量子化学——基本原理和从头计算法(上、中、下册)[img]http://www.instrument.com.cn/bbs/images/affix.gif[/img][url=http://www.instrument.com.cn/bbs/download.asp?ID=15593]量子化学——基本原理和从头计算法(上、中、下册)[/url]

[size=16px][font=-apple-system, BlinkMacSystemFont, &][color=#05073b]大米外观品质检测仪的原理是什么[/color][/font]大米外观品质检测仪的原理主要是基于光学技术和图像处理算法。首先,这种检测仪会使用特定的光源来照射大米样品。通常,这种光源是白光或近红外光,能够提供足够的亮度和适当的波长范围。选择合适的光源对于检测仪的准确性和稳定性至关重要。其次,检测仪的传感器能够接收被照射的大米样品反射回来的光信号,并将其转化为电信号。这些电信号包含了大米样品的光谱信息,可以反映出大米的颜色、透明度、纹理等特征。然后,图像处理算法会对传感器采集到的光谱信息进行处理,得到大米样品的图像。这些算法能够对图像进行分割、滤波、增强等操作,以提取出大米样品的特征信息。最后,通过数据分析,检测仪可以评估大米样品的外观品质。例如,可以通过颜色的均匀性、透明度的一致性、纹理的清晰度等指标来评判大米的品质。总之,大米外观品质检测仪是一种利用光学技术和图像处理算法来评估大米外观品质的设备。通过对大米外观进行图像分析,它可以确定大米的色泽、形态、大小等外观特征,从而评估大米的外观品质。[img=,690,690]https://ng1.17img.cn/bbsfiles/images/2023/11/202311061009502850_6383_6098850_3.jpg!w690x690.jpg[/img][/size]
想用遗传算法进行光谱的波长选择,遗传算法的原理算是搞得差不多了,又看了一些相关的论文,有以下问题望大家指教:1、遗传算法的实现一般是通过Matlab工具箱实现还是自己编程实现,见有的文章说用Vc自己编写的;有没有建模软件自带遗传算法的,我用的TQ Analyst软件是不带的。2、求最优解的过程应该是自动实现的过程,而最优解的确定又是通过模型有关参数决定的,这应该要求针对每个解(即选择的不同波长组合)都要建立一次模型,以便得到模型的相关参数。若不是建模软件自带遗传算法,而是借助matlab或自己编程实现,那么由不同波长组合得到不同参数的整个自动实现过程如何完成的?不知道自己这样理解有没有错误,接触近红外分析时间不长,有错误的地方望大家批评指正,先谢谢了!
k-means算法:其计算原理和步骤
[font=-apple-system, BlinkMacSystemFont, &][size=15px][color=#05073b] 大米加工精度检测仪检测原理是什么,大米加工精度检测仪的检测原理主要基于先进的光电传感技术、计算机图像分析技术和图像处理算法。以下是具体的检测原理: 样品准备与图像采集:首先,将待检测的大米样品放入检测仪中。检测仪内置的高分辨率摄像头会捕捉大米的图像,获取大米颗粒的详细视觉信息。 图像预处理:采集到的原始图像可能会受到光照、噪声等因素的干扰,因此需要进行预处理。预处理步骤可能包括去噪、增强对比度、调整亮度等,以提高图像质量,便于后续分析。 图像分析与特征提取:经过预处理后的图像会被送入计算机图像分析系统。该系统运用专业的图像处理软件对每一粒大米进行细致分析,识别并区分出完整米粒、破损米粒和稻谷皮屑等。这个过程中,系统还会提取出大米的形状、大小、颜色等关键特征参数。 数据处理与精度评估:根据提取的特征参数,系统会计算出各项精度参数,如整精米率、碎米率、留皮率等。这些参数反映了大米在加工过程中的处理效果,从而评估大米的加工精度。 结果输出与报告生成:最后,检测仪会将检测结果以数字或图表的形式输出,并生成详细的检测报告。这些报告可以作为大米品质评估和质量控制的重要依据。 总之,大米加工精度检测仪通过先进的光电传感技术、计算机图像分析技术和图像处理算法,实现了对大米加工精度的快速、准确检测。这种检测方式不仅提高了生产效率,而且确保了检测结果的客观性和准确性。[img=,690,690]https://ng1.17img.cn/bbsfiles/images/2024/05/202405241041170528_5667_6098850_3.jpg!w690x690.jpg[/img][/color][/size][/font]
[em01] 有人知道仪器最低检测极限的算法是什么不?比如给定一个仪器的某个参数,可以计算其能够检测的最低极限谢谢一楼
[font=&][color=#666666]希尔伯特-黄变换(Hilbert-Huang Transform,HHT)是一种适用于处理非线性和非平稳信号的自适应方法。着重探讨了该算法在应用中可能出现的模态混叠问题,分析了其产生的机理和目前的研究进展。针对微试剂光谱水质检测数据中希尔伯特-黄变换存在的模态混叠问题,结合顺序注射微试剂水质在线检测技术,提出了一种微试剂水质光谱在线检测改进型HHT算法。这种改进方法采用EEMD来分析信号,有效地解决了传统HHT中EMD分解时出现的模态混叠问题,从而提高了信号分解的性能。通过改进型HHT算法与传统HHT算法水质光谱检测效果对比,研究结果表明,改进型HHT算法处理相较于基础型在校正决定系数上提高了31.78%,三种不同浓度总氮的RSD都有显著增加。与HHT算法相比,该方法有效解决了经验模态分解方法存在的模态混叠问题,同时也提高了微试剂水质光谱在线检测系统的准确性与稳定性,为微试剂水质光谱信号的准确测量提供了一种新思路。[/color][/font]
[size=16px][color=#ff0000][b][url=https://www.instrument.com.cn/job/position-78514.html]立即投递该职位[/url][/b][/color][/size][b]职位名称:[/b]机器视觉算法工程师[b]职位描述/要求:[/b]一、岗位职责:1.负责研发机器学习、模式识别、深度学习算法开发,应用于图像识别和分类;2.负责物体(纤维)检测、识别等相关计算机视觉算法在纺织行业的应用和需求;3.参与项目和产品需求的相关算法分析、集成和优化;4.评估和测试算法可行性及监控算法效果,根据用户需求进行分析改进;5.负责与嵌入式工程师协作,搭建算法模块;6.关注计算机视觉算法前沿技术与创新使用场景相结合的研发和工程实现。二、任职要求:1.硕士及以上学历(博士优先),计算机科学、信息工程、电子工程、机器人学等专业; 2.两年以上机器学习、机器视觉算法模型训练的工作经验3.在模式识别、机器学习、深度学习、计算摄影、图像处理等领域有深入认识,并了解各个算法的条件和瓶颈;4.熟悉图像处理基本方法(边缘检测,区域提取,低通滤波,特征提取,交点检测,二值化等),有OpenCV或者类似图形库开发经验 5.熟练掌握CNN, RCNN, ResNet等深度学习相关算法和模型,熟悉深度学习计算框架包括Tensorflow, MXNET, Caffe在内的其中一种;6.精通python或C++其中一种编程语言,有CUDA编程经验者优先;7.在相关领域主流会议或期刊发表过论文(CVPR/ICCV/ECCV/NIPS/ICML/ICLR/IROS/ICRA/SIGRAPH)者优先;8.具有良好的沟通和写作能力,积极主动,具有创业热情;9.熟练的英文文献阅读能力,具有较强的论文复现能力。三、公司和产品简介LabWorld 是一家高科技分析仪器及应用解决方案开发公司,旨在利用数字化、大数据、人工智能等技术使得科研、检测人员的实验过程更省时、结果更准确、人力成本更低。LabWorld 的核心研发合作伙伴是荷兰 Sioux Technologies 公司,同时 Sioux 也是荷兰光刻机巨头 ASML 以及美国 Thermo Fisher Scientific 高端仪器的核心和关键研发供应商之一。经过近几年对动物纤维识别市场需求的潜心调研,Labworld 于 2020 年推出了其最新的动物纤维智能检验设备 Fiber ID,一款基于机器视觉和深度学习原理,基于光学显微镜的羊毛羊绒自动数量、质量检测设备,目前 Fiber ID 正在国内各大羊毛羊绒生产商处(例如鄂尔多斯)进行最终测试,得到了非常优异的结果与正面的反馈。