蛋白测序和质谱的区别
听说蛋白酶解肽段二级质谱图可以通过de novo方法测序,请问,除了手工解析,用哪些软件可以快速鉴定辅助解析
蛋白质是生物体中含量最高,功能最重要的生物大分子,存在于所有生物细胞,约占细胞干质量的50%以上, 作为生命的物质基础之一,蛋白质在催化生命体内各种反应进行、调节代谢、抵御外来物质入侵及控制遗传信息等方面都起着至关重要的作用,因此蛋白质也是生命科学中极为重要的研究对象。关于蛋白质的分析研究,一直是化学家及生物学家极为关注的问题,其研究的内容主要包括分子量测定,氨基酸鉴定,蛋白质序列分析及立体化学分析等。随着生命科学的发展,仪器分析手段的更新,尤其是质谱分析技术的不断成熟,使这一领域的研究发展迅速。 自约翰.芬恩(JohnB.Fenn)和田中耕一(Koichi.Tanaka)发明了对生物大分子进行确认和结构分析的方法及发明了对生物大分子的质谱分析法以来,随着生命科学及生物技术的迅速发展,生物质谱目前已成为有机质谱中最活跃、最富生命力的前沿研究领域之一[1]。它的发展强有力地推动了人类基因组计划及其后基因组计划的提前完成和有力实施。质谱法已成为研究生物大分子特别是蛋白质研究的主要支撑技术之一,在对蛋白质结构分析的研究中占据了重要地位[2]。 1.质谱分析的特点 质谱分析用于蛋白质等生物活性分子的研究具有如下优点:很高的灵敏度能为亚微克级试样提供信息,能最有效地与色谱联用,适用于复杂体系中痕量物质的鉴定或结构测定,同时具有准确性、易操作性、快速性及很好的普适性。 2.质谱分析的方法 近年来涌现出较成功地用于生物大分子质谱分析的软电离技术主要有下列几种:1)电喷雾电离质谱;2)基质辅助激光解吸电离质谱;3)快原子轰击质谱;4)离子喷雾电离质谱;5)大气压电离质谱。在这些软电离技术中,以前面三种近年来研究得最多,应用得也最广泛[3]。 3.蛋白质的质谱分析 蛋自质是一条或多条肽链以特殊方式组合的生物大分子,复杂结构主要包括以肽链为基础的肽链线型序列[称为一级结构]及由肽链卷曲折叠而形成三维[称为二级,三级或四级]结构。目前质谱主要测定蛋自质一级结构包括分子量、肽链氨基酸排序及多肽或二硫键数目和位置。 3.1蛋白质的质谱分析原理 以往质谱(MS)仅用于小分子挥发物质的分析,由于新的离子化技术的出现,如介质辅助的激光解析/离子化、电喷雾离子化,各种新的质谱技术开始用于生物大分子的分析。其原理是:通过电离源将蛋白质分子转化为[url=https://insevent.instrument.com.cn/t/Mp]气相[/url]离子,然后利用质谱分析仪的电场、磁场将具有特定质量与电荷比值(M/Z值)的蛋白质离子分离开来,经过离子检测器收集分离的离子,确定离子的M/Z值,分析鉴定未知蛋白质。 3.2蛋白质和肽的序列分析 现代研究结果发现越来越多的小肽同蛋白质一样具有生物功能,建立具有特殊、高效的生物功能肽的肽库是现在的研究热点之一。因此需要高效率、高灵敏度的肽和蛋白质序列测定方法支持这些研究的进行。现有的肽和蛋白质测序方法包括N末端序列测定的化学方法Edman法、C末端酶解方法、C末端化学降解法等,这些方法都存在一些缺陷。例如作为肽和蛋白质序列测定标准方法的N末端氨基酸苯异硫氰酸酯(phenylisothiocyanate)PITC分析法(即Edman法,又称PTH法),测序速度较慢(50个氨基酸残基/天);样品用量较大(nmol级或几十pmol级);对样品纯度要求很高;对于修饰氨基酸残基往往会错误识别,而对N末端保护的肽链则无法测序[4]。C末端化学降解测序法则由于无法找到PITC这样理想的化学探针,其发展仍面临着很大的困难。在这种背景下,质谱由于很高的灵敏度、准确性、易操作性、快速性及很好的普适性而倍受科学家的广泛注意。在质谱测序中,灵敏度及准确性随分子量增大有明显降低,所以肽的序列分析比蛋白容易许多,许多研究也都是以肽作为分析对象进行的。近年来随着电喷雾电离质谱(electrospray ionisation,ESI)及基质辅助激光解吸质谱(matrix assisted laser desorption/ionization,MALDI)等质谱软电离技术的发展与完善,极性肽分子的分析成为可能,检测限下降到fmol级别,可测定分子量范围则高达100000Da,目前基质辅助的激光解吸电离飞行时间质谱法(MALDI TOF MS)已成为测定生物大分子尤其是蛋白质、多肽分子量和一级结构的有效工具,也是当今生命科学领域中重大课题——蛋白质组研究所必不可缺的关键技术之一 [5] 。目前在欧洲分子生物实验室(EMBL)及美国、瑞士等国的一些高校已建立了MALDI TOF MS蛋白质一级结构(序列)谱库,能为解析FAST谱图提供极大的帮助,并为确证分析结果提供可靠的依据[6]。
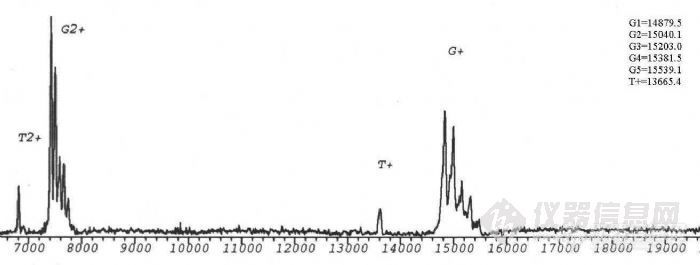
生物质谱在糖蛋白结构分析中的应用项目完成人:桑志红 蔡 耘项目完成单位:国家生物医学分析中心 随着人们对糖蛋白参与生命活动机理的日益深入了解,对天然糖蛋白及重组糖蛋白类药物的分析越来越受到重视。重组糖蛋白类药物的质量控制更是直接关系到药物的疗效及至人类的健康。九十年代以来,随着带有反射功能的基质辅助激光解吸附电离飞行时间质谱(MALDI-TOF-MS)和纳升电喷雾串联质谱(nano-ESI-Q-TOF)等具有软电离方式的现代质谱 技术的发展,质谱以其高灵敏度和强有力的分析混合物的能力,提供了生物大分子的分子量、序列、一级结构信息以及结构转换、修饰等方面的信息,使糖基化分析有了重要的进展。 通常研究糖蛋白的方法是把蛋白链上的寡糖切下来,分别研究蛋白部分和寡糖部分的结构,因此无法研究与两部分共同相关的结构问题,也不能区分不同糖基化位点上切下来的寡糖。自90年代初,国外有人开始用质谱法研究糖蛋白的结构,同时描述了各个位点的不均一性。我们用建立的现代生物质谱技术研究糖蛋白一级结构的方法,将其应用与基因重组糖蛋白的结构分析。为糖蛋白结构分析及基因重组糖蛋白类药物的质量控制提供新的手段。一、 生物质谱研究糖蛋白结构方法的建立实验所用仪器为:1.德国BRUKER 公司的REFLEXIII型基质辅助激光解吸附电离飞行时间质谱仪,N2激光器,波长337nm,线性飞行距离150cm,加速电压2kv。2.英国Micromass 公司Q-TOF型电喷雾串联质谱仪。源温80°C,气体流速40L/h,枪头电压650V,检测频率2.4S,氩气碰撞池压力6*10-5mbar。1. 