[img]http://www.instrument.com.cn/bbs/images/affix.gif[/img][url=http://www.instrument.com.cn/bbs/download.asp?ID=41259]1HNMR图谱中活泼氢的识别方法[/url]
请问这一项改如何操作?4.3条款里的实验室应提供对已被替代但仍然有效版本标准识别方法。谢谢!!!
[img]http://www.instrument.com.cn/bbs/images/affix.gif[/img][url=http://www.instrument.com.cn/bbs/download.asp?ID=34047]NMR指纹图谱与模式识别方法在食物分析中的应用.pdf[/url]
1HNMR图谱中活泼氢的识别方法摘自:汪茂田等《天然有机化合物提取分离与结构鉴定》化学工业出版社,2004在1HNMR图谱中活泼氢信号变化多端,有的峰尖锐,有的峰较宽,有的峰积分面积明显较小,有的峰和其它质子信号重叠,有的峰几乎与图谱基线一致等。产生上述现象的原因一般分两类情况,也可以分为内因和外因。内因是指分子结构引起的,如羧基的活泼氢、螯合的羟基、烯醇羟基、酰胺的活泼氢和一些交换速度比较慢的活泼氢一般表现为宽单峰(br.s),交换速度快的活泼氢表现为比较锐的单峰,羟基质子和同碳氢发生偶合时则表现为三重峰(t)或二重峰(d)。外因 原则上是与样品浓度、温度、溶剂、样品中的水分等因素有关。但研究者关心的问题是如何如何识别活泼氢信号。下面介绍几种识别活泼氢信号的方法。(1)重水交换是最经典和常用的识别活泼氢的方法, 但也有不方便和不足之处。一是重水交换必需重新测定一次图谱,二是较大的水峰会干扰δ4.7ppm左右的样品信号。如果样品同时还要测定H-HCOSY和H-CCOSY谱的话,可用这些图谱来识别活泼氢,必要时再做重水交换实验,当然重水交换的优点是隐藏在其它信号中的活泼氢信号可以被消除。绝大多数情况下,重水交换的速度是很快的,有一些化合物,如酰胺的活泼氢交换速度较慢,加入重水后要放置一段时间或稍微加热后测定。(2)由H-CCOSY谱鉴别活泼氢信号因为活泼氢不和碳直接相连,故和碳没有相关峰的质子信号应是活泼氢的峰。所以当一个化合物同时有1HNMR和H-CCOSY 谱的话,就不必刻意由1HNMR谱识别活泼氢信号,两种谱结合起来问题就容易的多了。例如头孢噻呋的HMQC谱(图9-2)中的δ9.54(1H,d)信号没有和碳的相关峰,它是酰胺的活泼氢信号,δ7.16(2H,s)是NH2的信号,和碳没有相关峰。当活泼氢不和同碳质子发生偶合时,活泼氢在H-HCOSY谱中没有相关峰。当然要注意孤立质子的共振信号以及由于双面夹角接近或等于90°时的特定质子的信号 (单峰或宽单峰),但这些质子在H-CCOSY谱中有相关峰。在活泼氢与同碳质子发生偶合的情况下,缺乏经验的研究者可能不易从1HNMR和H-HCOSY图谱上看出来,这时可借助H-CCOSY谱来识别。由HMBC谱也可以获得活泼氢连接位置的信息,当采用氢键溶剂如氘代二甲基亚砜或氘代吡啶测定NMR图谱时(要尽可能干燥),活泼氢由于能和溶剂形成氢键,使其不易发生交换而比较“固定”,在HMBC中可以检测出这些活泼氢与邻近碳的远程偶合,这对归属不同的活泼氢在结构中所处的位置非常有效。(3) 变温实验识别活泼氢在活泼氢信号与其它信号发生重叠或部分重叠时,在1HNMR谱中往往不能肯定地识别活泼氢信号,这时样品管不要取出,接着做升温实验,一般可升到50-60度,温度升高活泼氢信号向高场位移。将常温测定的图谱与升温测定的图谱比较来识别活泼氢信号。
解析1HNMR图谱时识别活泼氢信号是解析图谱和鉴定结构必不可少的步骤.有时利用活泼氢信号可以确定基团(比如OH)的连接位置...下面是本人识别1HNMR图谱中活泼氢方法的经验体会,供大家参考,并请欢迎参加讨论,提出意见,谢谢.如果这些经验对同志们有参考价值,本人深感欣慰.1HNMR图谱中活泼氢的识别方法摘自:汪茂田等《天然有机化合物提取分离与结构鉴定》化学工业出版社,2004在1HNMR图谱中活泼氢信号变化多端,有的峰尖锐,有的峰较宽,有的峰积分面积明显较小,有的峰和其它质子信号重叠,有的峰几乎与图谱基线一致等。产生上述现象的原因一般分两类情况,也可以分为内因和外因。内因是指分子结构引起的,如羧基的活泼氢、螯合的羟基、烯醇羟基、酰胺的活泼氢和一些交换速度比较慢的活泼氢一般表现为宽单峰(br.s),交换速度快的活泼氢表现为比较锐的单峰,羟基质子和同碳氢发生偶合时则表现为三重峰(t)或二重峰(d)。外因 原则上是与样品浓度、温度、溶剂、样品中的水分等因素有关。但研究者关心的问题是如何如何识别活泼氢信号。下面介绍几种识别活泼氢信号的方法。(1)重水交换是最经典和常用的识别活泼氢的方法, 但也有不方便和不足之处。一是重水交换必需重新测定一次图谱,二是较大的水峰会干扰δ4.7ppm左右的样品信号。如果样品同时还要测定H-HCOSY和H-CCOSY谱的话,可用这些图谱来识别活泼氢,必要时再做重水交换实验,当然重水交换的优点是隐藏在其它信号中的活泼氢信号可以被消除。绝大多数情况下,重水交换的速度是很快的,有一些化合物,如酰胺的活泼氢交换速度较慢,加入重水后要放置一段时间或稍微加热后测定。(2)由H-CCOSY谱鉴别活泼氢信号因为活泼氢不和碳直接相连,故和碳没有相关峰的质子信号应是活泼氢的峰。所以当一个化合物同时有1HNMR和H-CCOSY 谱的话,就不必刻意由1HNMR谱识别活泼氢信号,两种谱结合起来问题就容易的多了。例如头孢噻呋的HMQC谱(图9-2)中的δ9.54(1H,d)信号没有和碳的相关峰,它是酰胺的活泼氢信号,δ7.16(2H,s)是NH2的信号,和碳没有相关峰。当活泼氢不和同碳质子发生偶合时,活泼氢在H-HCOSY谱中没有相关峰。当然要注意孤立质子的共振信号以及由于双面夹角接近或等于90°时的特定质子的信号 (单峰或宽单峰),但这些质子在H-CCOSY谱中有相关峰。在活泼氢与同碳质子发生偶合的情况下,缺乏经验的研究者可能不易从1HNMR和H-HCOSY图谱上看出来,这时可借助H-CCOSY谱来识别。 由HMBC谱也可以获得活泼氢连接位置的信息,当采用氢键溶剂如氘代二甲基亚砜或氘代吡啶测定NMR图谱时(要尽可能干燥),活泼氢由于能和溶剂形成氢键,使其不易发生交换而比较“固定”,在HMBC中可以检测出这些活泼氢与邻近碳的远程偶合,这对归属不同的活泼氢在结构中所处的位置非常有效。 (3) 变温实验识别活泼氢在活泼氢信号与其它信号发生重叠或部分重叠时,在1HNMR谱中往往不能肯定地识别活泼氢信号,这时样品管不要取出,接着做升温实验,一般可升到50-60度,温度升高活泼氢信号向高场位移。将常温测定的图谱与升温测定的图谱比较来识别活泼氢信号。