现在我们正在寻找杰出的人才以担任动物纤维智能检验设备的【机器视觉算法工程师】这一重要的角色! 希望这一角色进行机器学习、模式识别、深度学习算法开发,应用于Fiber ID图像识别和分类;满足纤维检测、识别等视觉算法在纺织行业的应用和需求;助力产品的优化迭代和人工智能在纺织行业的深度应用!网站:www.labworld-scientific.com[b]公司介绍:[/b] 聚焦台式电镜,致力电镜普及为研发工作者赋能,让我们一起 Free to Achieve复纳科学仪器(上海)有限公司于2012年成立,为高校、科研院所、政府和企业提供荷兰飞纳Phenom(现所属Thermo Fisher Scientific 赛默飞世尔科技)台式扫描电子显微镜(SEM)。该产品技术先进,市场占有率达80%,目前在中国拥有1000多家用户。2017年起,复纳与荷兰 S...[url=https://www.instrument.com.cn/job/position-78514.html]查看全部[/url][align=center][img=,178,176]https://ng1.17img.cn/bbsfiles/images/2021/08/202108160948175602_3528_5026484_3.png!w178x176.jpg[/img][/align][align=center]扫描二维码,关注[b][color=#ff0000]“仪职派”[/color][/b]公众号[/align][align=center][b]即可获取高薪职位[/b][/align]
以下是对德国Rothermundt SM5皮带张力检测仪器的详细介绍: 一、产品概述 德国Rothermundt SM5皮带张力检测仪器是一款专为工业皮带系统设计的张力测量工具。该仪器融合了先进的传感器技术和精密的测量算法,能够准确测量并显示皮带系统的张力状态,为设备的维护和调整提供可靠的数据支持。Rothermundt SM5广泛应用于汽车制造、纺织化纤、电线电缆、金属加工、塑料薄膜、纸张印刷等多个行业,成为这些行业进行皮带系统维护和调整的重要工具。 二、产品特点 高精度测量:Rothermundt SM5采用先进的传感器技术和精密的测量算法,确保测量结果的准确性和可靠性。其高精度测量能力能够满足工业生产中对皮带张力的高精度要求,为用户提供准确的数据支持。 广泛适用性:该仪器适用于多种类型的皮带,包括同步带、V型带、平皮带等,能够适用于不同的工业设备和生产线。这种广泛的适用性使得Rothermundt SM5能够满足不同用户的需求,提高设备的运行效率。 易于操作:Rothermundt SM5的设计简洁直观,操作界面友好。用户无需专业培训即可快速上手,实现高效测量。同时,仪器配备有指示灯和不同的声音信号,能够实时显示测量结果,方便用户进行监控和调整。 耐用性强:采用高品质材料和精密制造工艺,Rothermundt SM5具有较长的使用寿命和稳定的性能。它能够在恶劣的工业环境下稳定运行,如高温、高湿、粉尘等恶劣条件,确保测量的准确性和可靠性。 数据记录与分析:Rothermundt SM5可能具备数据记录和分析功能,支持用户将测量结果导出至电脑或移动设备,进行进一步的数据处理和分析。这有助于用户更好地了解皮带系统的运行状态,制定更合理的维护和调整计划。 三、测量原理与范围 Rothermundt SM5皮带张力检测仪器通过先进的传感器技术实时测量皮带的张力状态。其测量范围可能因皮带类型和尺寸的不同而有所差异,但一般来说,能够覆盖常见的皮带张力范围。测量精度方面,Rothermundt SM5具有高精度测量能力,具体数值可能因产品型号和测量条件而异,但通常能够满足工业生产中对精度的高要求。 四、总结 德国Rothermundt SM5皮带张力检测仪器以其高精度测量、广泛适用性、易于操作、耐用性强和数据记录与分析等特点,在皮带张力测量领域具有显著优势。无论是在哪个行业或领域,它都能为用户提供准确、可靠的测量结果,帮助用户监控和调整皮带系统的运行状态,确保设备的高效稳定运行。
重叠峰分离的方法有很多,比如:傅立叶变换、偏最小二乘法等。这里介绍一种卡尔曼滤波算法。卡尔曼滤波器是一个“optimal recursive data processing algorithm(最优化自回归数据处理算法)”。对于解决很大部分的问题,他是最优,效率最高甚至是最有用的。他的广泛应用包括机器人导航,控制,传感器数据融合甚至在军事方面的雷达系统以及导弹追踪等等。近年来更被应用于计算机图像处理,例如头脸识别,图像分割,图像边缘检测等等。具体的算法,因为极其复杂,所以不在这里罗列,感兴趣的可以去搜索相关资料。这里演示一下镍铜合金中的一个案例:http://ng1.17img.cn/bbsfiles/images/2017/03/201703051157_01_1780790_3.png图中镍的Kb峰、铜的Ka峰和锌的Ka峰、铜的Kb峰存在重叠。谱峰分离效果如图。通过众多的样品测试分析,卡尔曼滤波算法对于重叠程度低于90%的,分离效果相当好,对于重叠程度大于90%而小于95%的有一定误差,而超过95%的基本就无能为力。由于信号采集的问题,光谱有时会出现整体漂移,这也可以通过采用一定软件算法进行校正。在校正前需要指定一个正常的谱,然后通过神经网络算法进行学习。测试其它样品时如果发现有漂移就会计算出漂移距离,再进行校正。本人已编写出上述功能的代码模块,需要技术交流的可联系我13926563756 qq:648048428
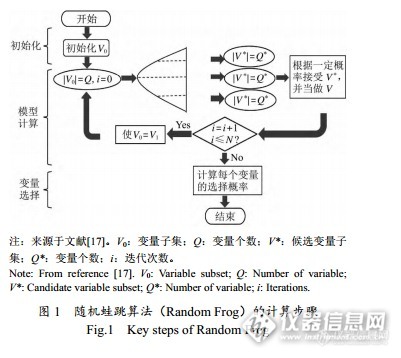
以下内容摘自文献《可见-近红外光谱联合随机蛙跳算法检测生物柴油含水量》陈立旦等|农业工程学报Random Frog 是一种新型特征波段算法。其能够利用少量的变量迭代进行建模,是一种非常有效的高维数据变量选择方法。它能够输出每个变量选择可能性,从而进行变量的选择。图 1 表示 Random Frog 算法的计算步骤,其主要的运算步骤包括以下 3 步:1)一个变量子集 V0,初始化时包含 Q 个变量;2)基于原始的变量子集,提出一个候选变量子集 V*,包含 Q*个变量;选择 V*作为 V1 来代替原始的变量子集 V0。直到 N 次迭代终止,这个过程完成。3)最后计算每个变量的选择概率并以此作为选择变量的标准。http://ng1.17img.cn/bbsfiles/images/2015/05/201505261131_547524_2542239_3.jpgP.S 附国外文献一篇《An efficient method of wavelength interval selection based on random frog for multivariate spectral calibration》
基于相关算法的目标跟踪是利用从以前图像中获得的参考模板,在当前图像中寻找最相似的区域来估计当前目标位置的方法。它对于背景复杂、会有杂波噪声的情况具有良好的效果。CCD(电荷耦合器件)测量技术是近年来发展迅速的一种非接触式测量技术。CCD摄像器件在分辨率、动态范围、灵敏度、实时传输方面的优越性是其它器件无法比拟的,在动态飞行目标跟踪测量中发挥着重要的作用。作者在CCD测量系统中使用相关匹配的方法,实现了对连续视频图像中动态目标的跟踪。1 CCD误差测量系统原理在同一观测位置布置两台CCD,其视轴平行。其中CCD1用于瞄准,CCD2用于跟踪飞行目标。CCD1瞄准线和视轴重合,获得瞄准线和靶标之间的偏差角α。CCD2获得飞行目标和靶标之间的偏差角β。系统要求得到瞄准线和飞行目标之间的水平和垂直方向上的偏差角ψx、ψy。因此规定CCD的视场中均以靶标十字中心为原点,向左和向上为正方向,将α、β分别投影到坐标轴上得到水平和垂直方向上的偏差角αx、αy、βx、βy。两台CCD的视频轴平行,视轴间距远远小于CCD到目标的距离,因此可以认为两CCD的视轴重合。所以有:ψx=αx-βx,ψy=αy-βy (1)图1是系统的原理图,图中靶板上的黑十字是靶标,虚线十字为瞄准分划板在靶板上的投影(由于实际靶板上没有,所以用虚线表示)。2 图像处理算法的选择从系统的原理分析可知,要完成偏差角度的测量首先应当从图像中提取出各个目标在图像中的位置,再根据CCD当量(每像元对应的弧度数)算出水平和垂直方向的偏差角。从CCD1的图像中的最靶标十字和瞄准分划板的位置,从CCD2的图像中提取靶标十字和飞行目标的位置。