基质的选择,在MALDI-TOF-MS分析中,基质起着相当重要的作用。不同的基质对不同类的物质响应不同,a-氰基-4-羟基肉桂酸用于测定糖蛋白核糖核酸酶B效果相对较好。2. 糖蛋白分子量的测定,糖蛋白核糖核酸酶B由124个氨基酸组成,在34位Asn处连有一个高甘露糖型N-糖链。由于糖链的微不均一性,与普通蛋白质及核酸不同,其分子离子峰在MALDI-TOF-MS 质谱图上表现为一簇峰,各峰之间约相差一个糖基。正是由于这种微不均一性,使得其分子离子峰变宽,灵敏度降低。糖链分子量越大,峰越宽,灵敏度越低,所以一般只有糖链较短,蛋白的质量不太大的糖蛋白才能测定其平均分子量。用MALDI-TOF可直接测定糖蛋白核糖核酸酶B的平均分子量为 15208.6Da。http://ng1.17img.cn/bbsfiles/images/2011/03/201103211511_284179_1604317_3.jpg3. 糖含量的测定,采用O聚糖酶及内糖苷键酶F分别作用于核糖核酸酶 B,只有内糖苷键酶F能够是其分子量发生变化,表明核糖核酸酶B分子中不存在O-连接糖链存在着N-连接糖链。内糖苷键酶F切断N-糖链五糖核心最内侧的GlcNAc-GlcNAc糖苷键,得到含一个GlcNAc的肽链,减去GlcNAc,可以计算出准确的肽链分子量T=13695.6,与糖蛋白平均分子量之差为糖链的平均分子量G=1513.4,平均糖含量为:(糖链大小/糖蛋白分子量)×100%=9.95%。4. 糖基化位点的确定,研究糖基化类型及糖基化位点的策略:采用蛋白酶酶解与糖苷内切酶酶解相结合的方法,通过酶切前后含糖肽片的位移,结合网上数据库检索,可以确定糖基化类型和糖基化位点。以不同类型的糖苷内切酶作用于糖蛋白(N-糖苷键酶或O-糖苷键酶),在MALDITOF-MS 上观察其质量的变化,可以直接确定糖蛋白中是否含有响应类型的糖链,这是我们确定糖蛋白中糖苷键类型的基础。我们采用先将核糖核酸酶B还原烷基化,加Glu-C酶切,产物再用内糖苷肩酶F酶切,可观察到含糖肽段出现位移,将核糖核酸酶B的肽质量指纹图进行数据库检索,证实发生位移的肽段中含有N-糖链特异连接位点,由此确定34位Asn为糖基化位点。另外我们采用内糖苷键酶F及肽-N-聚糖酶F两种酶进行差位酶切法对含糖肽段进行验证,两种酶酶切后分子离子峰的差值除以GlcNAc的质量,结果就是N-糖基化位点的个数5. 质谱测定氨基酸序列, 我们对核糖核酸酶B肽质量指纹谱中的含糖肽段进行了串联质谱测定,首先在一级质谱图中选择离子4972.23,在串联质谱的碰撞活化室以氩气与其碰撞产生碎片,从碎片的质荷比推算出此肽片中的一段氨基酸序列,检索结果为核糖核酸酶B,从而判断其理论序列是否一致。6. 糖链结构的研究,凝集素对糖肽的亲和提取,进一步分析糖肽序列及糖链结构的关键是含糖肽段的提取。核糖核酸酶B中糖链为高甘露糖型,我们选用对其有特异性吸附的伴刀豆球蛋白对其进行提取利用这种简捷的亲和质谱的方法,对糖肽段进行了分析。建立了亲和质谱分析糖肽类物质的方法,为今后糖肽序列分析及糖链结构分析奠定了基础。二、基因重组糖蛋白人促红细胞生成素(rhEPO)的结构分析。 利用以上建立的方法,我们对样品重组人促红细胞生成素进行了分析,断定此样品为非完全糖基化,样品中只存在N-连接的糖链,无O-糖链。应用酶切法用肽-N-聚糖酶处理后,得到两个含糖肽段,进行数据库检索,测得38位及83位为N-糖基化位点,与文献报道相符,结果可靠。因此,该项课
[摘要] 质谱对于现代蛋白质化学研究是一项重要的技术。也可用于蛋白组分析,在同一时间监控上千种蛋白的表达情况。首先蛋白质混合物可以用双向凝胶电泳分开,再用质谱及随后的蛋白质数据库检索对单个蛋白进行鉴定和分析。最近几年,质谱领域取得了令人鼓舞的进展,使得全自动、高通量的蛋白检测成为可能。质谱也可以用来分析蛋白的转录后调节以及研究蛋白质复合体。本文将介绍目前蛋白组研究中质谱方法的应用并对其优缺点进行讨论。关键词: 质谱;二维电泳(2-DE);蛋白组分析MALDI-TOF1 前 言蛋白组学是研究生物特定组织或细胞内表达的所有蛋白质成分,蛋白质组的一门学科。蛋白组分析一般是用双向凝胶电泳(2-DE),质谱(MS)以及数据检索来完成。2-DE要回顾到20世纪70年代初[1],但是用质谱技术对蛋白质进行鉴定和分析是在近十年内才成为可能。其中最重要的一个原因是新的软离子技术即基质辅助激光解析电离(MALDI)[2]和电喷雾电离(ESI)[3,4]技术的发展和应用,以及样本制备技术和质谱仪的发展等。从数据库中获得成指数上升的序列信息也促进了质谱技术的发展。跟转录组学中的全自动DNA微阵列技术相比,蛋白组分析需要更多的手工操作,尤其在2-DE上会出现很多问题[5,6]。尽管存在很多困难,蛋白组学的重要性还是公认的。DNA微阵列技术是建立在对mRNA稳定水平的检测上,然而蛋白组学研究的对象是细胞中最活跃的因子——蛋白质。最近有研究证明,mRNA的表达和蛋白的水平并非具有相关性[7,8]。蛋白质有转录后修饰过程,并会以不同的形式出现。而这些修饰过程是相应的DNA测序技术所不能预测的。质谱技术在蛋白质修饰分析过程中具有重要的作用。2 质谱对蛋白质的检测质谱仪是由离子源,质量分析,离子检测器,以及数据检索等单元组成。首先,被分析的分子在离子源中被离子化,然后在质量分析器里根据不同的质荷比分开,再对分开的离子进行检测。随着MALDI和EIS的出现,质谱技术已经广泛用来分析蛋白质。质量分析器有很多种,最常用的方法是将飞行时间检测器(TOF)与MALDI或三级四级串联质谱仪联用,或者将四级杆-TOF,离子阱等连接到ESI上。蛋白组分析中,可以用两种不同的方法检测电泳分离后的单个蛋白质。最简单的方法叫做肽指纹谱测定(PMF)[9~13]。这个方法是用特殊的酶对2-DE分离后的蛋白质点进行降解,产生的肽从凝胶中分离出来后再用质谱分析和检测肽的分子量。数据库检测能够产生所有蛋白质理论上的PMF,把它们和质谱分析所获得的肽片进行比较就可以得出结果。第二种方法是在质谱仪中把凝胶分离后的肽分解成片段,产生局部的氨基酸序列(序列标签)。那么就可以用分子量或者序列信息进行数据库检索[14,15]。PMF一般用MALDI-TOF来实现,序列标签可以用串联质谱技术MS-MS进行检测[16~18]。用质谱检测蛋白的灵敏性可以精确到飞摩的水平,甚至已有报道其精确度可以达到阿摩水平[19]。3 用MALDI-TOF进行肽指纹谱分析凝胶分离后的蛋白质鉴定以及肽指纹谱分析是目前质谱实验室常规使用的方法。