测人员关注。目前,国内主要依据GB/T 2910.6—2009 《纺织品 定量化学分析 第6部分 粘胶纤维、某些铜氨纤维、莫代尔纤维或莱赛尔纤维与棉的混合物(甲酸 氯化锌法)》进行测试。但在实际操作中,试验人员注意到甲酸/氯化锌法常常出现粘纤溶解不充分,剩余物呈糊状,过滤时很困难,检验结果有较大偏差等问题。此外,甲酸/氯化锌在高温下容易挥发出有毒物质,其溶液配制和整个溶解过程也都需要严格把关。相比之下,JIS L 1030-2和AATCC 20A中选用的60%(59.5%)的硫酸法在实际检测中具有比较好的溶解效果和相对简便的操作方法。但这两个标准的具体操作也存在不同之处,两者的质量修正系数存在较大差异。本文对这两种标准进行了研究,尝试确定一种较准确、实用的测试方法。2试验原理及方法2.1试验原理用60%(59.5%)的硫酸把粘纤从已知干燥质量的棉/粘纤混合物中溶解去除,收集残留物,清洗、烘干和称重,用修正后的质量计算棉占混合物干燥质量的百分率,再由差值得出粘纤的质量百分数。2.2试验方法2.2.1试样GB/T 3921《纺织品 色牢度试验 耐皂洗色牢度》规定的棉标准贴衬布;GB/T 3921《纺织品 色牢度试验 耐皂洗色牢度》规定的粘纤标准贴衬布。织物必须拆成纱线,并剪成1 cm长,每份试样0.5~1.5 g。如有必要,试样需经过预处理,如去油剂处理、退浆和褪色处理等。2.2.2仪器主要包括:分析天平(精确到0.1 mg),烘箱(恒定在105~110℃),干燥器(装有变色硅胶),恒温震荡水浴锅,真空抽气泵,有塞三角瓶(容量250 mL)、玻璃砂芯坩埚、称量瓶,1000 mL量筒,2000mL烧杯,密度计,水银温度计等。2.2.3试剂60%(59.5%)的硫酸:用量筒量取密度为1.84 g/mL的浓硫酸1000 mL,缓慢加入到盛有1100 mL的蒸馏水中的烧杯中,在20℃时,利用密度计调整硫酸溶液的密度在1.4950~1.4982g/mL之间。稀氨水:取氨水20 mL(密度为0.880g/mL)用水稀释到1L。2.2.4试验方法及过程方法一,参照AATCC 20A的测试过程:将已称重的试样放入三角烧瓶中,以1:100的比例加入59.5%硫酸,盖紧瓶塞,强烈震荡1 min,在15~25℃保持15 min,然后取出震荡,再保温15 min,取出再次震荡;在抽气泵上用已知干重的坩锅过滤出未溶解物质,用59.5%的硫酸冲洗,再用水冲洗,然后用稀氨水中和清洗并浸泡残留纤维10 min,再用冷水冲洗,用抽气泵抽干,将坩锅和残留物质放入烘箱烘至恒重,冷却、称重。方法二,参照JIS L 1030-2的测试过程:将已称重的试样放入三角烧瓶中,以1:100的比例加入已温热的60%硫酸,盖紧瓶塞,摇动烧瓶,在室温下震荡10 min,然后静置5 min,再继续震荡5 min。在抽气泵上用已知干重的坩锅过滤出未溶解物质,用60%硫酸冲洗,再用水清洗,然后用稀氨水中和清洗并浸泡残留纤维10 min,再用冷水冲洗,用抽气泵抽干,将坩锅和残留物质放入烘箱烘至恒重,冷却、称重。3试验结果3.1结果的计算本试验结果的考察采用净干含量百分率的计算。P1 = (1)P2 = 100-P1 (2)式中:P1—不溶纤维的净干含量百分率,% ;P2—溶解纤维的净干含量百分率,% ;m0—溶解前试样的干重,g;m1—溶解后残留物的干重,g;d—不溶纤维在试剂处理时的质量修正系数。d值的计算:将纯棉试样经过相同的试验方法和过程,得到剩余纤维干重与原重之比的倒数,即:d = (3)式中:m0—溶解前试样干重,g;m1—溶解后试样干重,g。3.2数据记录3.2.1两种试验方法中d值的确定 用棉标准贴衬布分别制取10个1 g左右的试样,按2.2.4所述两种方法用硫酸溶液进行溶解,计算得出棉纤维的实际质量修正系数(d值),详见表1。表1 棉纤维的实际质量修正系数试样方法一方法二溶解前试样干重溶解后试样干重d值溶解前试样干重溶解后试样干重d值10.86510.85031.01740.93520.91191.025620.7984