由于飞行目标几乎贴地飞行,CCD视场中有复杂的地面背景。而且靶标是不发光的暗目标,与背景灰度反差不大,很难将目标从背景中分离出来,因此只有采用相关处理技术来进行目标识别,才能实现瞄准误差和飞行轨迹的测量。相关算法非常适合在复杂背景下识别和跟踪运行目标。由于系统图像处理是事后处理,处理连续的大量视频图像,实时性要求不高,而对处理精度和自动处理程度要求较高,因此采用该算法。本系统中相关处理将预先选定的目标或目标特定位置作为匹配样板,求取模板和输入图像间的相关函数,找出相关函数的峰值及所在位置,求判断输入图像是否包括目标图像及目标位置。3 相关算法的原理及改进在机器识别事务的过程中,常把不同传感器或同一传感器在不同时间、成像条件下对同一景物获取的两幅或多幅图像在空间上对准,或根据已知模式在另一幅图像中寻找相应的模式,这就叫做匹配。如果被搜索图中有待寻的目标,且同模板有一样的尺寸和方向,在图像匹配中使用相关匹配,就是通过相关函数找到它及其在被搜索图中的位置。3.1 相关算法基于相关的目标跟踪寻找最佳匹配点,需要一个从以前图像中得以的模板。在图2中设模板T为一个M×M的参考图像,搜索图S为一个N×N图像(MN),T在S上平移,模板下覆盖的那块搜索图叫做子图Si,j,(i,j)为子图左上角点在S中的坐标,叫参考点。比较T和Si,j的内容。若两者一致,则它们的差为0。用误差的平方和作为它们相似程度的测度:展开公式(2),则有: 公式(3)右边的第三项表示模板的总能量,是一个常数。第一项是模板覆盖下的子图能量,随(i,j)位置而缓慢改变。第二项是子图和模板的互相关,随(i,j)改变。当模板和子图匹配时刻值最大。因此可以用以下相关函数做相似性测度: 根据柯西-施瓦兹不等式可知公式(4)中0R(i,j)≤1,并且仅在Si,j(i,j)/[T(m,n)]为常数时,R(i,j)取最大值(等于1)。相关法求匹配计算量很大,如图2所示的情况,要在(N-M+1)×(N-M+1)个参考位置上做相关计算,每次相关计算要做3M2次加法、3M2次乘法、1次除法、2次开方运算。由于乘除法运算量最大,整个算法的时间复杂度大约为o((N-M+1) ×2×(3M2+1))。整个运算过程中,除了匹配点一点以外,都是在非匹配点上做无用功。但是,模板匹配算法准确度较高,适合对大量的连续视频图像做自动处理。 还有更多的仪器资料,我在这里就不添了,大家感兴趣的话到这个网站上去下载吧!http://www.yiqi120.com/zlzxInfo.asp?id=1678
请教一个关于fft算法的问题,DFT算法与FFT算法在应用上有什么区别?
[table=641][tr][td]Type[/td][td]ID[/td][td]Name[/td][td]Comments[/td][/tr][tr][td]Classification[/td][td]1[/td][td]Fisher [/td][td]线性判别分类器[/td][/tr][tr][td]Classification[/td][td]2[/td][td]Logistic 对数几率回归[/td][td]1.IRLS(Newton-Raphson)Iteratively reweithted LS 迭代加权最小二乘; 2.Gradient Ascent梯度上升; 3.Stochastic Gradient Aescent (随机梯度下降,大规模数据,online);[/td][/tr][tr][td]Classification[/td][td]3[/td][td]K-Nearest Neighbor(KNN)[/td][td] K-最近邻分类器[/td][/tr][tr][td]Classification[/td][td]4[/td][td]Naï ve Bayes[/td][td] 朴素贝叶斯分类器[/td][/tr][tr][td]Classification[/td][td]5[/td][td]Soft Independent Modelling of Class Analogy(SIMCA) [/td][td]簇类独立软模式分类器[/td][/tr][tr][td]Classification[/td][td]6[/td][td]Perceptron 感知机(二元线性分类器)[/td][td]1.Standard(online); 2.Pocket(online); 3.Batch;[/td][/tr][tr][td]Classification[/td][td]7[/td][td]Decision Tree-C4.5决策树[/td][td]Gain Ration增益率[/td][/tr][tr][td]Classification[/td][td]8[/td][td]Decision Tree-ID3决策树[/td][td]Information Entropy信息熵[/td][/tr][tr][td]Classification[/td][td]9[/td][td]Multinomial Logistic(Softmax) [/td][td]多类别逻辑回归[/td][/tr][tr][td]Classification[/td][td]10[/td][td]NN前馈神经⽹ 络/ MLP 多层感知机[/td][td]1.Back Propagation(BP误差逆传播算法); 2.Stochastic Gradient Descent (随机梯度下降SGD),大规模数据; 3.Sequence 4.Mini-Batch; 5.Batch; 6.Nesterov动能法Nesterov’s momentum method(SGD with Monentum);[/td][/tr][tr][td]RC[/td][td]11[/td][td]CART分类与回归树[/td][td]二叉树,连续变量,最小二乘回归树, 平方误差最小,离散变量: Gini Index基尼系数[/td][/tr][tr][td]RC[/td][td]12[/td][td]Partial Least Squares(PLS)[/td][td]偏最小二乘法(PLSR,PLSA)[/td][/tr][tr][td]RC[/td][td]13[/td][td]Support Vector Machine(SVM) [/td][td]支持向量机(SVMR,SVMC)[/td][/tr][tr][td]RC[/td][td]14[/td][td]Gaussian Process [/td][td]高斯过程 (GPR, GPC)[/td][/tr][tr][td]Regression[/td][td]15[/td][td]Multiple Linear Regression(MLR)[/td][td]多元线性回归[/td][/tr][tr][td]Regression[/td][td]16[/td][td]Principal Component Regression(PCR) [/td][td]主成分回归[/td][/tr][tr][td]Regression, DR[/td][td]17[/td][td]Ridge Regression [/td][td]岭回归(L2约束)[/td][/tr][tr][td]Regression, DR[/td][td]18[/td][td]Forward Stagewise linear regression(FSW) [/td][td]向前逐段回归,类似RR[/td][/tr][tr][td]Regression, DR[/td][td]19[/td][td]Least Angle Regression(LARS)[/td][td]最小角回归[/td][/tr][tr][td]Regression, DR[/td][td]20[/td][td]LASSO套索(L1约束)[/td][td]Lasso回归主要的解法: 1.ADMM交替方向乘子法Alternating Direction Method of Multipliers(拉格朗日方求解L1约束,大规模问题); 2.最小角回归法( Least Angle Regression)LARS; 3.坐标下降法(Coordinate Descent) ; 4.近点梯度法Proximal Gradient; 5.Nesterov动能法Nesterov’s momentum method; 6.