在进行MALDI分析之前需要最优化的凝胶上消化[20~22]和脱盐过程。胰岛素是最常用的凝胶消化酶,因为它在赖氨酸和精氨酸位点能够特异性切割蛋白质,产生分子量在600~2500Da之间的小分子肽,并能够从凝胶上有效的分离出来。MALDI-TOF是质谱技术中相对简单并很容易使用的一种方式,对样本中的盐和其他污染物有很高的耐受性,这点优于ESI。提取的肽片混合物中较小的片段可以直接沉积在靶板上做PMF分析,剩下的样本可以储存起来作为以后的ESI-MS分析。如果经凝胶分离后所有的肽全用来做MALDI分析,那么样本经脱盐以后将会取得更好的结果。脱盐的过程可以用商品化的试剂盒ZipTip(Millipore),或者在凝胶电泳仪的末端放置一个小的逆向塑料柱来实现[23,24]。PMF中非常重要的一个因素就是质谱测量分子量的准确度[25]。现代的MALDI-TOF仪都具有延迟取样反射器装置,用它们检测的肽段分子量可以精确到10~30ppm。这样的精确度使得4~5个肽段足以清楚的鉴定蛋白质的分子量。MALDI产生的大多数都是单电荷离子,所以它的图谱很容易解释。4 肽质指纹谱分析的自动化为了实现高通量蛋白检测,样本准备,质谱检测,资料分析和数据检索必须实现自动化操作。目前有些实验室用机器人对蛋白质进行自动化取点,凝胶上消化,样本脱盐以及对MALDI平板进行定点测定等。而且,现代化的MALDI-TOF仪完全能够让MALDI检测自动化。资料分析和数据检索过程同样可以自动化。在进行蛋白组分析时,如果在凝胶上不用单个分离就可以对所有蛋白质进行鉴定将是非常具有诱惑力的。为此,研究人员做了很多努力,由Hochestrasser及其同事建立了一套称作分子探测术的方法(molecular scanner)[26,27]。它是将整个2-DE胶上蛋白质样本同时酶解,并将酶解片段一起原位转移至另一张膜上,再直接用MALDI- TOF 质谱对膜上样本进行整体扫描,为实现蛋白质组学研究的自动化、规模化以及临床应用提供了一个崭新的思路和方法。这种思路的优点是显而易见的,不过按照目前的方法,要普及此种技术主要的难点是,质谱扫描一张图谱所需的时间过长,如用0.4mm的精度扫描一张4cm×4cm的膜需55个小时,这就意味着一张16cm×16cm的常用膜的扫描,至少需要36天不间断的工作和大约40G的磁盘空间存储如此庞大的原始数据。5 用ESI-MS/MS的方法创建序列标签只有当被消化的蛋白存在于已有的蛋白或基因组数据库中,并且能从MALDI分析器中得到四五个肽片的数据才能成功进行。如果在EST数据库中只有目的蛋白的部分序列,那么就需要知道肽片的序列信息。创建序列标签的优势在于,用肽的分子量和序列作为数据库检索对象比只用分子量作为检索对象具有更高的特异性。有了序列标签信息后,也可以用EST数据库进行检索[28]。通常来自于一个肽上的序列标签就足以鉴定蛋白质。同MALDI相比,纳升-ESI-MS/MS费时费力,而且在做ESI分析之前必须对样本进行脱盐处理。这些问题可以通过ESI-MS与HPLC联用得到解决。做ESI分析对样本浓度很敏感,用现代化的纳升-HPLC方法可以提供很高的局部肽片凝聚物,分离后的样本可以直接用于质谱分析,而不需要再分解。当分析混合物的时候,在质谱之前做LC分离尤其重要,因为它使得数据依赖的实验(DDE)成为可能,在DDE中,所有的离子都进入检测器进行测量,如果从HPLC到质谱之间出现一个峰的话,软件将自动从质谱转换到MS/MS模式并对产生的离子进行扫描。跟纳升-ESI相比,用这个方法可以从一份标本产生更多的MS/MS数据。Yates等已经详细叙述了如何进行[url=https://insevent.instrument.com.cn/t/Yp][color=#3333ff]LC-MS[/color][/url]/MS全自动蛋白检测的策略[29]。
现有基因重组表达的糖蛋白想进行以下几项委托检测, C端氨基酸测序、氨基酸组分分析、肽图、质谱分子量、糖基化分析如果有意者请联系,将样品要求、检测费用以及合作流程发到邮箱,如有疑问可以加qq联系。 qq:278569901 邮箱:wbz5102@gmail.com
Edman降解法是测定蛋白质序列的经典方法,该方法由瑞士生物化学家佩尔维克托于1950年创立。Edman降解法通常是以周期的形式来表征。对于一个完整的周期,异硫氰酸苯酯标记上指定肽段的N末端,环化,之后被标记的氨基酸在酸性条件下从肽链中游离出来,进一步酸化后形成一个更加稳定的乙内酰苯硫脲-氨基酸(PTH-AA)衍生物。PTH-AA衍生物可以通过高效液相色谱鉴定。埃德曼降解周期就是通过反复地将多肽的氨基酸依次降解下来,从而鉴定氨基酸序列。 1982年,美国应用生物系统(ABI)公司了将第一台商用自动多肽测序仪推向市场,并被实践证明是可靠和耐用的。实际上,在过去几十年中,自动多肽测序仪只有屈指可数的一些改进,但此类自动肽测序仪仍是测定肽序列的黄金标准。然而,串联质谱的使用已经成为日益重要的肽序列测定工具。质谱,特别是串联飞行时间(TOF-TOF 和QTOF)质谱仪可以对少量样本进行更快速的分析。 与质谱相比,自动Edman降解测序的明显优势在于:已被化学验证的精确性、系统初始投资较小 然而,它的缺点是:分析时间较长、测得序列数有限,典型的测量长度范围是20~50个氨基酸序列。而对于低丰度的肽、无法获得N末端的肽,或者需要更短的分析时间,质谱则是理想的工具。但是,质谱价格高且无法区分同分异构的氨基酸。 虽然美国应用生物系统(ABI)公司主导了自动多肽测序仪的市场,但由于市场疲软,ABI于2008年6月停止生产自动多肽测序仪。然而岛津公司看准了机会,在2009年匹兹堡会议上将其PPSQ自动多肽测序仪推向北美市场,PPSQ已在日本广泛应用超过20年。另一方面,对用质谱测定蛋白质序列的方法改进的需求保持旺盛,布鲁克道尔顿公司最近推出了Edmass Micro MALDI-TOF和 Edmass Ultra TOF-TOF 系统,这是专门为没有质谱使用经验的多肽化学家们设计的。 自动多肽测序仪的市场主要来自于科研机构,但过去几年中自动多肽测序仪的市场需求增长处于某种停滞状态,尤其是质谱变得容易获得。但是,随着肽自动测序仪在连续使用过程中的老化,Edamn化学家们正在准备购买新设备。售后服务、附件、耗材及试剂有望在短期内对自动多肽测序仪市场产生推动作用。
求购 质谱分析的蛋白标准品,MALDI-TOF-MS上用的。 分子量在400--30000da 的或者接近这个质量范围的,如有请联系我。直接给我这个留言就可以,谢谢!