英文篇名】 Nonlinear Pattern Recognition of Metal Fracture Surface Images 【作者】 颜云辉 杨会林 王成明 【英文作者】 YAN Yun-hui YANG Hui-lin WANG Cheng-ming(Mechanical Engineering and Automation School Northeastern University Shenyang 110004 China. ) 【作者单位】 东北大学机械工程及自动化学院 辽宁沈阳 【刊名】 东北大学学报(自然科学版) , Journal of Northeastern University(Natural Science), 编辑部邮箱 2004年 09期 期刊荣誉:中文核心期刊要目总览 ASPT来源刊 中国期刊方阵 CJFD收录刊 【关键词】 金属断口 小波变换 特征提取 神经网络 非线性分类器 非线性模式识别 【英文关键词】 metal fracture surface image wavelet transform feature extraction neural network nonlinear classifier nonlinear pattern recognition 【摘要】 针对金属断口图像模式识别的特点,提出应用小波变换技术提取断口图像特征的方法,在此基础上,利用神经网络的基本原理设计了一种断口图像模式识别的非线性分类器通过实验确定了分类器的网络结构,给出了相关参数选择的方法对几种典型的金属断口图像进行了计算机实验研究实验结果表明,其平均正确识别率达93 75%,单独以能量作为特征值,其平均正确识别率可达到95%这说明采用非线性分类器进行断口模式识别比采用线性分类器能取得更高、更可靠的正确识别率研究结果显示出,这种基于小波变换技术和神经网络原理的非线性模式识别方法能对纹理变化复杂、规律性不强的断口图像进行有效识别,具有更好的适应性 【英文摘要】 Aiming at the characters of pattern recognition of fracture surface images, a character pick-up method by wavelet transform is proposed. Then, based on BP neural network theory, a nonlinear classifier is designed specially for such a pattern recognition, and its network structure was determined by test to give the way to choose parameters involved. Experimental investigations were carried out on computer aiming at several typical metal fracture surface images. The results showed that the average rate of cor... 【基金】 国家自然科学基金资助项目(50075016) 高等学校博士学科点专项科研基金资助项目(20020145023) 【DOI】 cnki:ISSN:1005-3026.0.2004-09-019 [img]http://www.instrument.com.cn/bbs/images/affix.gif[/img][url=http://www.instrument.com.cn/bbs/download.asp?ID=98689]金属断口图像的非线性模式识别方法[/url]
[font=宋体][font=宋体]化学模式识别([/font][font=Times New Roman]CPR[/font][font=宋体])是利用统计学、信号处理、数学等工具从化学量测数据中找出样本的特征,进而对样本进行识别和归类的一门技术。[/font][/font][img=,294,246,left]https://ng1.17img.cn/bbsfiles/images/2024/06/202406260948289055_2874_6418678_3.png!w294x246.jpg[/img][font=宋体][font=宋体]化学模式识别按照样品集有没有[/font][font=宋体]“教师信号”可以划分为无监督的模式识别和有监督的模式识别(。前者只有样本的光谱数据但样本的类别(属性、特征)未知,通过样本本身的光谱信息实现分类,包括主成分分析([/font][font=Times New Roman]PCA[/font][font=宋体])、系统聚类分析([/font][font=Times New Roman]HCA[/font][font=宋体])等。后者是用一组已知类别的样本作为训练集建立分类模型,或称类模型,然后,再利用模型对待测样本的类别进行预测,包括偏最小二乘[/font][font=Times New Roman]-[/font][font=宋体]判别分析([/font][font=Times New Roman]PLS-DA[/font][font=宋体])、支持向量机([/font][font=Times New Roman]SVM[/font][font=宋体])、人工神经网络([/font][font=Times New Roman]ANN[/font][font=宋体])等。[/font][/font][b][b][font=宋体]一、主成分分析[/font][/b][/b][font=宋体][font=宋体]主成分分析([/font][font=Times New Roman]PCA[/font][font=宋体])[/font][/font][sup][font='Times New Roman'][1][/font][/sup][font=宋体][font=宋体]是一种多元统计分析方法,它是使用最广泛的数据降维以及无监督的聚类方法。[/font][font=Times New Roman]PCA[/font][font=宋体]的主要原理是将[/font][/font][i][font='Times New Roman']n[/font][/i][font=宋体]维特征映射到[/font][i][font='Times New Roman']k[/font][/i][font=宋体]维上,这[/font][i][font='Times New Roman']k[/font][/i][font=宋体]维是全新的正交特征也被称为主成分,是在原有[/font][i][font='Times New Roman']n[/font][/i][font=宋体]维特征的基础上重新构造出来的[/font][i][font='Times New Roman']k[/font][/i][font=宋体][font=宋体]维特征。[/font][font=Times New Roman]PCA[/font][font=宋体]就是从原始的空间中顺序地找一组相互正交的坐标轴,其中,第一个新坐标轴选择是原始数据中方差最大的方向,第二个新坐标轴选取是与第一个坐标轴正交的平面中使得方差最大的,第三个轴是与第[/font][font=Times New Roman]1,2[/font][font=宋体]个轴正交的平面中方差最大的。依次类推,可以得到[/font][/font][i][font='Times New Roman']n[/font][/i][font=宋体]个这样的坐标轴。通过这种方式获得的新的坐标轴,大部分方差都包含在前面[/font][i][font='Times New Roman']k[/font][/i][font=宋体][font=宋体]个坐标轴中,后面的坐标轴所含的方差几乎为[/font][font=Times New Roman]0[/font][font=宋体]。于是,只保留前面[/font][/font][i][font='Times New Roman']k[/font][/i][font=宋体][font=宋体]个含有绝大部分方差的坐标轴,而忽略余下的坐标轴,就可以实现对数据特征的降维处理。在降维后的二维或者三维主成分图中,可以将样本的分类进行可视化,如图[/font][font=Times New Roman]5-8[/font][font=宋体]所示。