优化-最小化算法Minorization-Maximization;[/td][/tr][tr][td]Regression, DR[/td][td]21[/td][td]Elastic Net弹性网(L1+L2约束)[/td][td]Coordinate Descent坐标下降法[/td][/tr][tr][td]Regression, DR[/td][td]22[/td][td]Kernel Ridge Regression[/td][td]核岭回归[/td][/tr][tr][td]Cluster[/td][td]23[/td][td]K-Means[/td][td]K均值聚类[/td][/tr][tr][td]Cluster[/td][td]24[/td][td]FCMeans[/td][td]模糊C均值聚类[/td][/tr][tr][td]Cluster[/td][td]25[/td][td]GA-FCM[/td][td]基于遗传算法的模糊C均值聚类[/td][/tr][tr][td]Cluster[/td][td]26[/td][td]GA-K-Means [/td][td]基于遗传算法的K均值聚类[/td][/tr][tr][td]Cluster[/td][td]27[/td][td]PSO-K-Means [/td][td]基于粒子群算法的K均值聚类[/td][/tr][tr][td]Cluster[/td][td]28[/td][td]ACO-K-Means [/td][td]基于蚁群算法的K均值聚类[/td][/tr][tr][td]Cluster[/td][td]29[/td][td]TS-K-Means [/td][td]基于禁忌搜索算法的K均值聚类[/td][/tr][tr][td]Cluster[/td][td]30[/td][td]IA-K-Means [/td][td]基于免疫算法的K均值聚类[/td][/tr][tr][td]Cluster[/td][td]31[/td][td]Density-Based Spatial Clustering of Application with Noise(DBSCAN)[/td][td]密度聚类[/td][/tr][tr][td]Cluster[/td][td]32[/td][td]Jarvis-Patrick聚类[/td][td]1. Breadth First Search广度优先遍历; 2. Depth First Search深度优先遍历;[/td][/tr][tr][td]Cluster[/td][td]33[/td][td]Agglomerative NESting[/td][td]AGNES 层次聚类[/td][/tr][tr][td]Cluster[/td][td]34[/td][td]Gaussian Mixture Model(GMM) (EC)[/td][td]混合高斯模型聚类[/td][/tr][tr][td]Cluster[/td][td]35[/td][td]Spectral Clustering[/td][td]谱聚类LE+KMeans[/td][/tr][tr][td]Cluster[/td][td]36[/td][td]Self Organizing Maps(SOM) [/td][td]自组织映射神经网络,一种基于神经网络的聚类算法[/td][/tr][tr][td]Cluster[/td][td]37[/td][td]LVQ Cluster[/td][td]学习向量量化监督聚类[/td][/tr][tr][td]DR[/td][td]38[/td][td]Principal Component Analysis(PCA)[/td][td]主成分分析 1. SVD;2. NIPALS非线性迭代偏最小二乘算法Nonlinear iterative partial least squares algorithm;[/td][/tr][tr][td]DR[/td][td]39[/td][td]Kernel PCA [/td][td]核主成分分析[/td][/tr][tr][td]DR[/td][td]40[/td][td]Feature Embedding[/td][td]特征嵌入pN[/td][/tr][tr][td]DR[/td][td]41[/td][td]Independent Component Analysis(ICA) [/td][td]独立分量分析[/td][/tr][tr][td]DR[/td][td]42[/td][td]Nonnegative Matrix Factorization(NMF) 非负矩阵分解[/td][td]1.Gradient Descent梯度下降; 2.ANLS,非负交替最小二乘法Alternating least square method; 3.NeNMF: An Optimal Gradient Method for Nonnegative Matrix Factorization; 4.CNMF; 5.Multiplicative Update;[/td][/tr][tr][td]DR[/td][td]43[/td][td]Factor Analysis[/td][td]因子分析[/td][/tr][tr][td]DR[/td][td]44[/td][td]Multidimensional Scaling(MDS) [/td][td]多维尺度分析[/td][/tr][tr][td]DR[/td][td]45[/td][td]Isometrix Mapping(Isomap)[/td][td]等度量映射/等距特征映射 Shortest Path Algorithm最短路径[/td][/tr][tr][td]DR[/td][td]46[/td][td]Locally Linear Embedding(LLE) [/td][td]局部线性嵌入[/td][/tr][tr][td]DR[/td][td]47[/td][td]Locality Preserving Projection(LPP) [/td][td]局部保留投影法[/td][/tr][tr][td]DR[/td][td]48[/td][td]Laplacian Eigenmap(LE) [/td][td]拉普拉斯特征映射,相似性:1.KNN;2.Gaussian;3.LocalScaling;4.KNNGaussian;5.KNNLocalScalling[/td][/tr][tr][td]DR[/td][td]49[/td][td]SVD [/td][td]特征值分解[/td][/tr][tr][td]MCA[/td][td]50[/td][td]Multivariate Curve Resolution-Alternating Least Squares(MCR-ALS) [/td][td]多元曲线分辨-交替最小二乘法(NNLS)[/td][/tr][tr][td]MCA[/td][td]51[/td][td]Generalized Rank Annihilation Method(GRAM) [/td][td]广义秩消因子法[/td][/tr][tr][td]MCA[/td][td]52[/td][td]Direct Trilinear Decomposition(DTLD) [/td][td]直接三线性分解[/td][/tr][tr][td]MCA[/td][td]53[/td][td]CANDECOMP/PARAFAC [/td][td]典范/平行因子分析[/td][/tr][tr][td]MCA[/td][td]54[/td][td]Alternating Trilinear Decomposition(ATLD) [/td][td]交替三线性分解[/td][/tr][tr][td]MCA[/td][td]55[/td][td]SWATLD [/td][td]自加权交替三线性分解[/td][/tr][tr][td]MCA[/td][td]56[/td][td]APTLD [/td][td]交替惩罚三线性分解[/td][/tr][tr][td]MCA[/td][td]57[/td][td]Window Factor Analysis(WFA) [/td][td]窗口因子分解[/td][/tr][tr][td]MCA[/td][td]58[/td][td]Heuristic Evolving Latent Projection(HELP) [/td][td]启发渐进式特征投影[/td][/tr][tr][td]OPT[/td][td]59[/td][td]Genetic