大家好,氨基酸分析仪与蛋白质测序仪有主要区别在什么地方呢?目前实验室需要进行氨基酸的测序分析,究竟买一台蛋白质测序仪好呢,还是氨基酸分析仪好呢?价格大概有多少呢?这些仪器有没有国产的呢 QQ:2392795357
褚福亮,王福生, 中国人民解放军第302医院全军艾滋病与病毒性肝炎重点实验室 北京市 100039项目负责人 王福生, 100039 ,北京市丰台路26号, 中国人民解放军第302医院全军艾滋病与病毒性肝炎重点实验室. fswang@public.bta.net.cn电话:010-66933332 传真:010-63831870收稿日期 2002-08-15 接受日期 2002-09-03摘要新近广泛应用蛋白质芯片(ProteinChipâ Array)系统成功鉴定出了一些重要疾病(如肿瘤和危害性较大的传染病)新的、特异性的生物标记(biomarkers),后者不仅在生物医学的基础方面具有重要的科学价值,而且在临床疾病的诊断、治疗和预防发挥重要的指导作用,显示了良好的发展前景.本文就表面增强的激光解析电离-飞行时间-质谱(SELDI-TOF-MS)相关的原理、特点、在临床和基础研究中的应用新进展和未来的发展趋势做一综述.此外,我们就蛋白质谱分析技术在病毒性肝炎、肝硬化和肝癌等一系列肝病方面的应用策略和前景进行了分析.褚福亮,王福生. 蛋白质谱分析方法特点及其在蛋白组学研究领域中的应用.世界华人消化杂志 2002 10(12):1431-14350 引言人类基因组计划已经进入后基因组时代-即功能基因组时代[1],作为基因功能的直接体现者-蛋白质,及其之间的相互作用越来越引起基础和临床科学家们的关注[2-6] .因为要彻底了解生命的本质,只把基因测出来还是不够的,还必须要了解其在生物生长、发育、衰老和整个生命过程中的功能、不同蛋白质之间的相互作用以及他们与疾病发生、发展和转化的规律[7-14] .正因为如此,有关上述问题的蛋白质组学研究成了今天生命科学最重要的焦点之一[15] .为了阐明蛋白质在上述生命现象中的作用和相关机制,人们设计了许多新的方法技术,如:二维电泳、质谱分析、微距阵列、酵母双杂交和噬菌体展示等,这些方法在一些特定的情况下,虽然显示出了他们各自不同的优点,但是同样也存在着较大的局限性,难以开展大规模、超微量、高通量、全自动筛选蛋白质等方面的分析,因而设计更全面、同时研究多种蛋白质相互作用的技术,在功能基因组和蛋白组学的研究中建立一个更有效的技术平台,成为本领域中优先关注的问题[16] .近来,美国Ciphergen(赛弗吉)公司研制的ProteinChipâ Array的仪器,并建立了一种新的蛋白质飞行质谱-表面增强的激光解析离子化-飞行时间-质谱(surface-enhanced laser desorption/inionation-time of flight-mass spectra, SELDI-TOF-MS),已取得可喜的进展,筛选出了许多与疾病相关的新型生物标志,不仅为临床疾病的诊断和治疗等提供了新的选择,而且在基础科学、新药研制和疾病预防等方面具有广泛的应用前景[16-18] .本文就SELDI-TOF-MS相关的原理、特点、在临床和基础研究中的应用新进展和未来的发展趋势做一综述.1 ProteinChipâ Array系统和SELDI-TOF-MS的特点1.1 蛋白质芯片系统的组成和原理 蛋白质芯片系统由三部分组成:蛋白质芯片、芯片阅读器和芯片软件.供研究用芯片上有6-10芯池,不同的芯片表面上的化学物质不同,芯片表面分为两大类:一类为化学类表面,包括经典的色谱分析表面,如:结合普通蛋白质的正相表面,用于反相捕获的疏水表面,阴阳离子交换表面和捕获金属结合蛋白的静态金属亲合捕获表面;另一类称为生物类,特定的蛋白质共价结合于预先活化的表面阵列,可以用来研究传统的抗体一抗原反应,DNA和蛋白质作用,受体、配体作用和其他的一些分子之间的相互作用[19] . 根据检测目的不同,可以选用不同的芯片,或者自己设计芯片.将样本和对照点到芯池上以后,经过一段时间的结合反应,用缓冲液或水洗去一些不结合的非特异分子,再加上能量吸收分子(energy absorbing molelule,EAM)溶液,使样本固定在芯片表面.当溶液干燥后,一个含有分析物和大量能量吸收分子“晶体”就形成了.能量吸收分子对于电离来说非常重要.经过以上步骤,就可经把芯片放到芯片阅读器中进行质谱分析. 在阅读器的固定激光束下,芯片上、下移动,使样本上每一个特定点都被“读”到.激光束的每一次闪光释放的能量都聚集在该区一个非常小的点上(focused laser beam,聚焦激光束).这样,每个区都含有丰富的,可寻址(addressable)的位置.蛋白质芯片处理软件精确控制激光寻读过程.当样本受到激发,就开始电离和解除吸附.不同质量的带电离子在电场中飞行的时间长短不同,计算检测到的不同时间,就可以得出质量电荷比,把他输入电脑,形成图像[19].Ball et al [20]采用一种称为人工神经网络(artifical neural network,ANN)的算法处理出现的成千上万的峰,鉴定出三个分子量为13 454、13 457和14 278的生物标记分子,使疾病预测率达到97.1 %.1.2 ProteinChipâ Array芯片和SELDI-TOF-MS的特点 新型蛋白芯片与以往的蛋白芯片不同之处:SELDI-TOF-MS,他是在MALDI(matrix-assisted laser desorption/inionation)[21,22]基础上,改进后实行表面增强的飞行质谱.SELDI-TOF-MS优于MALDI-TOF表现为他不会破坏蛋白质,或使样本与可溶的基质共结晶来产生质谱信号.对SELDI-TOF来说,可以直接将血清、尿液、组织抽取物等不需处理直接点样检测[40] 由于一部分非特异结合的分析物被洗去,因而出现的质峰非常一致,有利于后期分析[23,24] . 与二维电泳相比:二维电泳分析蛋白质的分子量在30 KDa以上时电泳图谱较清楚,对在组织抽提物中占很大比例的低丰度的蛋白质不能被检出;其次,二维电泳胶上的蛋白质斑点很大一部分包含一种以上的蛋白质;而且,二维电泳耗时长,工作量大,对象染色转移等技术要求高,不能完全实现自动化.而SELDI-TOF在200 Da-500 KDa区间都可以给出很好的质谱,对一个样本的分析在几十分钟内就可以完成[19],处理的信息量远远大于二维电泳;对于低丰度物质,即使浓度仅attomole(10-18)的分子,只要与表面探针结合,就可以检测到,这也是二维电泳所不具备的[24,25] . 对于微距阵蛋白芯片来说,需要一种不破坏折叠的蛋白质构象的固定技术,再与另外的蛋白质反应,经检测莹光来观察蛋白质之间的作用[26] .而基于SELDI-TOF-MS的ProteinChip分析蛋白质不需溶解、不需染色、廉价、针对性强. 因而蛋白质芯片仪具有以下优势:(1)可直接使用粗样本,如:血清、尿液、细胞抽提物等[27] .(2)使大规模、超微量、高通量、全自动筛选蛋白质成为可能;(3)他不仅可发现一种蛋白质或生物标记分子,而且还可以发现不同的多种方式的组合蛋白质谱,可能与某种疾病有关[28] (4)推动基因组学发展,验证基因组学方面的变化,基于蛋白质特点发现新的基因.可以推测疾病状态下,基因启动何以与正常状态下不同,受到那些因素的影响,从而跟踪基因的变化[2,14,15] . 其存在的问题:对于不同的样本,根据检测的目标采取或者设计几种芯片,理论上可以把所有的相同性质蛋白质捕获,但是实际上仍有少量的分子没与表面探针结合.使用SELDI-TOF-MS,仅能给出蛋白质的分子量,不能给出C端、N端的序列,也没法知道蛋白质的构型,因此需要将蛋白质充分纯化后,用蛋白酶消化芯片上的蛋白质,分析肽段,再用生物信息学方法鉴定蛋白质序列[18,24] .另外,在国内,该芯片费用较高,分析质谱需要大量后续工作支持.