[/font][/font][b][b][font=宋体]二、系统聚类分析[/font][/b][/b][img=,275,233,left]https://ng1.17img.cn/bbsfiles/images/2024/06/202406260948458070_6984_6418678_3.png!w275x233.jpg[/img][font=宋体][font=宋体]作为一种无监督模式识别方法,系统聚类分析([/font][font=Times New Roman]H[/font][/font][font='Times New Roman']ierarchical [/font][font=宋体][font=Times New Roman]c[/font][/font][font='Times New Roman']luster [/font][font=宋体][font=Times New Roman]a[/font][/font][font='Times New Roman']nalysis[/font][font=宋体][font=Times New Roman],HCA[/font][font=宋体])[/font][/font][sup][font='Times New Roman'][55][/font][/sup][font=宋体][font=宋体]是聚类分析中应用最为广泛的方法。该方法的基本思想是首先将参加聚类的样本各自看成一类,然后定义样本之间以及类与类之间的相似度(距离),最后在自成类的样本中选择距离最近的样本合并为一个新类,重新计算新类和其他类之间的距离,并按最小距离并类,如此重复,每次减少一类,直至所有的样本并为一类为止。最终输出一个具有层次结构的聚类结果,如图[/font][font=Times New Roman]5-9[/font][font=宋体]所示。在[/font][font=Times New Roman]HCA[/font][font=宋体]中,类内距离和类间距离都有多种方法可供选择。常见的类间距离有马氏距离([/font][font=Times New Roman]Mahalanobis[/font][font=宋体])、欧氏距离([/font][font=Times New Roman]Euclidean[/font][font=宋体])、标准化欧氏距离([/font][font=Times New Roman]seuclidean[/font][font=宋体])、城市街区距离([/font][font=Times New Roman]cityblock[/font][font=宋体])、明氏距离([/font][font=Times New Roman]Minkowski[/font][font=宋体])、切比雪夫距离([/font][font=Times New Roman]Chebychev[/font][font=宋体])和夹角余弦相似系数([/font][font=Times New Roman]cosine[/font][font=宋体])等多种形式。类内距离有最长距离法([/font][font=Times New Roman]complete[/font][font=宋体])、最短距离法([/font][font=Times New Roman]single[/font][font=宋体])、类平均法([/font][font=Times New Roman]average[/font][font=宋体])、重心法([/font][font=Times New Roman]centroid[/font][font=宋体])、加权平均距离法([/font][font=Times New Roman]weighted[/font][font=宋体])、中间距离法([/font][font=Times New Roman]median[/font][font=宋体])和[/font][font=Times New Roman]Ward[/font][font=宋体]离差平方和等多种形式。[/font][/font]
大家好,有一个问题困扰我比较久了,希望有人能够帮帮我,解答我的问题。问题就是:一般情况下我们是通过保留时间识别不同的色谱图中的色谱峰其实是同一种物质,可是实际跑图过程中我们也会发现,比如走含量,双标双样,每个走两针,八针走下来,保留时间呈线性变化,后一针比前一针保留时间少个零点几秒。可是,如果走的是测有关物质的图,某一个物质的要求是不能检出,可是如果单纯的通过保留时间识别峰的话,不太好说不能检出的那个物质就一定没检出来,所以我想问一下,有没有除了保留时间,其它的判断识别峰的方法?先谢谢大家的回答了,谢谢。
国家级期刊正规性识别方法[size=4][b]1 国内合法期刊与非法期刊[/b][/size] 国内期刊分为正式期刊和非正式期刊,正式科技期刊是由国家新闻出版署与国家科委在商定的数额内审批,并编入“国内统一刊号”,办刊申请比较严格,要有一定的办刊实力,主编与副主编必须由高级专业技术职务的人员担任,对编辑人员的素滞名额都有一定的要求,正式期刊有独立的办刊方针。非正式期刊是指通行政部门审核领取“内部报刊准印证”作为行列内部交流的期刊(一般只限行业内交流不公开发行),但也是合法期刊的一种,一般正式期刊都经历过非正式期刊过程。非法期刊系没有通国家新闻出版署和国家科委批准也没有注册为"内部刊物"的非法出版物,以营利为首要目的,收取高额的版面费,在技术上和政治上不负责任,不能在国内公开发行或内部发行,它们通常是在国外花300元购买一个ISSN刊号来欺骗教师。 [size=4][b]2 国内期刊刊号问题[/b][/size] 凡通过国内新闻出版署和国家科委审批的正式期刊均编入了“国内统一刊号”,正式期刊的刊号是由国际标准刊号(ISSN)和国内统一刊号(CN)两部分组成(境外期刊在国内合法发行须经新闻出版署备案并由中图公司等批准颁发书刊编号),“CN”是中国国别代码,缺少“国内统一刊号(或国内批准的书刊编号)”或“内部报刊准印证”都可认为是中国国内的非法期刊,国家不认可,也不准在中国国内发行的。 [size=4][b]3 识别国内公开发行的正式期刊方法[/b][/size] 国内公开发行的期刊允许在国内外发行,有国内统一刊号,其刊号结构式为:CN报刊登记号/分类号,只有ISSN国际刊号而无国内统一刊号不允许在国内公开发行,有的印有CN(HK)或CNXXX(HK)/R这是国内不法分子欺骗那些急于想发论文评职称的读者而编造的国内刊号.合法的国内统一刊号需注意,国内正式期刊一般有国内国家机关主管单位(不是什么中国/中华XX协会),并有详细的编辑出版通信地址和印刷出版地都在国内,除自办发行外大多通过邮局征订和发行,故常常有邮发代码。而非法期刊只有国际标准刊号或乱造的国内CN刊号,即使“内部报刊准印证”也没有。 综上所述,在世界公开发行有一定影响力的的并且有国内批准发行的书刊编号的国际级期刊杂志上发表论文,可以用于作者提高自己的国际知名度和影响力,当然在非法期刊上发表的论文在国内可能不会被承认的.对职称评定应该说没有意义,至于如何抵制这些“非法期刊”盛行,一方面国内新闻出版部门应对这类“期刊”进行严肃查处,阻止合法报刊为这类“期刊”广告外,还要劝告大家不要上当受骗,学会识别非法期刊. CN刊号标准格式是:CN XX-XXXX,其中前两位是各省、自治区、直辖市地区号,其中印有CN(HK/H)或CNXXX(HK)/NR/R这不是合法的国内统一刊号。 格式中前两个XX代码如下: 11.北京市 12.天津市 13.河北省 14.山西省 15.内蒙古自治区 21.辽宁省 22.吉林省 23.黑龙江省 31.上海市 32.江苏省 33.浙江省 34.安徽省 35.福建省 36.江西省 37.山东省 41.河南省 42.湖北省 43.湖南省 44.广东省 45.广西壮族自治区 46.海南省 47.备用号 48.备用号 49. 备用号 50.重庆市 51.四川省 52.贵州省 54.西藏自治区 61.陕西省 62.甘肃省 63.青海省 64.宁夏回族自治区 65.新疆维吾尔自治区 国家规定,如果在异地办刊并出版,也是属于非法出版活动.如果投稿朋友们发现不在以上地区编号的期刊应该可以对照判断了.