Algorithm(GA)[/td][td]遗传算法[/td][/tr][tr][td]OPT[/td][td]60[/td][td]Particle Swarm Optimization(PSO)[/td][td]粒子群优化算法[/td][/tr][tr][td]OPT[/td][td]61[/td][td]Differential Evolution Algorithm(DEA)[/td][td]差分进化算法[/td][/tr][tr][td]OPT[/td][td]62[/td][td]Ant Colony Optimization(ACO) [/td][td]蚁群算法[/td][/tr][tr][td]OPT[/td][td]63[/td][td]Immune Algorithm(IA)[/td][td]免疫算法[/td][/tr][tr][td]OPT[/td][td]64[/td][td]Simulate Anneal(SA) [/td][td]模拟退火算法[/td][/tr][tr][td]OPT[/td][td]65[/td][td]Tabu Search or Taboo Search(TS) [/td][td]禁忌搜索算法[/td][/tr][tr][td]Others[/td][td]66[/td][td]Kalman[/td][td]卡尔曼滤波,Mixture,估计-修正-估计-修正[/td][/tr][tr][td]Others[/td][td]67[/td][td]Curve Fitting 曲线拟合[/td][td]1.Mixture Gaussian混合高斯;2.Polynomial多项式[/td][/tr][tr][td]Others[/td][td]68[/td][td]EA-Max/Min [/td][td]智能优化算法-最值问题[/td][/tr][tr][td]Others[/td][td]69[/td][td]EA-TSP [/td][td]智能优化算法-旅行商问题[/td][/tr][tr][td]Others[/td][td]70[/td][td]EA-Knapsack [/td][td]智能优化算法-背包问题[/td][/tr][tr][td]Others[/td][td]71[/td][td]Robust Principal Component Analysis(RPCA) [/td][td]稳健主成分分析[/td][/tr][tr][td]Base[/td][td]72[/td][td]Statics[/td][td]统计量[/td][/tr][tr][td]Base[/td][td]73[/td][td]Baseline Correction[/td][td]基线矫正(背景扣除) 1.ArPLS; 2.AirPLS;[/td][/tr][tr][td]Base[/td][td]74[/td][td]Distance and Similarity 距离与相似性[/td][td]1. Cosine余弦距离; 2. Minkowski 闵可夫斯基距离 Lp; 3. Euclidean欧氏距离L2; 4. Manhattan曼哈顿距离L1; 5. Chebyshev切比雪夫距离L; 6. Mahalanobis马氏距离; 7. Jaccard Coefficient杰卡德系数/Tanimoto; 8. Soergel塞格尔; 9. Bray Curtis/Czekanowski/Srenson Coefficient; 10. Hamming汉明距离; 11. Correlation 皮尔逊相关系数; 12. SNN相似度(Shared Nearest Neighbour); 13. Levenshtein 距离; 14. Damerau Levenshtein距离;[/td][/tr][tr][td]Base[/td][td]75[/td][td]Smooth 平滑[/td][td]Moving Average,Median,Parzen,Exponential, Guassian,SavitzkyGolay,FFT,Wavelet[/td][/tr][tr][td]Base[/td][td]76[/td][td]Peak [/td][td]峰值[/td][/tr][tr][td]Base[/td][td]77[/td][td]Normalize 归一化/标准化[/td][td]1. Mean;2.Area;3.UnitVector 4. Max;5. Range;6. Peak;7. MaxMin;8.ZSocre;[/td][/tr][tr][td]Base[/td][td]78[/td][td]Histogram 直方图[/td][td]非参数估计[/td][/tr][tr][td]Base[/td][td]79[/td][td]FFT/iFFT[/td][td]快速傅里叶变换[/td][/tr][tr][td]Base[/td][td]80[/td][td]Wavelet 小波变换[/td][td]1.DWT; 2.CWT; 3.iDWT;[/td][/tr][tr][td]Base[/td][td]81[/td][td]Compress(Wavelet) 压缩[/td][/tr][tr][td]Base[/td][td]82[/td][td]Decompose(Wavelet) 分解[/td][td]1.WithSampling:standard wavelet with sampling, 2.WithoutSampling:Low part is separated as even and odd two parts in this algorithm,[/td][/tr][tr][td]Base[/td][td]83[/td][td]Expectation Maximization(EM) [/td][td]最大期望算法[/td][/tr][tr][td]Base[/td][td]84[/td][td]Convolution/Deconvolution[/td][td]卷积/去卷积[/td][/tr][tr][td]Base[/td][td]85[/td][td]AutoCorrelation/CrossCorrelation[/td][td]自相关/胡相关[/td][/tr][tr][td]Base[/td][td]86[/td][td]MSC[/td][td]多元散射校正[/td][/tr][tr][td]Base[/td][td]87[/td][td]Outlier [/td][td]离群值检测[/td][/tr][tr][td]Base[/td][td]88[/td][td]Feature Selection[/td][td]特征选择[/td][/tr][tr][td]CS[/td][td]89[/td][td]Orthogonal Matching Pursuit(OMP)[/td][td]正交匹配追踪[/td][/tr][tr][td]CS[/td][td]90[/td][td]Compressive sampling MP(CoSaMP)[/td][td]压缩采样匹配追踪[/td][/tr][tr][td]CS[/td][td]91[/td][td]Stagewise Matching Pursuit(StOMP)[/td][td]分段匹配追踪[/td][/tr][tr][td]CS[/td][td]92[/td][td]Weak Matching Pursuit(WMP)[/td][td]弱匹配追踪[/td][/tr][tr][td]CS[/td][td]93[/td][td]Subspace Pursuit(SP)[/td][td]子空间追踪[/td][/tr][tr][td]CS[/td][td]94[/td][td]Iterative Hard Threshold(IHT)[/td][td]迭代硬阈值算法[/td][/tr][tr][td]CS[/td][td]95[/td][td]Linearized Bregman[/td][td]线性Bregman[/td][/tr][tr][td]Ensemble[/td][td]96[/td][td]Random