测序都是从5'端进行的,正向和反向测序是指对DNA的两条互补链分别测序,通常两个方向测序结果经校读后完全一致才能认为得到可靠结果。生工测序结果一般都提供两个文档,一个是TEXT的序列文档,一个是用Chromas软件打开的ABI文档。1.寻找引物http://blast.ncbi.nlm.nih.gov/Blast.cgi 比对,去除引物序列,找到目的片段。在DNAMan上进行比对,看引物能不能比对上(一个不变,一个反向互补),如果比不上,那可能就不是你要的序列,如果能比上,上游以引物第一个为分界线,去除前面的;下有一最后一个为分界线,去除后面的,剩下的就是目的序列。然后在NCBI上Blast.就OK了。批注:PCR产物进行测序的结果可能不包含引物序列2.将找到的对应目的片段转成*.txt格式3.下载BioEdit软件第一:打开Bioedit软件,导入拼接好的样品序列与标准亚型参考序列File—New Alignment—Sequence—New Sequence—导入拼接好的样品序列和标准参考序列(从TEXT文档利用复制粘贴工具)—Apply and close —保存结果—关闭窗口第二:点击菜单栏上按钮“Accessory Application”,选择“Clustalw Multiple Alignment”File—Open—Accessory Application—Clustalw Multiple Alignment第三:比对结束后,删除比对序列两端的多余序列,使所有序列等长选择需要编辑的序列—Sequence—Edit Sequence—进行序列的编辑—保存修改后结果第四:选择“Sequence”菜单下的“Gaps”,点击“Lock Gaps”第五:将比对后的序列保存为Fasta 格式文档4.下载MAGE4.0软件1) 打开MEGA软件,选择“File”菜单栏中的“Convert To MEGA Format”,把序列文件的格式转换为meg文档保存;2) 双击序列的meg文档,选择“Nucleotide Sequences”,点击“OK”;3) 程序运行中询问是否为蛋白编码序列,选择“NO”;4) 在MEGA操作界面选择“Phylogeny”菜单栏下“Bootstrap Test of Phylogeny”中的“Neibour-Joining”;5) 选择“Test of Phylogeny”栏中的“Bootsrap”,“Replications”设定为1 000;在“Options Summary”栏中的“Model”项中,设定参数为“Kimura 2-Paramete”r,最后选择“Compute”;6) 将分析结果采用Los Alamos HIV序列库提供的HIV-BLAST和Subtyping工具进行验证。
PS1利用基质辅助激光解吸电离-飞行时间(MALDI-TOF)技术来表征生物分子。样品溶于固定的底物中形成晶体,用激光脉冲使其离子化,离子被加速后通过飞行管时分离,所有离子均可被检测。系统包括三个组成部件:样品点样制备工作站(SymBiot 1)、生物质谱工作站(Voyager-DE PRO)和自动化分析软件(AutoMS-Fit)。SymBiot1 是一个自动样品处理系统,支持亚微升级微量点样,具有快速省时、重现性好的特点;Voyager-DE PRO是为蛋白质组研究专门设计的自动飞行时间质谱分析系统,配有AB公司之专利—延迟检测技术,具有高分辨率、质荷比宽等特点;AutoMS软件可以批处理方式或实时动态方式检索Protein Prospector蛋白数据库或您指定的蛋白数据库,查询参数可以任意设定,检索结果以Microsoft Access格式分类编号及储存。 PS 1技术平台建立伊始便受到了许多蛋白质课题研究组的关注。中国科学院上海生物化学研究所戚正武院士课题组从猪肝中提取某一活性蛋白组分,该组分理化性质不清楚,天然含量十分低,并无相关文献报道。用HPLC分离以后对活性组分的成分不能确定。上海基康生物技术有限公司运用PS 1系统对HPLC分离后的活性组分作了质谱分析,仅在一个工作日内就精确确定该组分由分子量极为相近的几种蛋白质构成,分子量精确度达到10 ppm。后经HPLC再次细分(洗脱梯度增加了2.5倍),证实了质谱的结论。此活性组分曾滤过1kD分子筛,基康的质谱数据纠正了研究人员过去对该活性组分分子量的误判,为研究人员明确实验方向、优化实验步骤提供了强有力的依据。 PS1除了可以进行生物大分子的精确分子量测定,还可用于蛋白的肽指纹图谱分析(peptide mass fingerprint,PMF),提供相关生物信息学服务,并且还可以利用源后衰变(Post Source Decay,PSD)技术来获得样品的MS/MS数据,以得到一级结构信息。PSD方法通常增加了激发激光的功率,使其超过产生一般肽指纹谱图所需功率的阈值,过剩的能量使前体离子在源内离子化之后发生裂解,产生一系列碎片离子,在反射器的作用下,最终可以得到一张连续的碎片离子图谱。经特定的软件分析后,即可在数据库中检索到肽段的氨基酸序列。利用PSD分析技术,还可以对磷酸化,糖基化等翻译后修饰进行定位分析,同样也可以鉴定产生翻译后修饰肽段的蛋白质。Neville et al.(1997)将这一方法成功的用于磷酸肽的序列分析。作为重要的蛋白质鉴定手段之一,PS1的精确度可以达到10 ppm,灵敏度为fmol,分子量检测范围可达到500 kDa,每天可自动分析40-100个样品,适用于大规模“蛋白质组学”研究。
蛋白质结构分析:制备、鉴定与微量测序
几种常用的蛋白鉴定方法传统的蛋白鉴定方法,如免疫印迹法、内肽的化学测序、已知或未知蛋白的comigration分析,或者在一个有机体中有意义的基因的过表达通常耗时、耗力,不适合高流通量的筛选。 目前,所选用的技术包括对于蛋白鉴定的图象分析、微量测序、进一步对肽片段进行鉴定的氨基酸组分分析和与质谱相关的技术。1 图象分析技术(Image analysis)“满天星”式的2-DE图谱分析不能依靠本能的直觉,每一个图象上斑点的上调、下调及出现、消失,都可能在生理和病理状态下产生,必须依靠计算机为基础的数据处理,进行定量分析。 在一系列高质量的2-DE凝胶产生(低背景染色,高度的重复性)的前提下,图象分析包括斑点检测、背景消减、斑点配比和数据库构建。 首先,采集图象通常所用的系统是电荷耦合CCD(charge coupled device)照相机;激光密度仪(laser densitometers)和Phospho或Fluoroimagers,对图象进行数字化。 并成为以象素(pixels)为基础的空间和网格。 其次,在图象灰度水平上过滤和变形,进行图象加工,以进行斑点检测。 利用Laplacian,Gaussian,DOG(difference of Gaussians) opreator使有意义的区域与背景分离,精确限定斑点的强度、面积、周长和方向。图象分析检测的斑点须与肉眼观测的斑点一致。 在这一原则下,多数系统以控制斑点的重心或最高峰来分析,边缘检测的软件可精确描述斑点外观,并进行边缘检测和邻近分析,以增加精确度。 通过阈值分析、边缘检测、销蚀和扩大斑点检测的基本工具还可恢复共迁移的斑点边界。 以PC机为基础的软件Phoretix-2D正挑战古老的Unix为基础的2-D分析软件包。 第三,一旦2-DE图象上的斑点被检测,许多图象需要分析比较、增加、消减或均值化。 由于在2-DE中出现100%的重复性是很困难的,由此凝胶间的蛋白质的配比对于图象分析系统是一个挑战。 IPG技术的出现已使斑点配比变得容易。 因此,较大程度的相似性可通过斑点配比向量算法在长度和平行度观测。 用来配比的著名软件系统包括Quest,Lips,Hermes,Gemini等,计算机方法如相似性、聚类分析、等级分类和主要因素分析已被采用,而神经网络、子波变换和实用分析在未来可被采用。 配比通常由一个人操作,其手工设定大约50个突出的斑点作为“路标”,进行交叉配比。 之后,扩展至整个胶。例如:精确的PI和MW(分子量)的估计通过参考图上20个或更多的已知蛋白所组成的标准曲线来计算未知蛋白的PI和MW。 在凝胶图象分析系统依据已知蛋白质的pI值产生PI网络,使得凝胶上其它蛋白的PI按此分配。 所估计的精确度大大依赖于所建网格的结构及标本的类型。 