[color=#333333]荠菜是一种可以食用的野菜,荠菜的营养价值非常的高,同时也具有很高的药用价值。[/color][align=center][color=#333333][img=,554,380]http://ng1.17img.cn/bbsfiles/images/2018/04/201804171553442478_2961_676_3.png!w554x380.jpg[/img][/color][/align][color=#333333][b]药用价值:[/b][/color][color=#333333][color=#333333]1荠菜中含有荠菜酸,荠菜酸能够缩短出血时的凝血时间,起到快速止血的作用。[/color][/color][color=#333333][color=#333333]2[color=#333333]荠菜中的乙酰胆碱,谷甾醇和季胺化合物有治疗高血压的作用,还有降低血液和肝内胆固醇及甘油三酯含量的作用。[/color][/color][/color][color=#333333][color=#333333]3[color=#333333]荠菜中所含有的登皮甙可以起到增强体内维生素C含量防冻伤,消炎抗菌的作用。[/color][/color][/color][color=#333333][color=#333333][color=#333333]4荠菜中的大量维生素C可以组织致癌物质在消化系统里的生成,具有预防胃癌及食道癌的作用。[/color][/color][/color][color=#333333][color=#333333][color=#333333]5荠菜中还有大量的粗纤维,能够促进身体排泄功能,增进身身体新陈代谢的作用,有助于减肥,及防治糖尿病等疾病的作用。[/color][/color][/color][color=#333333][color=#333333][color=#333333] 6荠菜中的胡萝卜素具有明目的功效,可以有效的治疗干眼病以及夜盲症。[/color][/color][/color][color=#333333][color=#333333][color=#333333][b]识别方法[/b][/color][/color][/color][color=#333333][color=#333333]1[color=#333333]幼年期的荠菜会比较难以分辨一些,这时它和蒲公英长得很像,但是荠菜发芽比较早,而且叶子凹凸不平,就像长着很多片小叶子一样,它一般不会贴在地上,叶子会相对竖立起来[/color][/color][/color][align=center][color=#333333][color=#333333][color=#333333][img=,545,369]http://ng1.17img.cn/bbsfiles/images/2018/04/201804171556548951_9551_676_3.png!w545x369.jpg[/img][/color][/color][/color][/align][align=left][color=#333333][color=#333333][color=#333333]2幼年期的荠菜,叶子呈新绿色,而且叶子不会太长,叶子背面没什么毛,相对来说较为光滑.[/color][/color][/color][/align][align=center][color=#333333][color=#333333][color=#333333][img=,561,360]http://ng1.17img.cn/bbsfiles/images/2018/04/201804171557367660_5040_676_3.png!w561x360.jpg[/img][/color][/color][/color][/align][align=left][color=#333333][color=#333333][color=#333333]3成年的荠菜相对来说比较好辨认,一般它会有四五根花杆子直立起来,就像韭菜花、蒜苗花那样,立起来而且比较高,但是杆子是圆形的,上面会有分叉,也会有叶子[/color][/color][/color][/align][align=center][color=#333333][color=#333333][color=#333333][img=,542,445]http://ng1.17img.cn/bbsfiles/images/2018/04/201804171559000416_551_676_3.png!w542x445.jpg[/img][/color][/color][/color][/align]
怎么准确识别样品中的这个色谱峰就是目标峰啊?就是怎么确定时间带或时间窗?
[font=宋体]奇异样本的识别方法大致可以分三类:经典识别方法、稳健识别方法和基于统计学的识别方法(如蒙特卡罗交叉验证)等。经典识别方法包括残差法(包括普通残差、标准化残差、学生化残差)、马氏距离、杠杆值和主成分得分图。稳健识别方法包括基于稳健距离估计的识别方法和基于稳健回归估计的识别方法。基于稳健距离估计的识别方法包括椭球多变量修剪法、最小体积椭球估计、[/font][font=宋体]最小协方差行列式法、最小半球体积法和半数重采样法等。基于稳健回归估计的方法包括最小一乘估计、[/font][i][font='Times New Roman']M[/font][/i][font=宋体]估计、[/font][i][font='Times New Roman']S[/font][/i][font=宋体]估计、[/font][i][font='Times New Roman']MM[/font][/i][font=宋体][font=宋体]估计、最小中位方差估计和最小方差修剪估计等。基于统计学的识别方法通过蒙特卡罗交叉验证建立大量的模型,然后,通过统计参数把奇异样本识别出来,使奇异样本识别结果更加可信。[/font][/font]
[color=#444444]请教一下,[url=https://insevent.instrument.com.cn/t/Mp]气相色谱[/url]峰识别参数(如:斜率、面积/峰高、半高峰宽)要如何设置,才能使一些较小的峰识别出来,但是又不会将噪声小峰也识别出来?[/color]
使用的安捷伦8860[url=https://insevent.instrument.com.cn/t/Mp]气相色谱仪[/url] 更换了一个色谱柱后 分析氯乙烯中的乙炔和氯化氢含量 氯化氢数据还好 识别峰面积在2500左右 乙炔气几乎没有峰面积识别不出来是怎么回事 求助如何解决