Forest[/td][td]随机森林[/td][/tr][tr][td]Ensemble[/td][td]97[/td][td]Boosting[/td][/tr][tr][td]Ensemble[/td][td]98[/td][td]Bagging[/td][/tr][tr][td]BIO[/td][td]99[/td][td]Sequence Alignment[/td][td]基因序列比对 GlobalNeedlemanWunsch LocalSmithWaterman[/td][/tr][tr][td]RC[/td][td]100[/td][td]NNT_MLP[/td][td]反馈神经网络(BP,LM,CG)[/td][/tr][tr][td]Regression[/td][td]101[/td][td]NNT_RBF[/td][td]KMeans-LS 径向基网络Radial Basis Networks[/td][/tr][tr][td]Classification[/td][td]102[/td][td]NNT_Hamming[/td][td]Compete NN, input 0/1[/td][/tr][tr][td]Classification[/td][td]103[/td][td]NNT_LVQ[/td][td]Compete NN, cluster/classification, 学习向量量化Learning Vector Quantization[/td][/tr][tr][td]Cluster[/td][td]104[/td][td]NNT_Kohonen[/td][td]Compete NN, SOM, cluster[/td][/tr][tr][td]107[/td][td]NNT_CNN[/td][td]卷积网络[/td][/tr][/table]
本文以环境监测中的有机物生物氧化降解反应的速率方程表达式的计算为例,介绍了Excel中线性回归计算法的应用,结果表明:用Excel计算,效率高、精度高。关键词:Excel;线性回归;环境监测;应用[img]http://bbs.instrument.com.cn/images/affix.gif[/img][url=http://bbs.instrument.com.cn/download.asp?ID=198659]Excel中线性回归计算法在环境监测中的应用.rar[/url]
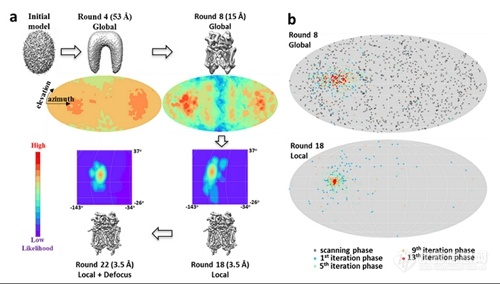
蛋白质是生命体的最主要组成元素,作为一种生物大分子机器,蛋白质功能的实现高度依赖于其复杂的三维原子结构。了解蛋白质的结构及其与功能的关系对探索生命的基本原理,理解疾病的分子机制以及药物的研发具有重要的意义。[align=center][img=,500,284]https://ng1.17img.cn/bbsfiles/images/2018/12/201812131109255316_9391_3224499_3.jpg!w500x284.jpg[/img][/align][align=center]基于粒子滤波的三维重构算法示意图。[/align]冷冻电子显微镜,简称冷冻电镜,使用电子束作为光源,是一种能在原子分辨率水平上观察并测定蛋白质分子结构的有力工具。伴随着最近几年的技术突破,冷冻电镜三维重构技术成为测定蛋白质及其复合物结构的关键技术。冷冻电镜三维重构的基本方法是,首先利用冷冻电镜对冷冻于液氮温度的生物大分子颗粒进行成像,以获得数万到数百万张生物大分子照片,然后通过一定的算法来整合这些图像,计算出生物大分子的三维结构。这其中三维重构算法是核心内容,用于测定出每一张照片的诸多参数,例如空间取向,然后才能将二维的照片整合重构出三维的结构。因为照片的数量巨大,且图像信号极其微弱,如何精确计算测定每张照片的参数,以达到超过0.4甚至0.2纳米的分辨率,一直以来都是冷冻电镜技术研究的重点和难点。来自清华大学生命科学学院的研究人员发表了题为“A particle-filter framework for robust cryoEM 3D reconstruction”的文章,介绍了一种基于粒子滤波的鲁棒的冷冻电镜三维重构算法框架,这种方法通过将电子工程应用中的粒子滤波算法引入到冷冻电镜三维重构中,大幅提高了对系统参数的搜索能力和对系统误差的容忍度;通过进一步融合高性能计算的方法,最终实现了对生物大分子结构高效高精度的三维重构。这一发现公布在11月30日的Nature Methods杂志上,由清华大学生命科学学院李雪明研究组,电子工程系沈渊研究组和计算机系杨广文研究组合作完成。第一作者为胡名旭,余洪坤和顾凯。同期他们开发的THUNDER冷冻电镜三维重构软件系统集成了这些新算法和新特性,为未来冷冻电镜海量图像数据的实时分析,以及大规模的自动化应用提供了一个可靠的算法和软件基础;同时,也为解析接近原子分辨率的生物结构提供了一套鲁棒、快速的解决方案,显著降低了对用户经验的要求,益于冷冻电镜技术的广泛普及,助力在原子尺度上对生命活动进行观察。为了获得一个更有效的算法和计算系统以满足未来高分辨率和大规模应用的需求,李雪明研究组联合电子系沈渊和计算机系杨广文研究组,利用清华大学生物学科和信息学科交叉的优势,将电子工程领域的粒子滤波算法引入到冷冻电镜的图像重构参数搜索中去,发展出一套比现有算法更完善、更有效的贝叶斯统计推断算法。这套新算法对高维参数的搜索具有更好的鲁棒性,可以自适应地进行参数的自动调整,以及通过引入一套新的权重机制大幅提高了对系统误差的容忍度。这些优势的整合,使整个系统具有很好的鲁棒性,更适用于未来自动化的运行工作模式。同时,在算法的实现过程中,深度融合了大规模并行计算的思路和方法,从而使整个系统具有极高的运算效率,和近乎理想的并行计算性能。未来该系统将能够高效运行于小到一个工作站,大到“太湖之光”这样的超大规模计算系统,适应生命科学研究和药物设计的大量结构测定需求。这项工作是三个不同学科研究组交叉研究的阶段性成果,团队正在利用新型的统计推断和机器学习算法将这一工作扩展到对细胞或者细胞器结构的原子分辨率三维重构上去。未来的冷冻电镜技术将使人们不必再借助于复杂的生物化学手段来提取蛋白质,而是利用冷冻电镜直接在细胞中对包括蛋白质在内的生物大分子的原子结构和动态变化进行观察和分析,探索生命活动的本质原理,设计能够治愈疾病的药物,造福人类健康。
新华社华盛顿5月9日电(记者林小春)美国研究人员9日在学术期刊《科学》上报告说,他们开发出一种新计算方法,可以更快地发现抵御艾滋病病毒的强力抗体,这一成果有望加快艾滋病疫苗研发。 开发艾滋病疫苗是全球面临的重要任务和挑战。尽管艾滋病病毒已发现30多年,但由于其多变和多样性,迄今还没有一种针对该病的疫苗能离开实验室并大量应用。不过近年来,科研人员在艾滋病病毒“中和抗体”研究方面已取得重要进展。 “中和抗体”是免疫细胞分泌的一类蛋白,能在某些病毒侵入细胞之前与该病毒结合,阻止其黏附、感染细胞,相当于把病毒“中和”掉。 美国国家卫生研究院疫苗研究中心的科研人员,将已知“中和抗体”的相关数据与生物信息学分析结合起来,开发出一种相对简单快速的计算方法,能通过分析血样对毒株的反应,准确判断某人的血液中有哪几类抗体能够抵御艾滋病病毒。 这份报告的共同第一作者周同庆对新华社记者说,长期以来人们一直在研究那些具有强力中和活性的艾滋病病毒感染者的血液,因为了解这些人如何产生攻击艾滋病病毒的强力“中和抗体”,可为设计疫苗提供线索。但血液中有多种抗体,常规分析方法不易确定哪种抗体能更有效地抵御艾滋病病毒,即便能确定相关抗体的中和原理,一般也需要多年艰苦研究,同时涉及复杂技术且需要大量血样。 周同庆及其同事开发出的新算法,则依据已知的艾滋病病毒抗体的中和反应数据,组建数据库,通过比对血样成分对抗艾滋病病毒时留下的“中和指纹”与数据库中的相关抗体数据,可快速准确地确定血中“有用”抗体的类型和比例。对一些艾滋病病毒感染者的血样测试表明,该算法准确有效。 周同庆说,这一方法在未来艾滋病疫苗研发过程中,可用来快速评估接种人群的免疫反应,有重要应用前景。此外,他们还着手将这一技术扩展应用到丙型肝炎、流感等其他传染病疫苗研究中。 《科学》期刊配发的一篇评论文章指出,疫苗开发正从基于病毒灭活的经验科学,向基于核酸和蛋白质等相关研究的理性设计过程转型,包括新算法在内的一些艾滋病研究新进展表明,“对于新艾滋病疫苗的设计和测试前景,我们应该持乐观态度”。