已知的未被修饰的大蛋白应该作为标志,变性的修饰的蛋白的PI估计约在±0。25个单位。 同理,已知蛋白的理论分子量可以从数据库中计算,利用产生的表观分子量的网格来估计蛋白的分子量。 未被修饰的小蛋白的错误率大约30%,而翻译后蛋白的出入更大。 故需联合其他的技术完成鉴定。2 微量测序(microsequencing)蛋白质的微量测序已成为蛋白质分析和鉴定的基石,可以提供足够的信息。 尽管氨基酸组分分析和肽质指纹谱(PMF)可鉴定由2-DE分离的蛋白,但最普通的N-末端Edman降解仍然是进行鉴定的主要技术。 目前已实现蛋白质微量测序的自动化。 首先使经凝胶分离的蛋白质直接印迹在PVDF膜或玻璃纤维膜上,染色、切割,然后直接置于测序仪中,可用于subpicomole水平的蛋白质的鉴定。 但有几点需注意:Edman降解很缓慢,序列以每40 min 1个氨基酸的速率产生;与质谱相比,Edman降解消耗大;试剂昂贵,每个氨基酸花费3~4$。 这都说明泛化的Edman降解蛋白质不适合分析成百上千的蛋白质。 然而,如果在一个凝胶上仅有几个有意义的蛋白质,或者如果其他技术无法测定而克隆其基因是必需的,则需要进行泛化的Edman降解测序。近来,应用自动化的Edman降解可产生短的N-末端序列标签,这是将质谱的序列标签概念用于Edman降解,业已成为一种强有力的蛋白质鉴定。 当对Edman的硬件进行简单改进,以迅速产生N-末端序列标签达10~20个/d,序列检签将适于在较小的蛋白质组中进行鉴定。若联合其他的蛋白质属性,如氨基酸组分分析、肽质质量、表现蛋白质分子量、等电点,可以更加可信地鉴定蛋白质。 选择BLAST程序,可与数据库相配比。 目前,采用一种Tagldent的检索程序,还可以进行种间比较鉴定,又提高了其在蛋白质组研究中的作用。3 与质谱(mass spectrometry)相关的技术质谱已成为连接蛋白质与基因的重要技术,开启了大规模自动化的蛋白质鉴定之门。 用来分析蛋白质或多肽的质谱有两个主要的部分,1)样品入机的离子源,2)测量被介入离子的分子量的装置。 首先是基质辅助激光解吸附电离飞行时间质谱(MALDI-TOF)为一脉冲式的离子化技术。 它从固相标本中产生离子,并在飞行管中测其分子量。 其次是电喷雾质谱(ESI-MS),是一连续离子化的方法,从液相中产生离子,联合四极质谱或在飞行时间检测器中测其分子量。 近年来,质谱的装置和技术有了长足的进展。在MALDI-TOF中,最重要的进步是离子反射器(ion reflectron)和延迟提取(delayed ion extraction),可达相当精确的分子量。 在ESI-MS中,纳米级电雾源(nano-electrospray source)的出现使得微升级的样品在30~40 min内分析成为可能。将反相液相色谱和串联质谱(tandem MS)联用,可在数十个picomole的水平检测;若利用毛细管色谱与串联质谱联用,则可在低picomole到高femtomole水平检测;当利用毛细管电泳与串联质谱连用时,可在小于femtomole的水平检测。 甚至可在attomole水平进行。 目前多为酶解、液相色谱分离、串联质谱及计算机算法的联合应用鉴定蛋白质。 下面以肽质指纹术和肽片段的测序来说明怎样通过质谱来鉴定蛋白质。(1)肽质指纹术(peptide mass fingerprint, PMF)由Henzel等人于1993年提出。 用酶(最常用的是胰酶)对由2-DE分离的蛋白在胶上或在膜上于精氨酸或赖氨酸的C-末端处进行断裂,断裂所产生的精确的分子量通过质谱来测量(MALDI-TOF-MS,或为ESI-MS),这一技术能够完成的肽质量可精确到0。1个分子量单位。 所有的肽质量最后与数据库中理论肽质量相配比(理论肽是由实验所用的酶来“断裂”蛋白所产生的)。 配比的结果是按照数据库中肽片段与未知蛋白共有的肽片段数目作一排行榜,“冠军”肽片段可能代表一个未知蛋白。若冠亚军之间的肽片段存在较大差异,且这个蛋白可与实验所示的肽片段覆盖良好,则说明正确鉴定的可能性较大。(2)肽片段(peptide fragment)的部分测序肽质指纹术对其自身而言,不能揭示所衍生的肽片段或蛋白质。 为进一步鉴定蛋白质,出现了一系列的质谱方法用来描述肽片段。 用酶或化学方法从N-或C-末端按顺序除去氨基酸,形成梯形肽片段(ladder peptide)。 首先以一种可控制的化学模式从N-末端降解,可产生大小不同的一系列的梯形肽片段,所得一定数目的肽质量由MALDI-TOF-MS测量。 另一种方法涉及羧基肽酶的应用,从C-末端除去不同数目的氨基酸形成肽片段。 化学法和酶法可产生相对较长的序列,其分子量精确至以区别赖氨酸(128。09)和谷氨酰胺(128。06)。 或者,在质谱仪内应用源后衰变(post-source decay, PSD)和碰撞诱导解离(collision-induced dissociation, CID),目的是产生包含有仅异于一个氨基酸残基质量的一系列肽峰的质谱。 因此,允许推断肽片段序列。 肽片段PSD的分析在MALDI反应器上能产生部分序列信息。 首先进行肽质指纹鉴定。 之后,一个有意义的肽片段在质谱仪被选作“母离子”,在飞行至离子反应器的过程中降解为“子离子”。 在反应器中,用逐渐降低的电压可测量至检测器的不同大小的片段。 但经常产生不完全的片段。 现在用肽片段来测序的方法始于70年代末的CID,可以一个三联四极质谱ESI-MS或MALDI-TOF-MS联合碰撞器内来完成。 在ESI-MS中,由电雾源产生的肽离子在质谱仪的第一个四极质谱中测量,有意义的肽片段被送至第二个四极质谱中,惰性气体轰击使其成为碎片,所得产物在第三个四极质谱中测量。 与MALDI-PSD相比,CID稳定、强健、普遍,肽离子片段基本沿着酰胺键的主架被轰击产生梯形序列。 连续的片段间差异决定此序列在那一点的氨基酸的质量。 由此,序列可被推测。 由CID图谱还可获得的几个序列的残基,叫做“肽序列标签”。 这样,联合肽片段母离子的分子量和肽片段距N- C端的距离将足以鉴定一个蛋白质。4 氨基酸组分分析1977年首次作为鉴定蛋白质的一种工具,是一种独特的“脚印”技术。 利用蛋白质异质性的氨基酸组分特征,成为一种独立于序列的属性,不同于肽质量或序列标签。 Latter首次表明氨基酸组分的数据能用于从2-DE凝胶上鉴定蛋白质。 通过放射标记的氨基酸来测定蛋白质的组分,或者将蛋白质印迹到PVDF膜上,在15
http://img.dxycdn.com/trademd/upload/asset/meeting/2013/09/06/A1378379551.jpg 氨基酸是蛋白质的基础组成单位,通过研究蛋白质中氨基酸的性质和组成来预测蛋白质的结构和功能,蛋白质氨基酸残基组成分析主要是通过氨基酸分析仪来完成的,本文推荐了2个基于氨基酸组成进行蛋白质预测软件。基于氨基酸组成的蛋白质预测软件根据组成蛋白质的20种氨基酸的物理和化学性质可以辨析电泳等实验中的未知蛋白质,也可以分析已知蛋白质的物化性质。ExPASy工具包包涵的程序:AACompIdent:与把氨基酸序列在SWISS-PROT库中搜索不同,AACompIdent工具利用未知蛋白的氨基酸组成去确认具有相同组成的已知蛋白。该程序分析时需提交的相关信息包括:蛋白质的氨基酸组成、等电点pI和分子量(如果知道)、正确的物种分类及特别的关键词。此外,用户还需在六种氨基酸“组合”中作出选择,这影响到分析如何进行。例如,某种“组合”会把残基Asp/Asn(D/N)和Gln/Glu(Q/E)组合成 Asx(B)和Glx(Z);或者某种残基会在分析中被完全除去。对数据库中的每一个蛋白序列,算法会对其氨基酸组成与所查询的氨基酸组成的差异打分。由电子邮件返回的结果被组织成三级列表:第一张列表中的蛋白都基于特定的物种分类而不考虑pI和分子量;第二张列表包含了不考虑物种分类、pI和分子量的全体蛋白;第三张列表中的蛋白不但基于特定物种分类,并且将 pI和分子量也考虑在内。虽然计算所得结果各不相同,但零分表明了该序列与提出的组成完全相符。AACompSim:AACompIdent的一个变种,AACompSim提供类似的分析,但与前者以实验所得的氨基酸组成为依据进行搜索不同,后者使用SWISS-PROT中的序列为依据。