【专家讲座】:第七讲:红外光谱模式识别【讲座时间】:2016年1月7日 14:00【主讲人】:陈建波 (清华大学分析中心,多年来一直从事红外光谱的研究工作。)【会议简介】内容提要:距离、相关系数等红外光谱差异量化参数,数据预处理,主成分分析、系统聚类法等无监督模式识别方法,距离或相关系数判别法、软独立建模聚类分析法、人工神经网络等有监督模式识别方法,红外光谱模式识别模型的建立、验证、评价与优化。-------------------------------------------------------------------------------1、报名条件:只要您是仪器网注册用户均可报名,通过审核后即可参会。2、报名并参会用户有机会获得100元手机充值卡一张哦~3、报名截止时间:2016年1月7日 13:304、报名参会:http://www.instrument.com.cn/webinar/meeting/meetingInsidePage/17625、报名及参会咨询:QQ群—1716924833http://ng1.17img.cn/bbsfiles/images/2017/10/2015042911235201_01_2507958_3.jpg
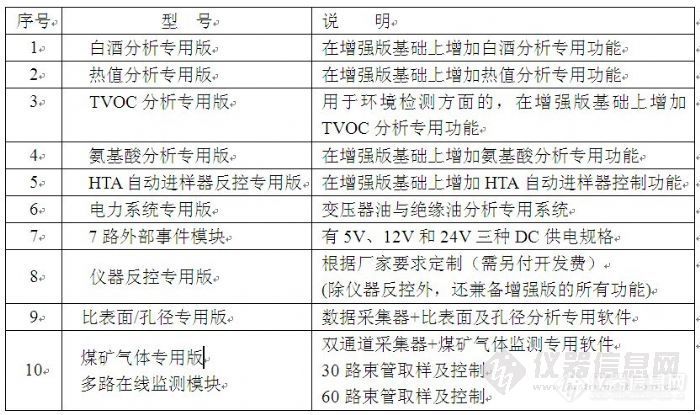
首先,我们来说说评价一个工作站的好坏。我认为一般评价一个工作站的好坏是从四个方面来看。第一、准确性;第二、重复性;第三智能化程度;第四、功能。那对照这四点我们来看看SEPU3010的工作站吧。 1、准确性好:1)色谱工作站对峰参数的识别方法需要一个长时间的积累和沉淀,而峰参数也会直接影响报告的准确性,SEPU3010色谱工作站的算法是在十五年积累的谱图基础上完善的,通过智能筛选,对比,最终确认最接近于真值的峰参数,保证了色谱峰面积计算的准确性。2)色谱工作站的检测报告的准确性主要取决于色谱峰面积计算的准确性,色谱峰面积计算的准确性则取决于起点、顶点、终点能否准确的识别,SEPU3010色谱工作站的算法保证了顶点始终是在最高点上,起点与终点始终是在最合理的切线上,从而最终保证了峰面积计算的准确性。这个特点可以用最简单的方法去识别,就是将谱图的这三个点放大,看微观。3)SEPU3010色谱工作站在采样精度方面有着无可比拟的优势工作站硬件采样精度高主要取决于两个方面,一方面是采样频率,一方面是采样范围。采样频率是指每秒采集到的数据点数,频率越低精度越差,SEPU3010色谱工作站的采样频率是2.5Hz、5Hz、10Hz、20Hz、40Hz五档。不同的频率保证了工作站硬件采样精度高,也保证了工作站可以适用于不同的色谱仪器, 10Hz是最常规的应用,2.5Hz、5Hz适合于逆流色谱、制备色谱等需要超长时间采集保存数据的仪器,20、40Hz适用于毛细管气相色谱仪等出峰很细尖的仪器。采样范围是指所能采集的电压信号范围,SEPU3010色谱工作站可以采集到-1250mV到+1250mV范围之内的信号,最低可以采集1 μV的信号值。这样,也充分保证了采样的精度高。2、重复性好:色谱工作站的重复性取决于色谱峰面积和工作站硬件的重复性。SEPU3010色谱工作站对峰参数的识别方法需要一个长时间的积累和沉淀,而峰参数也会直接影响报告的准确性,SEPU3010色谱工作站的算法是在十五年积累的谱图基础上完善的,使得工作站能够识别各种条件下的不同谱图,保证了峰面积重复性非常好。手动事件功能也保证的不同条件下的手动事件完全重复。硬件精确保证了不同批次产品之间产重复性。3、智能化程度高:1)智能识别USB端口并设置工作站硬件;2)智能检测识别基线噪声和峰宽,一套参数适用于大部分的仪器及使用方案;3)智能判别各种峰类型,如拖尾峰、重叠峰、肩峰等。4)智能检测并识别负峰5)智能手动事件识别功能4、功能强大:1)SEPU3010色谱工作站可以将分析结果输出成txt、excel等格式;2)SEPU3010色谱工作站具有重复性报告功能,即可以将6个谱图叠加打印,以更好的计算重复性;3)SEPU3010色谱工作站具有分组计算功能,即可以将结果中相同类别的组分合并5、SEPU3010色谱工作站的特点:1)采用电脑的USB直接采集信号与供电,无需单独的电源。还可以避免用户因为电脑没有串口(RS232口)而无法使用色谱工作站。2)SEPU3010色谱工作站适用广泛,对于不同类型、不同产地的色谱仪器,都可适用。3)可以根据客户的特殊需要进行个性化开发(备注:需支付相关的开发费用)4)SEPU3010色谱工作站拥有针对不同行业的10个专用版本http://ng1.17img.cn/bbsfiles/images/2011/04/201104141116_288708_1796111_3.jpg
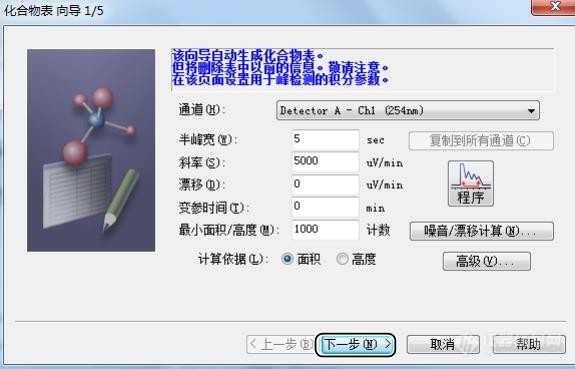
[align=left][font=宋体]样品进样完成后,最终都要处理数据。这时候我们需要筛选出对应的色谱峰,制作对应的曲线,得出正确的结果。[/font][/align][font=宋体]岛津软件需要制作化合物表,我们筛选出正确的色谱峰添加到化合物表中,方法有种方法。[/font][font=宋体]第一种可以使用化合物向导,中间可以进行积分、峰识别以及将定量处理参数输入到连[/font][font=宋体]续窗口中。[/font][font=Calibri] [img=,575,369]https://ng1.17img.cn/bbsfiles/images/2023/10/202310030933375259_1609_5979722_3.jpg!w575x369.jpg[/img][/font][font=宋体][font=宋体]点击左侧的向导,半峰宽、斜率、漂移、最小面积等这些参数(这些参数的设置都是为了排除不需要的色谱峰,比如最小面积设置为[/font][font=Calibri]1000[/font][font=宋体],则面积小于[/font][font=Calibri]1000[/font][font=宋体]的色谱峰就不进行积分)基本都可以默认,点击下一步。[/font][/font][font=Calibri] [img=,576,366]https://ng1.17img.cn/bbsfiles/images/2023/10/202310030933458986_2400_5979722_3.jpg!w576x366.jpg[/img][/font][font=宋体]这时候参考标准物质的出峰时间,勾选对应保留时间的色谱峰。继续下一步[/font][font=宋体] [img=,574,356]https://ng1.17img.cn/bbsfiles/images/2023/10/202310030933543930_8576_5979722_3.jpg!w574x356.jpg[/img][/font][font=宋体]选择正确的定量方法、浓度、级别数等。继续下一步[/font][font=宋体] [img=,576,369]https://ng1.17img.cn/bbsfiles/images/2023/10/202310030934028286_5423_5979722_3.jpg!w576x369.jpg[/img][/font][font=宋体]然后设置识别方法、窗宽以及其他参数等。