这是我总结中南大学梁逸曾教授的一次讲座《智能光谱分析的前景展望》的内容,和大家分享下 近红外光谱,拉曼光谱,紫外可见光谱,LIBS(激光诱导击穿光谱技术,laser induced breakdown spectroscopy),X-射线荧光谱等,都是目前光谱分析出现的新型快速无损分析的新工具。借助化学计量学,它们在复杂体系的定性定量分析及模式识别和模式分析中提供了最新的光谱分析新仪器。不同光谱反映了不同样本层次的分子信息:外可见:分子中电子跃迁能量谱;红外、拉曼与近红外:分子的振动-转动光谱;X-射线荧光谱:样本中样本中原子分布信息;LIBS:样本中元素分布信息,等 一般说来,常用的波谱(包括紫外可见、红外光谱、近红外光谱、拉曼光谱、LIBS谱、质谱和核磁共振谱)包含了样本中化学物种的结构与特征信息。不同的化学物质一般都有不同的波谱,而这些差别将为以多变量分析为基础的化学计量学提供新的机遇。智能光谱分析的新任务 1)样本的多变量定性分析 这样的例子就是不同种类的中药材(或植物物种的化学分类与鉴别)分类与真伪鉴别,天然香精香料提取物的分类与鉴别,不同疾病患者的代谢组学分析,不同土壤,不同纤维,不同烟草及卷烟等的识别。对于这些样本的分析,人们不在乎是否能对其进行穷尽的化学组分定性定量分析,而主要追求样本之间整体性(包括共同性与差异性)分析,可对不同样本进行区分并进而找到区分样本之间的主要化学因素(或特征变量,或生物化学标志物),化学计量学为此提供了相应的基于多变量的解析方法,这些方法亦将是我们主要进行讨论的复杂体系的分析方法,也为智能光谱分析提供了新思路。 2)谱学的多变量定量分析 农产品中的不同种类的粮食或烟草中的蛋白质、脂肪、糖类的总量分析,原先大都采用化学分析方法来完成,都耗时耗力;另外,人们往往不是对样本中某种化学物质的定量感兴趣,而是关注该样本的某一性质和特质,如能源化学中汽油的辛烷值(或油品标号)、食品化学中的某种感官定量指标、不同的塑料制品的鉴别等。这些也都有一些传统的方法进行测量,大都耗时耗力或主观性太强。值得提出的是,一般象这样的化学分析,其结果都是有很多因素共同形成,不是由某单个化合物决定。随着仪器分析进入实验室,大都趋向于采用既无损且简便的方法来替代原有分析方法,由于化学计量学中主成分回归(PCR)和偏最小二乘(PLS)多变量解析方法的引入,使得对这些样本的快速分析成为可能。 人们采用多变量的波谱分析(主要是近红外光谱,红外光谱、拉曼光谱、 LIBS,质谱,NMR等)来替代原先的传统分析方法,继采用PCR、PLS或其他多变量解析方法(包括支撑向量机、人工神经网络)来校正建模,以达到快速分析的结果。注意到,这类样本的分析并不只局限于对某种化合物的定性定量,它们是多种化学物质的综合效应,故其校正模型不确定(线性或非线性未知,无有类似Lambert-Beer定律作为其分析校正基础),波谱中的响应变量亦不能确定,且它还需要用原先传统化学或物理方法所得的定量数据来作为标竿建模,这类样本实质上也是一种复杂多组分体系。对此类体系的定量分析也可通过借助化学计量学进行快速定量分析,并此技术已得到了十分广泛的实际应用。……………………很多图文的例子,不一一述说,大家详细看附件的PPT吧
[font='Times New Roman'][font=宋体]波长变量[/font][/font][font=宋体]([/font][font='Times New Roman'][font=宋体]光谱原始变量)是指在一定波长范围内采集样品的近红外数据时,如[/font]780~2,500nm[font=宋体],若仪器的扫描间隔为[/font][font=Times New Roman]1nm[/font][font=宋体],则将获得含有[/font][font=Times New Roman]1,721[/font][font=宋体]个数据点的光谱数据,每个数据点即为一个变量,称为波长变量,此处共计有[/font][font=Times New Roman]1,721[/font][font=宋体]个变量。当采集[/font][font=Times New Roman]m[/font][font=宋体]个样本的近红外数据时,则相同条件下将获得一个大小为[/font][font=Times New Roman]m × 1,721[/font][font=宋体]的数据矩阵[/font][/font][b][font='Times New Roman']X[/font][/b][font='Times New Roman'][font=宋体],以表征[/font]m[font=宋体]个样本[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]量测[/font][/font][font=宋体]的[/font][font='Times New Roman'][font=宋体]变化,即样本化学[/font][/font][font=宋体]组成[/font][font='Times New Roman'][font=宋体]及其浓度的差异性和相似性。