欧姆表是多用表的一个单元,用来测量电阻的阻值。欧姆表的原理是高中物理重要内容。1.原理将电池组、电流表和变阻器相串联构成欧姆表的内电路。1)测量态给欧姆表的两表笔之间接上待测电阻,则电池组、电流表和变阻器及待测电阻构成闭合电路,电路中的电流随被测电阻的变化而变化,将电表的电流刻度值改为对应的外电阻刻度值,即可从欧姆表上直接读得待测电阻阻值。Rx=εI-(r+Rg+R)实例 将满偏电流为IG=100μA、内阻为Rg=100(Ω)的灵敏电流表跟电动势为ε=1.5V内阻为r=0.1(Ω)的电池组和总电阻为R=I8KΩ的变阻器相串联并将变阻器调至R=14.9(KΩ),即组装成一欧姆表。各电流值对应的待测电阻值由上式计算如表:在表盘上各电流刻度处标示出相应的待测电阻值,即可直接读出待测电阻值。2)调零态①机械调零 当两表笔分开时,即待测电阻为无穷大时,由欧姆定律知此时电流强度为零。即当两表笔分开时,万用表电表指针指示的状态应为零电流和无穷大欧姆。但是由于各种原因,当两表笔分开时电表的指针有时并没有指在零电流刻度上,这就需要进行机械调零。用螺旋刀转动机械调零螺丝带动指针转动,使指针指无穷大欧姆刻度处。②欧姆调零当两表笔短接时,由欧姆定律知,可以通过调节滑动变阻器使电流表满偏,即令指针指电流表的满偏电流刻度处,示波器亦即零欧姆刻度处。即当两表笔短接时, 电表指针指示的状态应为满偏电流和零欧姆阻值。否则,调节变阻器使电流表指针指满偏电流刻度处,亦即零欧姆刻度处,即完成欧姆调零。2.内阻1)设计值将欧姆表的两表笔短接,即欧姆表处于调零态,由欧姆定律得:欧姆表的内阻等于欧姆表中的电源的电动势与欧姆表中的电流表的满偏电流之比RΩ=ε/IG.所以用来组装欧姆表的灵敏电流表和电池选定后,组装成的欧姆表的内阻也就确定了。2)实际值欧姆表的实际内阻由电源的内阻、电流表的内阻和调零变阻器的电阻串联构成,其总阻值应等于设计值。RΩ=r+RG+R.我们应合理选择滑动变阻器的总阻值,以满足欧姆表内阻设计值的要求。3)刻度值当被测电阻的阻值恰等于欧姆表的内阻RΩ时,整个测量电路的总电阻等于欧姆表的内阻的二倍则测量电流为电流表满偏电流的一半,即指针指在刻度板的中值R?渍上。即欧姆表的中值刻度指示出欧姆表的内阻值R?渍=RΩ。3.误差1)电源误差欧姆表长期使用后,电池的电动势减小、内阻增大,进行欧姆调零时虽然做到了电流表满偏,但这种变化使读得的电阻值大于被测电阻真实值。欧姆表的内阻的设计标准值由新电池的电动势和电流表的满偏电流决定:RΩ=ε/IG;电阻刻度与电流的对应关系由新电池电动势和欧姆表内阻的标准值确定:RX*=ε/I-RΩ;装有旧电池时进行欧姆调零后欧姆表实际内阻值小于标准内阻值:RΩ*=ε`/IG;旧电池时电源电动势和万用表欧姆表内阻及被测电阻实际值决定表中测量电流I=ε`/( RΩ+ RX),以上四式联立解得RX=εε'RX可见,随着电源电动势逐渐减小,电阻的测量值成反比的逐渐增大。实例 一欧姆表的电池的电动势为1.5v,经长期使用后,电动势降为1.2v,用它测量一电阻,测量值为500Ω,求该电阻的实际值为多少?解: Rx=(ε`/ε) RX*=1.2÷1.5×500=400Ω2)读数误差由于人的观察能力有限,读数时总存在着几何误差。设指针实际位置处的电流刻度为I, 对应欧姆刻度为RΩ,观察到的指针位置处的电流刻度为I`,对应欧姆刻度为RΩ`.则由RX=εI-RΩ和R'X=εI'-RΩ得ΔRx=εI-εI'=-I-I'I·I'-ε=εI2·ΔI即δ=ΔRxRx=εI2·ΔIεI-εIG=IGI(IG-I)·ΔI即δ=Θθ(Θ-θ)Δθ可知分母两因子之和为一定数,即最大偏转角度,从而分母两因子相等时其积最大读数误差最小。即当θ=Θ2时δ=δmin=4·ΔθΘ从而在刻度弧线的几何中点,几何视差引起的欧姆误差最小。应选取恰当的档位,令表针指示值尽量接近面板中值,使读数误差最小。
2017年4月24就已经发布了HJ212-2017,但是其中关于算法部分:1.废水污染物算法有两种,但是未明确讲对应算法的使用条件2.废气有HJ75-2017标准还能基本做参考,但是废水没有类似的标准,这样的情况下,各个地市环保局也不知道该如何执行,只是按照212的要求,各产品厂家更不知道该怎么做。 回复:经研究,现答复如下: 一、关于废水中COD、氨氮等污染物浓度均值的计算方法。《污染物在线自动监控(监测)系统数据传输标准》(HJ212-2017)中附录D(资料性附录)规定了2种水污染物浓度计算公式,分别为加权平均算法与算术平均算法。具体算法请依据《水污染源在线监测系统(CODCr、NH3-N 等)数据有效性判别技术规范》(HJ 356-2019)中“在同时监测污水排放流量的情况下,COD、氨氮等污染物因子有效日均值是以流量为权的某个污染物的有效监测数据的加权平均值;在未监测污水排放流量的情况下,有效日均值是某个污染物的有效监测数据的算术平均值”相关内容要求。 二、关于废水污染物中pH算法。pH不参与平均值计算,只参与最大值、最小值计算。 三、关于数据处理。按照《水污染源在线监测系统(CODCr、NH3-N 等)数据有效性判别技术规范》(HJ 356-2019)中相关要求:(1)当流量为零时,所得的监测值为无效数据,应予以剔除;(2)监测值为负值无任何物理意义,可视为无效数据,予以剔除;(3)在自动监测仪校零、校标和质控样试验期间的数据作无效数据处理,不参加统计,但对该时段数据作标记,作为监测仪器检查和校准的依据予以保留。 四、关于水污染物数据标记。按照《污染物在线自动监控(监测)系统数据传输标准》(HJ212-2017)中6.6.4数据标记中表8内容执行;在进行数据计算时(日数据、小时数据等)除数据标记为正常的数据(数据标记为N)外均认为无效(异常)数据,不参与有效数据的计算。小时数据标记可按照优先级顺序从高到低为F、D、M、C、T、S、B。日数据计算中有效数据不足75%时,日数据标记按照小时数据中无效(异常)数据标记中占比最大标记,无效标记遇到相同占比时可按照优先级从高到底为:D、M、C、T、S、B。
来信: [font=&][size=16px][color=#4c4c4c] 2017年4月24就已经发布了HJ212-2017,但是其中关于算法部分: 1.废水污染物算法有两种,但是未明确讲 对应算法的使用条件 2.废气有HJ75-2017标准还能基本做参考,但是废水没有类似的标准,这样的情况下,各个地市环保局也不知道该如何执行,只是按照212的要求,各产品厂家更不知道该怎么做。[/color][/size][/font] 回复: 经研究,现答复如下: 一、关于废水中COD、氨氮等污染物浓度均值的计算方法。《污染物在线自动监控(监测)系统数据传输标准》(HJ 212-2017)中附录D(资料性附录)规定了2种水污染物浓度计算公式,分别为加权平均算法与算术平均算法。具体算法请依据《水污染源在线监测系统数据有效性判别技术规范》(HJ/T 356-2007)6.9中“在同时监测污水排放流量的情况下,COD、氨氮等污染物因子有效日均值是以流量为权的某个污染物的有效监测数据的加权平均值;在未监测污水排放流量的情况下,有效日均值是某个污染物的有效监测数据的算术平均值”相关内容要求。 二、关于废水污染物中pH算法。pH不参与平均值计算,只参与最大值、最小值计算。 三、关于数据处理。按照《水污染源在线监测系统数据有效性判别技术规范》(HJ/T 356-2007)中相关要求:(1)当流量为零时,所得的监测值为无效数据,应予以剔除;(2)监测值为负值无任何物理意义,可视为无效数据,予以剔除;(3)在自动监测仪校零、校标和质控样试验期间的数据作无效数据处理,不参加统计,但对该时段数据作标记,作为监测仪器检查和校准的依据予以保留。 四、关于水污染物数据标记。按照《污染物在线自动监控(监测)系统数据传输标准》(HJ 212-2017)中6.6.4数据标记中表8内容执行;在进行数据计算时(日数据、小时数据等)除数据标记为正常的数据(数据标记为N)外均认为无效(异常)数据,不参与有效数据的计算。小时数据标记可按照优先级顺序从高到低为F、D、M、C、T、S、B。日数据计算中有效数据不足75%时,日数据标记按照小时数据中无效(异常)数据标记中占比最大标记,无效标记遇到相同占比时可按照优先级从高到底为:D、M、C、T、S、B。 五、《水污染源在线监测系统数据有效性判别技术规范》(HJ/T 356-2007)以及涉及水污染源在线监测系统共4个技术规范正在修订中,待修订工作完成后,请以新修订规范中规定为准。
急需检测限的算法,多谢了!
求助,普析uvwin5.0软件中,软件自带的光谱数据平滑处理使用的哪种平滑算法,原理是怎么样的呢?