有报道称,氨基酸组成在物种之间是十分保守的(Cordwell等,1995),并且通过分析氨基酸的组成,研究者能从低于25%序列相似性的蛋白之间发现弱相似性(Hobohm和Sander,1995)。因此,在“传统的”数据库搜索基础上辅以组成分析,能为蛋白质之间关系提供更多见解。PROSEARCH:PROPSEARCH也提供基于氨基酸组成的蛋白质辨识功能。用144种不同的物化性质来分析蛋白质,包括分子量、巨大残基的含量、平均疏水性、平均电荷等,把查询序列的这些属性构成的“查询向量”与SWISS-PROT和PIR中预先计算好的各个已知蛋白质的属性向量进行比较。这个工具能有效的发现同一蛋白质家族的成员。可以通过Web使用这个工具,用户只需输入查询序列本身。分子量搜索(MOWSE)分子量搜索(MolecularWeightSearch,MOWSE)算法利用了通过质谱(MS)技术获得的信息。利用完整蛋白质的分子量及其被特定蛋白酶消化后产物的分子量,一种未知蛋白质能被准确无误地确认,给出由若干实验才能决定的结果。由于未知蛋白无需再全部或部分测序,这一方法显著地减少了实验时间。MOWSE的输入是一个纯文本文件,包含一张实验测定的肽段列表,分子量范围在0.7到4.0Kda之间。计算过程基于在OWL非冗余蛋白质序列库中包含的信息。打分基于在一定分子量范围内蛋白中一个片段分子量出现的次数。输出的结果是得分最佳的30个蛋白的列表,包括它们在OWL中的条目名称、相符肽段序列、和其它统计信息。模拟研究得出在使用5个或更少输入肽段分子量时,准确率为99%。该搜索服务可通过向mowse@daresburg.ac.uk发送电子邮件实现。为获得更多关于查询格式的细节信息,可以相该地址发送电子邮件,并在消息正文中写上“help”这个词。蛋白质氨基酸组成分析用盐酸在110 ℃将蛋白或多肽水解成游离的氨基酸,用氨基酸分析仪测定各氨基酸的含量。采用经典的阳离子交换色谱分离、茚三酮柱后衍生法,对蛋白质水解液及各种游离氨基酸的组分含量进行分析。仪器基本结构同普通HPLC相似,但针对氨基酸分析进行了细节优化(例如氮气保护、惰性管路、在线脱气、洗脱梯度及柱温梯度控制等等)通常细分为两种系统:蛋白水解分析系统(钠盐系统)和游离氨基酸分析系统(锂盐系统),利用不同浓度和pH值的柠檬酸钠或柠檬酸锂进行梯度洗脱。其中钠盐系统一次最多分析约25种氨基酸,速度较快,基线平直度好;锂盐系统一次最多分析约50种氨基酸,速度较慢,基线一般不如钠盐系统好。分析效果:从目前已知的氨基酸分析方法比较来看,除灵敏度(即最低检测限)比HPLC柱前衍生方法稍低以外(HPLC:0.5 pmol;氨基酸分析仪:10 pmol),其他如分离度、重现性、操作简便性、运行成本等方面,都优于其他分析方法。蛋白质氨基酸残基组成分析的主要步骤包括:首先是蛋白被水解为氨基酸,其次是采用离子色谱等方法进行游离的氨基酸含量和组成的分析。总之利用蛋白可以分析氨基酸,利用氨基酸也可以研究蛋白质。
传统的蛋白鉴定方法,如免疫印迹法、内肽的化学测序、已知或未知蛋白的comigration分析,或者在一个有机体中有意义的基因的过表达通常耗时、耗力,不适合高流通量的筛选。 目前,所选用的技术包括对于蛋白鉴定的图象分析、微量测序、进一步对肽片段进行鉴定的氨基酸组分分析和与质谱相关的技术。1 图象分析技术(Image analysis)“满天星”式的2-DE图谱分析不能依靠本能的直觉,每一个图象上斑点的上调、下调及出现、消失,都可能在生理和病理状态下产生,必须依靠计算机为基础的数据处理,进行定量分析。 在一系列高质量的2-DE凝胶产生(低背景染色,高度的重复性)的前提下,图象分析包括斑点检测、背景消减、斑点配比和数据库构建。 首先,采集图象通常所用的系统是电荷耦合CCD(charge coupled device)照相机;激光密度仪(laser densitometers)和Phospho或Fluoroimagers,对图象进行数字化。 并成为以象素(pixels)为基础的空间和网格。 其次,在图象灰度水平上过滤和变形,进行图象加工,以进行斑点检测。 利用Laplacian,Gaussian,DOG(difference of Gaussians) opreator使有意义的区域与背景分离,精确限定斑点的强度、面积、周长和方向。图象分析检测的斑点须与肉眼观测的斑点一致。 在这一原则下,多数系统以控制斑点的重心或最高峰来分析,边缘检测的软件可精确描述斑点外观,并进行边缘检测和邻近分析,以增加精确度。 通过阈值分析、边缘检测、销蚀和扩大斑点检测的基本工具还可恢复共迁移的斑点边界。 以PC机为基础的软件Phoretix-2D正挑战古老的Unix为基础的2-D分析软件包。 第三,一旦2-DE图象上的斑点被检测,许多图象需要分析比较、增加、消减或均值化。 由于在2-DE中出现100%的重复性是很困难的,由此凝胶间的蛋白质的配比对于图象分析系统是一个挑战。 IPG技术的出现已使斑点配比变得容易。 因此,较大程度的相似性可通过斑点配比向量算法在长度和平行度观测。 用来配比的著名软件系统包括Quest,Lips,Hermes,Gemini等,计算机方法如相似性、聚类分析、等级分类和主要因素分析已被采用,而神经网络、子波变换和实用分析在未来可被采用。 配比通常由一个人操作,其手工设定大约50个突出的斑点作为“路标”,进行交叉配比。 之后,扩展至整个胶。例如:精确的PI和MW(分子量)的估计通过参考图上20个或更多的已知蛋白所组成的标准曲线来计算未知蛋白的PI和MW。 在凝胶图象分析系统依据已知蛋白质的pI值产生PI网络,使得凝胶上其它蛋白的PI按此分配。 所估计的精确度大大依赖于所建网格的结构及标本的类型。 已知的未被修饰的大蛋白应该作为标志,变性的修饰的蛋白的PI估计约在±0。25个单位。 同理,已知蛋白的理论分子量可以从数据库中计算,利用产生的表观分子量的网格来估计蛋白的分子量。 未被修饰的小蛋白的错误率大约30%,而翻译后蛋白的出入更大。 故需联合其他的技术完成鉴定。2 微量测序(microsequencing)蛋白质的微量测序已成为蛋白质分析和鉴定的基石,可以提供足够的信息。 尽管氨基酸组分分析和肽质指纹谱(PMF)可鉴定由2-DE分离的蛋白,但最普通的N-末端Edman降解仍然是进行鉴定的主要技术。 目前已实现蛋白质微量测序的自动化。 首先使经凝胶分离的蛋白质直接印迹在PVDF膜或玻璃纤维膜上,染色、切割,然后直接置于测序仪中,可用于subpicomole水平的蛋白质的鉴定。 但有几点需注意:Edman降解很缓慢,序列以每40 min 1个氨基酸的速率产生;与质谱相比,Edman降解消耗大;试剂昂贵,每个氨基酸花费
2003年人类基因组精细图绘制完成,是人类科学史上一个里程碑式的事件。后基因组时代的研究重点自然落在了蛋白质头上。为啥?因为中心法则告诉我们,基因的产物——蛋白质,是生命活动的最终执行者。与基因组类比,研究生物体内全套蛋白质的科学,就是蛋白质组学。基因组计划完成的同年,人类蛋白质组计划启动,令人激动的是,2014年人类蛋白质组的草图也完成了。而蛋白质组学能够飞速发展的最大功臣非质谱莫属。质谱的应用范围非常广泛,但这里只讨论蛋白质组学中的质谱。简单地说,质谱法(mass spectrometry)就是对肽段离子的重量(质荷比,m/z)进行测量的分析方法。样品经质谱仪(mass spectrometer)检测得到质谱图(mass spectrum),通过对质谱图的分析就可以对样品中的蛋白进行鉴定、定量。亲,图1的这种典型的蛋白质组学流程都很熟悉吧。蛋白首先都要被特异性的酶(通常为Trypsin)切割为肽段,再进行后续分析,这在蛋白质组学中被称为“自下而上”的研究策略(Bottom-up proteomics)。我们平时见到的质谱分析基本都是这种类型。提到蛋白质组,即会联想到一系列高大上的名词,iTRAQ、SWATH、SILAC、Shotgun、Label-free等等。很多概念容易弄混淆,下面我们就来理理清楚。图1. 典型的蛋白质组学流程大体上,质谱研究蛋白主要是鉴定和定量。通过二级质谱图(MS2或者MS/MS)进行数据库搜索匹配鉴定蛋白。通过各种标记或非标记的手段对不同样品中的蛋白进行比较就是定量。蛋白定量比较是质谱最重要的用途,图2是对定量方法的一个简单总结。