但对[/font]m × 1,721[font=宋体]的高维数据空间,无法在[/font][font=Times New Roman]2[/font][font=宋体]维或[/font][font=Times New Roman]3[/font][font=宋体]维的低维空间中可视化展示样本间的相关性。[/font][font=Times New Roman]PCA[/font][font=宋体]是在尽可能少[/font][/font][font=宋体]的[/font][font='Times New Roman'][font=宋体]损失数据[/font][/font][font=宋体]矩阵[/font][b][font='Times New Roman']X[/font][/b][font='Times New Roman'][font=宋体]中[/font][/font][font=宋体]信息[/font][font='Times New Roman'][font=宋体]的情况下,线性变换数据后将[/font]1,721[font=宋体]维高维空间降至少量的低维空间,如[/font][font=Times New Roman]2[/font][font=宋体]或[/font][font=Times New Roman]3[/font][font=宋体]维,且保证不同维度间相互正交,实现数据的可视化表达[/font][/font][font=宋体],[/font][font='Times New Roman'][font=宋体]此低维空间的维度数量,即为主成分数[/font][/font][font=宋体](或称主元数、主因子数)[/font][font='Times New Roman'][font=宋体]。通常地,选择主成分数,取决于它们可累计原始光谱数据总方差的百分比。同样地,[/font]PLS[font=宋体]分析可获得类似的变换空间维度,称为潜变量[/font][/font][font=宋体][font=宋体](或称隐变量)[/font][font=Times New Roman],[/font][/font][font='Times New Roman'][font=宋体]与[/font]PCA[font=宋体]中主成分的区别在于,[/font][font=Times New Roman]PLS[/font][font=宋体]分解中获得潜变量时,同时考虑对浓度矩阵[/font][/font][b][font='Times New Roman']C[/font][/b][font='Times New Roman'][font=宋体]的分解,即[/font][/font][font=宋体]在[/font][font='Times New Roman'][font=宋体]解过程中,[/font][/font][b][font='Times New Roman']X[/font][/b][font='Times New Roman'][font=宋体]矩阵和[/font][/font][b][font='Times New Roman']C[/font][/b][font='Times New Roman'][font=宋体]矩阵[/font][/font][font=宋体]交互[/font][font='Times New Roman'][font=宋体]信息用于对方的分解。概括来说,波长变量(光谱原始变量)是针对近红外量测原始数据来说的,而[/font]PCA[font=宋体]的主成分数,以及[/font][font=Times New Roman]PLS[/font][font=宋体]潜变量则分别为[/font][font=Times New Roman]PCA[/font][font=宋体]和[/font][font=Times New Roman]PLS[/font][font=宋体]分解后得到的新的线性变换特征。[/font][/font]
[em09508] 各位好!向你们请教个问题啊!FZ/T01026-93四组分纤维混纺产品定量化学分析方法标准中,其中附录A给出了方案1分析的修正系数,请问这些修正系数是怎么算出来的?如果我碰到一个四组分的产品,而又不在附录A范围之内,那修正系数怎么来呢?谢谢!