继续下一步[/font][font=宋体] [img=,569,359]https://ng1.17img.cn/bbsfiles/images/2023/10/202310030934109321_2525_5979722_3.jpg!w569x359.jpg[/img][/font][font=宋体]进入化合物表,设置对应的浓度等信息,点击完成。[/font][font=宋体] [img=,569,359]https://ng1.17img.cn/bbsfiles/images/2023/10/202310030934197922_3795_5979722_3.jpg!w569x359.jpg[/img][/font][font=宋体]最终应用到方法。[/font][font=宋体] [/font][font=宋体]第二个方法,直接打开单个数据文件,用鼠标右键单击所需峰的峰号,然后单击将选择峰记录到化合物表。[/font][font=Calibri][font=宋体]在方法视图里单击化合物标签。在化合物表中输入登录峰的化合物名和浓度[/font][/font][font=宋体],在显示峰定位线的时候,使用鼠标可简单设置化合物表内的保留时间。最终应用到方法。[/font][font=Calibri] [img=,690,465]https://ng1.17img.cn/bbsfiles/images/2023/10/202310030934352396_4572_5979722_3.jpg!w690x465.jpg[/img][img=,563,457]https://ng1.17img.cn/bbsfiles/images/2023/10/202310030934463920_6334_5979722_3.jpg!w563x457.jpg[/img][/font][font=宋体]第三个方法,直接[/font][font=Calibri][font=宋体]在方法[/font][/font][font=宋体]编辑[/font][font=Calibri][font=宋体]里单击化合物标签。在化合物表中[/font][/font][font=宋体]手工[/font][font=Calibri][font=宋体]输入登录峰的化合物名和浓度[/font][/font][font=宋体],在显示峰定位线的时候,使用鼠标可简单设置化合物表内的保留时间。最终应用到方法。[/font][font=宋体] [img=,563,457]https://ng1.17img.cn/bbsfiles/images/2023/10/202310030934463920_6334_5979722_3.jpg!w563x457.jpg[/img][/font][font=宋体]这三种方法各有特点,大家可以灵活运用。[/font][font=宋体] [/font][font=Calibri] [/font][font=Calibri] [/font]
使用的是安捷伦 8860[url=https://insevent.instrument.com.cn/t/Mp]气相色谱仪[/url] 更换了色谱柱后 分析氯乙烯中的乙炔和氯化氢含量 氯化氢峰面积在2500左右 含量还算正常 可乙炔多次进样识别不到峰面积从而检测的含量极小 请问是什么原因导致的 更换色谱柱后需要重新设置什么吗?
各位仁兄请帮帮忙,我想学GC-MS,请高手给予指点,怎样识别色谱峰
在操作条件没有限制的条件下,出来的色谱峰可以无限宽吗?在安捷伦的化学工作站的描述中有这样一句话:积分器利用集束方法将加宽的峰保持在峰识别过滤器的有效范围内。是不是说,如果峰无限宽,就无法识别,也就会检测不出来。
液相色谱手性识别机理的研究进展黄君珉 陈慧 王琴孙(南开大学元素有机化学研究所 天津 300071)近20年来人们对于用高效液相色谱分离对映体的兴趣与日俱增,发展高效的手性固定相(简称CSP)成为这一领域最活跃的部分,而与之相应的色谱手性识别机理的研究相对来说比较少。但研究色谱拆分机理又是非常重要的,这有利于获得对手性识别更深入的理解,可以指导研制高效的CSPs及预示手性拆分的可能性,而且对理解手性药物的药理、药物设计、生命化学中的立体化学问题等都具有重要意义[1]。物质对映异构体,仅在分子结构上具有不可重叠性。在对称的环境里,无论是气体、固体、或是溶液、液体状态都表现出完全相同的物理化学性质。不管哪一种色谱,为了使互为对映体的物质转化为化学和物理性质不同的非对映体,多宜提供一个手性源,使欲分离的对映体(样品)和手性源(例如:手性固定相)之间形成一个非对映异构分子络合物[2]。非对映分子复合体属于不同的点群。仅对称性的不同,在色谱上是不能被“识别”的,从热力学过程的角度来说,二者必须有一定的自由能差别。1 手性分离的热力学液相色谱手性固定相法直接拆分对映体,在色谱柱内存在着如下的平衡[3]:经典热力学中自由能变化(DG)与焓(DH)、熵(DS)的关系遵从Gibbs方程:DG = DH - TDS 在液相色谱中,保留参数即容量因子k’与溶质在流动相-固定相的热力学平衡常数K的关系为:k’= fK(f是色谱柱相比)。对映异构体选择性a = k’R / k’S (k’R k’S)。色谱过程的自由能变化可以表示成:DG = -RTlnK = -RTln(k’/f) 因此,不难导出:lnK = (-DH/R) × 1/T + DS/R (1) -DR,SDG0 = RT lna = -DR,S DH 0 + TDR,S DS0 lna = (-DR,SDH0/R) × 1/T + DR,SDS0/R (2) 式(1)、(2)表明lnK~1/T、lna~1/T呈线性关系,如图1[4,5]所示:图1 温度对形成非对映异构分子络合物的热力学平衡常数和对映异构体选择性的影响在倒转温度Tinv时,非对映异构分子络合物的热力学平衡常数KR = KS,对映异构体同时流出,在该温度时无对映异构体选择性,aR,S = 1,理论上是由于:lna = (-DR,SDH/R) × 1/T + DR,SDS/R = 0 即: (-△R,S△H/R) × 1/Tinv = DR,SDS/R -DR,SDH = TinvDR,SDS 在该点的两边,温度对对映异构体选择性系数的影响刚好相反,而且溶质对映体流出顺序相反。该点的右边,即:TTinv,色谱手性识别过程为熵变占优势,随着温度的升高,a增大。在手性识别研究中,对映异构体流出顺序在不同温度下倒转的现象迄今只有少量的报道。由于高效液相色谱的温度变化范围较窄,大多数情况下,Tinv不在该温度范围内,并且TTinv,色谱手性识别过程焓变占优势,a值随着温度的升高而降低[6]。手性色谱的对映体分离是一个复杂的色谱过程,Pirkle[7]曾报道了lnK~1/T非线性的实验结果。因此,在不同温度下得到不同的对映体流出顺序也可能是手性色谱保留和拆分机理的改变造成的。图2 N-(3, 5-二硝基苯甲酰基)-亮氨酸正己酰胺及所用手性固定相的结构Pirkle[2]和Davankov等曾分别研究了手性色谱分离对映异构体选择性a和非对映异构体络合物自由能之差(DDG)之间的关系:DR,S DG = -RT lna,考虑到实际的色谱分离过程,非常小的热力学选择性DDG,如果DDG = 0.024 kJ/mol,就可以得到一定的拆分,a = 1.01。