[b]职位名称:[/b]信号算法工程师[b]职位描述/要求:[/b]岗位职责:- 谱图预处理:通过滤波、提取、压缩、变换等数字信号处理方法和算法对谱图数据进行预处理。- 谱图特征识别:通过时域分析、频域分析、统计分析等方法发现数据特征,并且编写代码实现特征提取。- 根据需求开发新算法。任职要求:- 有扎实的数学基础,有数字信号处理理论基础和实践经验;- 熟练使用仿真工具和软件,精通一门编程语言;- 具备阅读科技论文的能力和代码转化能力; - 有智能仪器仪表、嵌入式系统、图像处理、模式识别等算法经验者优先。[b]公司介绍:[/b] 深圳至秦仪器有限公司(www.chinst.com.cn)成立于2018年10月,是一家拥有自主品牌、以便携质谱仪为核心、集产研销一体的国家高新技术企业,致力于为客户提供分析测试全方位的解决方案,我们持续帮助食品安全、医疗健康、教育科研、公共安全、环境检测、海洋能源等领域用户获得合适的检测仪器。主要产品包括:食品快检便携式质谱系统平台、基于质谱的大气挥发性有机物在线监测与溯源系统、海洋环境监测质谱...[url=https://www.instrument.com.cn/job/user/job/position/75620]查看全部[/url]
伊尔姆真空泵内部电气原理图
[size=16px][color=#ff0000][b][url=https://www.instrument.com.cn/job/position-80087.html]立即投递该职位[/url][/b][/color][/size][b]职位名称:[/b]图像算法工程师[b]职位描述/要求:[/b]岗位职责:1.开发、优化和探索用于显微图像处理的计算机视觉算法2.与硬件工程师一起设计和优化显微成像产品岗位要求:1、计算机、数学或人工智能等相关专业,本科及以上学历,硕士优先;2、三年以上机器学习算法和图象识别算法从业经验;3、熟悉图像处理算法原理,有较强的数学功底和逻辑思维;4、掌握至少一种图像处理算法库,如Opencv、Halcon;5、掌握至少一种编程语言,如C++/C#/python;6、具备良好的英语阅读能力,能够直接阅读英文文献;7、具有较强的合作精神、责任心、敬业精神、有良好的团队合作意识。[b]公司介绍:[/b] 倍辉科技有限公司是国内创新科技的引领代理商,位于北京朝来高科技产业园。我们致力于将先进的产品及技术更好的服务于中国快速发展的生命科学及药物研究领域,涵盖活体动物成像,基因表达研究,非标记细胞成像研究,蛋白功能研究,转基因领域及纳米技术。我们在上海,武汉,青岛,广州等十四个城市建有办事处及联络机构,已经建立起比较完善的销售网络和服务体系。我们已经和近二十家国际一流的厂家进行合作,本着严谨科学的态...[url=https://www.instrument.com.cn/job/position-80087.html]查看全部[/url][align=center][img=,178,176]https://ng1.17img.cn/bbsfiles/images/2021/08/202108160948175602_3528_5026484_3.png!w178x176.jpg[/img][/align][align=center]扫描二维码,关注[b][color=#ff0000]“仪职派”[/color][/b]公众号[/align][align=center][b]即可获取高薪职位[/b][/align]
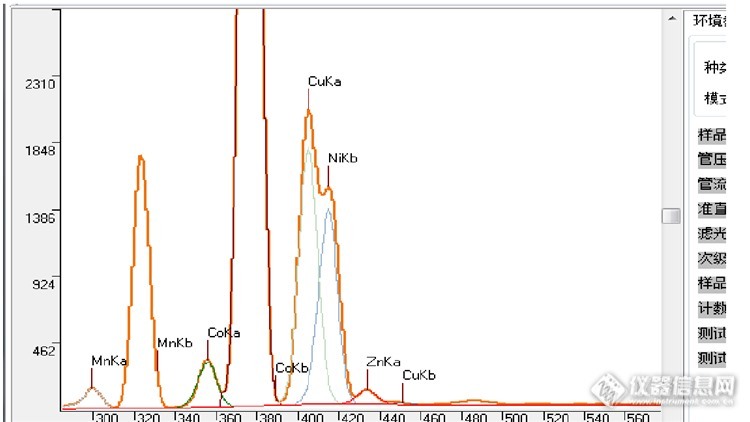
元素的峰重叠在光谱分析中对定量结果影响很大,需要进行分离。重叠峰分离的方法有很多,比如:傅立叶变换、偏最小二乘法等。这里介绍一种卡尔曼滤波算法。卡尔曼滤波器是一个“optimal recursive data processing algorithm(最优化自回归数据处理算法)”。对于解决很大部分的问题,他是最优,效率最高甚至是最有用的。他的广泛应用包括机器人导航,控制,传感器数据融合甚至在军事方面的雷达系统以及导弹追踪等等。近年来更被应用于计算机图像处理,例如头脸识别,图像分割,图像边缘检测等等。具体的算法,因为极其复杂,所以不在这里罗列,感兴趣的可以去搜索相关资料。这里演示一下在用能散XRF测镍铜合金中的一个案例:http://ng1.17img.cn/bbsfiles/images/2017/03/201703051157_01_1780790_3.png图中镍的Kb峰、铜的Ka峰和锌的Ka峰、铜的Kb峰存在重叠。谱峰分离效果如图。通过众多的样品测试分析,卡尔曼滤波算法对于重叠程度低于90%的,分离效果相当好,对于重叠程度大于90%而小于95%的有一定误差,而超过95%的基本就无能为力只能回归到分支比扣除法。
鸡兔同笼新算法:已知共有鸡和兔15只,共有40只脚,问鸡和兔各有几只。算法:假设鸡和兔训练有素,吹一声哨,它们抬起一只脚,(40-15=25) 。再吹一声哨,它们又抬起一只脚,(25-15=10) ,这时鸡都一屁股坐地上了,兔子还两只脚立着。所以,兔子有10/2=5只,鸡有15-5=10只。 -----------------------------------人才!!!

云唐ATP荧光检测仪工作原理:该设备为全新升级产品,大屏幕触摸显示屏,代替传统按键。操作采用生物化学反应方法检测ATP含量,ATP荧光检测仪基于萤火虫发光原理,利用“荧光素酶—荧光素体系”快速检测三磷酸腺苷(ATP)。ATP拭子含有可以裂解细胞膜的试剂,能将细胞内ATP释放出来,与试剂中含有的特异性酶发生反应,产生光,再用荧光照度计检测发光值,微生物的数量与发光值成正比,由于所有生物活细胞中含有恒量的ATP,所以ATP含量可以清晰地表明样品中微生物与其他生物残余的多少,用于判断卫生状况。[img=,690,690]https://ng1.17img.cn/bbsfiles/images/2023/09/202309041718145953_7240_5604214_3.jpg!w690x690.jpg[/img]
差热分析仪的工作原理是将待测试样和参比物(热惰性物质)置于同一条件的炉体中,按给定程序等速升温或降温,当加热试样在不同温度下产生物理、化学性质的变化(如相变,结晶构造转变,结晶作用,沸腾,升华,气化,熔融,脱水,分解,氧化,还原……及其他反应)时,伴随吸热或放热,试样自身的温度低于或高于参比物质的温度,即两者之间产生温差。温差的大小(反应前和反应后二者的温差为零)和极性由热电偶检测,并转换为电能,经放大器放大输入记录仪,记录下的曲线即为差热曲线。差热分析仪是研究细小的粘土矿物和含水矿物的必不可少的工具。差热分析仪的特点:1、热流式DSC数据采集方式,绘制出能量与温度的曲线。2、用户可以自行利用标准样品对温度、能量、热重准确性进行校正。3、气氛控制系统采用质量流量控制器,三路稳压、稳流气体可以在实验过程中自动切换,精度高、重复性好、响应速度快(可以定制耐各种腐蚀性气体的气氛控制系统)。4、从微量样品到大剂量样品均可满足(更换支撑杆,最大样品可达5g)。可满足各种样品在不同条件下的测试要求。5、全部测量过程自动完成,自动绘图,丰富的软件功能可完成DTA、 TG、 DTG 、DTTG 常规数据处理;特殊数据处理(DTA峰面积、热焓计算、动力学参数计算、数据比较、多种算法计算活化能、玻璃化温度、比较法测量比热等)。6、差热分析仪的系统采集试样过程中,可任意时刻截图,根据输出信号大小自动变换量程。7、大屏幕液晶显示,实时显示仪器的状态和数据,两套测温电偶,一套电偶实时显示炉温(无论加热炉工作与否)另一套电偶显示工作时样品温度。8、用户给出计算的公式或计算方法,我厂能及时提供相应的软件研制产品。9、自主研发的恒温控制器;恒温气相色谱、质谱连接头;恒温带;可充分保证焦油及各种反应气体的二次检测。
[font=宋体][font=宋体]相较于传统的一元或是多元线性回归模型,机器学习算法具有更强的非线性映射能力,传统的机器学习算法有[/font][font=Times New Roman]BP[/font][font=宋体]神经网络、极限学习机、支持向量机、决策树和随机森林等。[/font][/font]







 我要推广仪器
我要推广仪器
 下载APP
下载APP