[font=宋体]波长点或者波段选择方法能够提高校正集的预测精度,但是,从全部波长变量中选择一部分可能会导致有用信息的丢失。并且光谱中含有噪声水平较高的波长或者波段也可能含有某些与预测物结构相关的信息,单纯删掉这些波长,可能在某种程度上破坏模型多通道的特点。因此,变量加权的方法是从另一个角度重新审视波长选择方法。按变量的重要性给变量赋予非负连续变化的权重,就是变量加权的方法。从加权的角度来说,波长点或波段选择方法可以看作被选择的波长权重为[/font][font='Times New Roman']1[font=宋体],而被删除的波长权重为[/font][font=Times New Roman]0[/font][font=宋体]。因此,波长选择只是变量加权的一种特殊情况,或者说变量加权是对波长选择方法的一种扩展。变量加权的策略可以与各种多元校正方法相结合,如偏最小二乘回归或者[/font][/font][font=宋体][font=Times New Roman]S[/font][/font][font='Times New Roman']VR[font=宋体]等,也就发展了下面具体的算法。[/font][/font][b][font='Times New Roman']1. [/font][font=宋体]变量加权[/font][font='Times New Roman']-[/font][font=宋体]偏最小二乘回归[/font][/b][font=宋体]变量加权[/font][font='Times New Roman']-[font=宋体]偏最小二乘法([/font][font=Times New Roman]VW-PLS[/font][font=宋体])[/font][/font][sup][font='Times New Roman'][[/font][/sup][sup][font=宋体][font=Times New Roman]52[/font][/font][/sup][sup][font='Times New Roman']][/font][/sup][font=宋体]就是将原光谱中的每个变量都乘以一个权重,加权后的光谱与浓度之间建立偏最小二乘模型。其中变量权重的选取是[/font][font='Times New Roman']VW-PLS[font=宋体]方法的关键。[/font][/font][font=宋体]它[/font][font='Times New Roman'][font=宋体]使用粒子群全局优化算法来计算每个变量的权重。[/font][/font][font=宋体][font=Times New Roman]P[/font][/font][font='Times New Roman']SO[font=宋体]的优化目标函数是校正集的预测残差平方和与预测集的预测残差平方和的均方根。一个含有和变量个数相等的元素都为[/font][font=Times New Roman]1[/font][font=宋体]的向量[/font][/font][font=宋体]以[/font][font='Times New Roman'][font=宋体]及[/font]99[font=宋体]个随机产生的非负向量在一起作为最初的解。经过不断迭代,得到每个变量的权重。该方法用于肉类及药片的[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]数据,结果表明,该方法能得到比[/font][font=Times New Roman]PLS[/font][font=宋体]更好的预测效果。[/font][/font][b][font='Times New Roman']2. [/font][font=宋体]变量加权最小二乘[/font][font='Times New Roman']-[/font][font=宋体]支持向量机法[/font][/b][font=宋体]与[/font][font='Times New Roman']VW-PLS[/font][font=宋体]方法类似,变量加权最小二乘[/font][font='Times New Roman']-[font=宋体]支持向量机法([/font][font=Times New Roman]VWLS-SVM[/font][/font][font=宋体])[/font][sup][font='Times New Roman'][[/font][/sup][sup][font=宋体][font=Times New Roman]53[/font][/font][/sup][sup][font='Times New Roman']][/font][/sup][font=宋体]给每个变量赋予一个权重,变量权重和[/font][font='Times New Roman']LS-SVM[font=宋体]的超参数也通过粒子群优化算法来实现。