随着DDG 的增加,对映体选择性将表现为相应的指数级增长。Pirkle等用实验印证了这种关系[8],在图2所示的CSP上,用30% 异丙醇/正己烷为流动相,N-(3, 5-二硝基苯甲酰基)-亮氨酸正己酰胺的对映异构体选择性测定值a = 10.5,其中(S)-对映体保留较长,相互作用能之差DDG = -5.93 kJ/mol。同样,对具有两个手性中心如图3所示化合物的(SS), (RR)对映体,可以预料:由于手性中心相隔较远,与CSP作用的自由能之差为2DD Gm ,实验所得的手性选择性a为121,大致为前者的平方值a2。后来,Pirkle等再次通过设计出相应的实验提出了这样的论断[9]:具有两个溶质-CSP相互作用部位产生的对映异构体选择性大致为只有一个作用部位所取得的对映异构体选择性值的平方。图3 (SS),(RR)对映体化合物的结构Boehm等[10]用统计热力学理论研究了化学键合手性固定相上溶质对映异构体(AR、AS)的保留行为和分离模式:k’= exp(-bDA) 其中b = 1/(kT),bDA为溶质由流动相到固定相传质过程的Helmholtz自由能,因此:a = ∑iexp(-bEiR)/∑jexp(-bEjS) 其中EiR和EjS分别为R-体(AR)和S-体(AS)在CSP上第i种和第j种作用能。并认为CSP与A的4种一点作用、36种两点作用、12种三点和四点作用中,只有三点和四点作用存在手性识别能力。如果只有一种优势识别模型,则lna 与1/T呈线性关系。Berthod等[11]用热力学方法研究手性识别中手性碳原子所连四个基团各自对手性识别的贡献,分析了126个化合物中81种与手性碳相连的基团,并设氢取代时DG = 0,化合物上各基团独立与CSP作用,在E = ∑|acal - aobs|最小化条件下解如下方程:D(DGA)=(DGA11-DGA12)+(DGA21-DGA22)+(DGA31-DGA32)+(DGA41-DGA42) 定量给出了各个基团对手性识别的贡献(CSP为S-NEC-CD和R-NEC-CD),并发现SP2杂化的碳与手性中心相连比SP3杂化的碳手性识别能力强。该方法只能预示对映体能否被拆分,而不能预示流出顺序。图4 形状选择性的识别模型图5 分子形状和相互作用力共同参与而形成手性识别的模型2 手性识别模型目前,关于手性识别的一般机理众说纷纭。在手性色谱学这一领域,早在1952年,Dalgliesh[12]采用纸层析研究氨基酸对映体的分离时就提出了色谱直接拆分“三点作用”分离理论。后来,Lochmüler和Dobashi提出“两点作用”模型;Lochmüler和Wainer提出“单点作用”机理,Lochmüler进一步提出某些系统存在“环境手性”而没有专一的作用点。对映体的拆分过程可以是熵控制的,手性识别源于形状选择性的识别模型(图4)。也就是说,在没有结合点(如氢键、色散力、偶极作用、p-p相互作用等)的手性环境里,熵控制下,对映体在色谱过程中是可以被拆分的。事实上,由于熵变化值较小,从而导致a 值不够显著,因此,能够通过增加作用点来提高手性选择性值,识别模型如图5所示,对映体的拆分源于分子形状和相互作用力的共同贡献。近些年来,Pirkle等[2]在深入研究手性固定相以及手性色谱立体识别机理的过程中,发展了Dalgliesh观点,再一次阐述了“三点作用”分离理论:手性识别要求手性固定相和对映异构体之间至少有三个同时存在的作用力,这些作用力中至少有一个依赖于立体化学。也就是说,用其中的另一对映异构体(不作任何构象改变)来替代后,至少有一个作用力不复存在或明显改变其性质。用如图6所示的手性识别模型表达:在手性固定相上有三个作用点A、B、C,与之作用的对映异构体也同样有三个作用点A’、B’、C’。对映体I与CSP形成A-A’、B-B’、C-C’三个作用力,对映体II则不存在C-C’作用力。如果C-C’作用力使形成的非对映分子络合物稳定化,那么,色谱分离过程中对映体I比II滞后;反之,对映体I由于C-C’的排斥作用先流出色谱柱。如果C-C’作用力很小,则对映体I、II不能被色谱拆分。图6 色谱手性识别的“三点作用” 模型图7 相似的相互作用力(A-A’, B-B’)导致色谱手性识别能力的降低或消失1992年,Taylor等[13]对“三点作用”原理评述认为:对映体与CSP的三个作用力中,至少有一个力具有立体选择性即依赖于对映异构体和CSP的立体化学,而另外两个作用力必须是两种不同类型的作用力,如氢键、偶极作用、 p-p作用等,否则如果存在两个相同的作用力,则可能产生不利的作用,使得CSP的手性识别能力降低或消失,例如当A-A’和B-B’作用力相同时,就可能使CSP失去手性分离能力(图7)。事实上,手性色谱分离中有的对映体确实是靠氢键这一种类型的力在CSP上识别的[13,14],这种手性识别可以认为是对映异构体和手性固定相形成非对映异构络合物的分子构象不同,使得其平衡常数K1、K2不同。另一方面,“三点作用”原理要求CSP分子和待分离对映异构体的手性中心附近都要有一定的刚性,柔韧性过强将会使手性识别能力丧失,如图8所示。“三点作用”原理与Ogston [15]为解释酶催化反应的立体专一性而提出的“三点键合”原理不同,二者的区别在于:“三点作用”原理没有要求三点都是吸引力。在许多情况下,手性识别可以靠空间位阻的排斥力和两个吸引力来实现(图9),对映体II由于其大基团的空间位阻,使得其另外的氢键和p -p 作用明显减弱。这种作用已被NMR分子间的核极化效应[16]和分子机理计算[3,17]所证实。表现在色谱过程中,对映体II的保留时间会低于对映体I。分子间作用力的单点性和多点性的特征由Pirkle等给出了明晰的描述[2]:两个凸圆面相互接触时,接触处形成一个理想的点,于是将凸圆形电子轨道的相互作用描述成单点性的

【1.茶叶】警惕:铅铬绿染色,提防颜色太鲜艳。识别方法:铅铬绿是一种工业颜料,具有毒性,正常“碧螺春”色泽比较柔和鲜艳,加铅铬绿的“碧螺春”发黑、发绿、发青、发暗;用开水冲泡后,正常“碧螺春”看上去柔亮、鲜艳,加色素的看上去比较黄暗。http://ng1.17img.cn/bbsfiles/images/2014/06/201406121422_501908_2433088_3.jpg
新手一枚,做TVOC检测时,对未识别的峰,应以甲苯计。意思我理解,但是我不知道怎么具体怎么操作,用的[url=https://insevent.instrument.com.cn/t/Mp]气相色谱仪[/url]是[font=&]岛津GC2014,有大神指点指点吗?[/font]
1.关于色谱积分,想请教各位大神,什么样的情况可以采用谷到谷积分,又在什么样的情况下可以采用垂线积分,有大神知道具体依据没?如果出现一个小的杂质峰,但是附近基线走的不好(有点有点像双峰的感觉),又该如何合理积分?2.关于数据处理,按照GMP要求:是不是每次数据处理方法必须要一致,不允许有任何改动?如果是,具体原则是什么,出于药典哪条法规?3.峰识别,系统溶液中各组分峰的保留时间与样品中相应组分峰之间的保留时间相差多少,是可以被接受的?这个问题同样站在审计角度!