该方法用每个波长变量乘以权重后的光谱数据与浓度之间建立[/font][font=Times New Roman]LS-SVM[/font][font=宋体]模型,然后[/font][/font][font=宋体],[/font][font='Times New Roman'][font=宋体]对预测集进行预测。该方法用于肉类及柴油的[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]数据,并与[/font]PLS[font=宋体]、[/font][font=Times New Roman]UVE-PLS[/font][font=宋体]和[/font][font=Times New Roman]LS-SVM[/font][font=宋体]的进行比较,结果表明,该方法能提高模型的预测能力。该方法对光谱中含有严重噪声、非线性[/font][/font][font=宋体]响应和[/font][font='Times New Roman'][font=宋体]有[/font][/font][font=宋体]参考值分布范围窄[/font][font='Times New Roman'][font=宋体]的数据尤其适应。[/font][/font][b][font='Times New Roman']3. [/font][font=宋体]迭代预测变量权重[/font][font='Times New Roman']-[/font][font=宋体]偏最小二乘回归法[/font][/b][font=宋体]迭代预测变量权重[/font][font='Times New Roman']-PLS[font=宋体]法([/font][font=Times New Roman]IPW-PLS[/font][font=宋体])[/font][/font][sup][font='Times New Roman'][54][/font][/sup][font=宋体][font=宋体]的核心是在[/font][font=Times New Roman]P[/font][/font][font='Times New Roman']LS[/font][font=宋体]过程中将变量的光谱乘上它们的重要性([/font][font='Times New Roman']0-1[/font][font=宋体]之间),随着多次迭代计算,重要性数值较小的波长点对应权重逐步趋向零,最后从模型中删除,只保留有意义的重要变量。但是,由于[/font][font='Times New Roman']IPW-PLS[/font][font=宋体]算法在每次迭代过程中都是基于全部波长点计算,如果波长点数目过多,会比较耗时。[/font]
FZ/T 01132-2016纺织品 定量化学分析 维纶纤维与某些其他纤维的混合物 标准电子版?
FZT 01026-2009 纺织品 定量化学分析 四组分纤维混合物
FZ/T 01026-2017纺织品 定量化学分析 多组分纤维混合物 将于2017年10月1日实施?为什么还找不到标准呢?大家谁拿到这个标准,分享一下?
GB∕T 40912-2021 纺织品 定量化学分析 聚酰胺酯纤维与某些其他纤维的混合物标准?也就是一个新标准,有资料说简称仪纶,大家看看怎么有见过这个成分的吗?
GBT 2910.3-2009 纺织品 定量化学分析 第3部分:醋酯纤维与某些其他纤维的混合物(丙酮法)[img]http://www.instrument.com.cn/bbs/images/affix.gif[/img][url=http://www.instrument.com.cn/bbs/download.asp?ID=181877]GBT 2910.3-2009 纺织品 定量化学分析 第3部分:醋酯纤维与某些其他纤维的混合物(丙酮法).pdf[/url]
FZT 01134-2016 纺织品 定量化学分析 芳砜纶与某些其他纤维的混合物,这个芳砜纶是什么纤维?哪位老师有样品吗?
GBT 2910.19-2009 纺织品 定量化学分析 第19部分:纤维素纤维与石棉的混合物(加热法)[img]http://www.instrument.com.cn/bbs/images/affix.gif[/img][url=http://www.instrument.com.cn/bbs/download.asp?ID=181913]GBT 2910.19-2009 纺织品 定量化学分析 第19部分:纤维素纤维与石棉的混合物(加热法).pdf[/url]
GBT38015-2019纺织品定量化学分析,氨纶与其他纤维混合物此标准2020.3.1号正式实施,请大家注意,论坛资料库已有这个标准,欢迎大家下载交流!
GBT2910.15-2009纺织品 定量化学分析 黄麻与某些动物纤维的混合物-含氮量法,这个标准有谁做过,我做了一次没有做成功?







 我要推广仪器
我要推广仪器
 下载APP
下载APP