跑了6中有机磷农药标线都做好了走精密度,加载方法的时候,4个物质出现“没有识别到峰”的现象看了目标峰保留时间有点偏差,所以试着增大保留时间的比率,还是不行调谐昨天调的,没问题
NETPEAK软件,标准里设置好各个峰的起止时间了,样品里明明有该峰,但是软件识别不出,是保留时间有漂移超过一定值的原因吗?(该值怎么调整?因为可以确定它们是同一个峰),另外,能否把标样和样品里同一个峰设置为不同的时间范围进行积分?请指教。
下图是对照品中待测组分,上图是样品。这次的样品里在待测物峰附近有俩小杂峰,出峰时间对不上,明显不是待测物。可谱图上识别成待测物了,要怎么调整?[img]https://ng1.17img.cn/bbsfiles/images/2020/03/202003170811121045_6606_2561261_3.png[/img]
ICP-AES光谱干扰校正方法的研究沈兰荪著 北京工业大学出版社1997年出版简介ICP-AES(电感耦合等离子体原子发射光谱)分析技术作为一种重要的元素分析技术,在国民经济与科学研究的各个方面得到了广泛的应用,光谱干扰的校正是ICP-AES分析技术进一步发展的一个关键问题。本书是一本关于ICP-AES分析技术的专著,研究用现代信号处理的观点与方法校正ICP-AES分析中的光谱干扰,全书共分7章,第1章绪论,第2章ICP-AES分析技术为全书的基本,第3章至第6章,分别讨论了“谱线拟合法”“自适应滤波法”“卡尔曼滤波算法”及“基于数字化谱的方法”等4种主要的校正方法,第7章为光谱干扰的实时校正。本书可供有关专业 高校教师、研究生、高年级大学生、科研人员及工程技术人员使用。目 录前 言第1章绪论1.1ICP-AES中的光谱干扰1.2化学计量学的发展1.3本书内容介绍第2章 ICP-AES分析技术2.1原子发射光谱2.2 ICP-AES分析仪器 2.2.1概述 2.2.2现代ICP-AES分析仪器的典型结构 2.2.3ICP-AES仪器的分析性能 2.2.4仪器函数2.3ICP-AES中光谱干扰校正概述 2.3.1ICP-AES中的干扰现象 2.3.2背景干扰的传统校正方法 2.3.3谱线重叠干扰的传统校正方法 2.3.4传统校正方法的改进2.4讨论第3章 谱线拟合法3.1光谱干扰的数学模型3.2谱线拟合的数学基础 3.2.1Cauchy法 3.2.2直接搜索法 3.2.3Newton-Raphson法 3.2.4单纯形法 3.2.5广义最小二乘法 3.2.6Davison法3.3DFP法用于光谱干扰的校正 3.3.1DFP法[87] 3.3.2模拟数据3.4基于非线性最小二乘法的光谱干扰校正 3.4.1约束条件的处理 3.4.2迭代过程 3.4.3模拟数据 3.4.4实测谱图分析3.5讨论第4章 自适应滤波法4.1Widr0w自适应噪声抵消模型4.2自适应滤波参考输入的选取4.3LMS算法[138,96,158~161]4.4LS算法[138,162,163]4.5自适应滤波法用于背景干扰的校正[98,101,103] 4.5.1模拟数据 4.5.2实测谱图分析4.6自适应滤波法用于谱线重叠干扰的校正[99,102,103] 4.6.1自适应谱线抽取模型的提出 4.6.2模拟数据 4.6.3实测谱图分析4.7ICPAES自适应分析法 4.7.1算法公式 4.7.2模拟数据 4.7.3实测谱图分析4.8用多通道系统识别方法分离光谱重叠峰[91,105] 4.8.1多通道系统识别模型 4.8.2识别算法 4.8.3模拟数据 4.9讨论第5章 卡尔曼滤波算法5.1 Van Veen的卡尔曼滤波算法5.2 Van Veen的卡尔曼滤波算法的模型误差5.3 ICP-AES加权增量卡尔曼滤波算法5.4 讨论第6章 给予数字化谱的方法6.1 数字化谱的获取6.2 模式识别用于光谱分类与识别6.3 高维数据的降维处理6.4 因子分析处理数字化谱第7章 光谱干扰的实时校正7.1 微电子技术的发展7.2 ASIC电路的兴起7.3 WSI技术与三维集成技术7.4 表面安装技术7.5 计算机技术的发展7.6 DSP芯片的进步7.7 采用TMS320C20的光谱干扰实时校正系统7.8 采用Transputer的光谱干扰实时校正系统7.9 讨论
常听人说C-18柱是反相柱,我知道反向柱就是载体是非极性的柱,但如何一看色谱柱的型号就能识别呢?比如看到SB-CN,我就不知道如何识别了,大家给指点下啊
使用的仪器为安捷伦 [url=https://insevent.instrument.com.cn/t/Mp]gc[/url]8860[url=https://insevent.instrument.com.cn/t/Mp]气相色谱仪[/url] 填充式色谱柱检测氯化氢含量不稳定 总是出现识别不到峰或者识别时间总是往后延是什么情况 第一张是正常的 后面的逐渐搜索不到[img=,690,517]https://ng1.17img.cn/bbsfiles/images/2021/12/202112121105154898_5653_5429516_3.png[/img][img=,690,517]https://ng1.17img.cn/bbsfiles/images/2021/12/202112121105462687_4830_5429516_3.png[/img][img=,690,517]https://ng1.17img.cn/bbsfiles/images/2021/12/202112121106007923_9019_5429516_3.png[/img][img=,690,517]https://ng1.17img.cn/bbsfiles/images/2021/12/202112121110089915_5731_5429516_3.png[/img]







 我要推广仪器
我要推广仪器
 下载APP
下载APP