非标定量(Label-free)不需要标记,不同样品分别处理、分别进质谱检测;优点是处理简单、无需标记、价格便宜、可以比较很多组样品,缺点是对操作步骤、LC、质谱稳定性要求严格。SILAC是在细胞培养基中加入稳定同位素标记的氨基酸,在代谢水平标记蛋白,一级质谱图进行定量,可以做到三组样品混合后进行比较,定量准确,但是不能标记组织样本,养细胞成本也较贵。双甲基化标记是通过化学反应的办法在肽段水平进行标记,一级质谱定量,也可以三组对比,标记试剂都比较便宜,而且可以标记任何来源的样品。iTRAQ和TMT是商品化的试剂盒,肽段水平标记,二级质谱定量;分别可以做到最多8组和10组样品间蛋白质组的比较。图2. 质谱定量方法以上这几个是一家的,还有几个名词是属于另外一家,比如Shotgun (DDA)、SWATH/DIA、SRM (MRM)、MRMHR/PRM。质谱进行数据采集的方式大致分为三种:鸟枪法(Shotgun)、选择反应监控(SRM)和全景式的SWATH/DIA。下面对照图3再来简单介绍一下。图3. 质谱扫描方式DDA、IDA、Shotgun和鸟枪法说的是相同的东西,意思是质谱在每个循环的中从一级里挑选丰度高的TopN个肽段去打碎做二级扫描,得到的结果通过与已知数据库中的理论蛋白进行匹配。DDA简单有效,分析流程比较成熟,也是目前质谱分析的主流方式。DDA也有其固有的缺陷,即具有一定的随机性,偏向于检测丰度较高的肽段,而抑制了低丰度肽段的检测。靶向策略被称为质谱领域的Western blot。质谱只去采集目标肽段大小的离子信息,因而提高了灵敏度和特异性。这种方法用来研究感兴趣的特定蛋白,定量准确,但是通量很有限。SWATH/DIA这种全景式的数据采集方式在最近几年突然火了起来,被认为在不远的未来可能会取代DDA的主流位置。该方法采取的策略是将扫描范围内的所有肽段按照质荷比分为若干个窗口,再对每个窗口里所有的肽段一起打碎,采二级,数据分析时通过抽提蛋白的子离子信息进行定量。SWATH/DIA解决了DDA中随机性选择肽段的缺陷,所以重复性更好,定量的准确性基本达到了SRM的水平,而且可以实现大规模定量。借用听来的一个比喻来说明:DDA就像机关枪扫射,数量多、体积大的目标命中的概率要大一些。靶向扫描(SRM或PRM)就像精准狙击,排除干扰,目标明确,每一枪直指目标,但是难以大规模消灭敌人。SWATH/DIA就是地毯式轰炸,只要暴露在我方攻击范围内的敌人,不管三七二十一,全部炸完。图4. 定量方法与采集方式结合如果将上述的定量方法(图2)和质谱数据采集方式(图3)结合起来,就得到了现在基于质谱的蛋白质组学研究的各种策略(图4)。再打个比方,保证吃货们一听就懂:鸡、鱼、肉、蛋、蔬菜要通过炒锅、烤箱、高压锅、微波炉等烹调之后才能变为美食,填饱肚子。同样的,各种定量方法(非标的和标记的)处理的样品,要通过质谱各种采集方式变为电脑中的数据,才能分析并从中得到蛋白的信息。本次的介绍就先到这里了,如果其中有什么问题,欢迎您批评和建议,我们会努力变得更好;如果需要跟我们进行技术交流和讨论,欢迎大家联系武汉金开瑞。后续我们还会继续推出对质谱技术各方面进行解析的文章,敬请期待。ReferencesA draft map of the human proteome. Nature 509: 575–581 (2014)Mass-spectrometry-based draft of the human proteome. Nature 509: 582–587 (2014)A review: Annu. Rev. Biochem. 80: 273–99 (2011)SILAC: Molecular & Cellular Proteomics 1: 376-386 (2002)iTRAQ: Molecular & Cellular Proteomics 343: 91–99 (2010)SRM: Nature Methods 9: 555–566 (2012)SWATH: Molecular & Cellular Proteomics 11: 1–17 (2012)
质谱技术在蛋白鉴定等实验中具有不可忽视的作用,应用前景十分广泛。那么,有问题了怎么解决呢?问题1. 一级质谱和二级质谱有什么区别?什么时候做一级,什么时候做二级?答:一级质谱鉴定的方式主要指胎指纹图谱(peptide-mass mapping, PMF),即利用质谱仪精确测量酶解片段的分子量并搜库比较实现蛋白质的鉴定,二级质谱是在一级质谱的基础上再选择部分肽段做进一步的破碎并对碎片进行深入分析和比较,鉴定出该肽段的序列并结合PMF的结果从而实现蛋白质的鉴定。二级质谱能够得到部分肽短的序列,具有更高的可靠性。随着现在杂志对数据的要求越来越严格,二级质谱鉴定是蛋白鉴定的大趋势,而且即使目前做一级质谱鉴定的结果,也需要挑选部分PMF结果做二级质谱验证。问题2. 研究的物种不是模式生物怎么办?答:可以参考亲缘关系最近的模式生物做比对而实现蛋白质的成功鉴定,如果质谱图很好而没有鉴定结果说明这是一个全新的蛋白,可以采用de-novo等技术做深入分析与鉴定。问题3. 该如何评价质谱效果的好坏?答:做PMF一般得分超过60分(P0.05)就算成功鉴定,而串联质谱,得分超过60分或者虽然没有超过60分,但是有最少一条肽段的得分超过30分就算成功鉴定。问题4. 一些特殊的质谱方法有什么用途?答:质谱的其它用途包括修饰位点分析、蛋白测序、混合蛋白鉴定以及分子量精确测定、二硫键位置分析等等。问题5. 用什么染色方法比较好?答:最好用考马斯亮蓝法进行染色,银染也可以,但鉴定成功率稍低,并且推荐用串联质谱对银染蛋白进行鉴定可以大大提高鉴定成功率。问题6 质谱鉴定取胶点有什么注意事项?答:离心管最好用进口离心管,以免塑料污染;水最好用去离子水或者双蒸水;取点的时候带好口罩与手套,以免角蛋白污染。问题7. 凝胶是否可以长期保存?该如何保存?如何运送?答:蛋白凝胶可以长期保存而不影响质谱鉴定效果,一般而言,如果在一两个星期以内,最好用保鲜膜包好,放到4度冰箱保存,如果保存时间超过一个月,可以把蛋白点取下后放入-20度或者-80度冰箱,不会影响后续质谱鉴定效果。运送胶点的时候采用常温运送即可,三五天内都不会有太大的影响。问题8. 质谱鉴定大致是什么流程?质谱鉴定主要包括蛋白酶解、质谱数据获取、对库检索三个步骤。问题9. 串联质谱鉴定和质谱测序有什么区别?质谱鉴定往往采用软件对已有数据库进行自动检索匹配得到结果,而质谱测序则需要根据质谱峰图中相邻或者相近峰的分子量差异直接推算出肽段的序列。问题10. 未知蛋白质是通过质谱还是蛋白质测序仪来测序的呢?现在比较简单的方法是质谱法。如果质谱法不能确定的话还可以结合N端测序,可测10几个氨基酸。两个数据结合分析基本可以确定目的蛋白了,现在的蛋白质组数据库相当强大了。不知道看完这10个FAQ,各位有没有些许受益,如果还有好的想法或者意见,欢迎给小编留言!(来源:互联网)
这是日本关于质谱测定蛋白N端序列的文献,大家看看。[img]http://www.instrument.com.cn/bbs/images/affix.gif[/img][url=http://www.instrument.com.cn/bbs/download.asp?ID=120693]质谱测定蛋白N端序列[/url]
各位大侠,给支个招,哪里可以既做高效液相又蛋白测序啊?我的样品现在是两个成分混在一起,分子量又都很小,我想测序,可最好是先用HPLC分开再来测,哪家公司或者研究所提供这方面的服务啊?
蛋白质组学研究的一般工具与方法随着人类基因组计划取得巨大的成功和许多物种基因组测序的完成,仅仅靠基因组的序列来试图阐明生命现象是远远不够的,因此,研究重心已经开始从揭示生命的所有遗传信息转移到在分子整体水平对功能的研究上,生命科学已实质性地跨入了后基因组时代。 尽管现在已经有多个物种的基因组被测序,但这些基因组中通常有一半以上基因的功能是未知的。目前功能基因组研究中所采用的策略,如微阵列法(microarray)(Wodicka et al., 1997)、基因芯片(gene chips)(Ramsay et al., 1998)、基因表达序列分析(SAGE)(Velculescu et al., 1995)等,都是从细胞中mRNA的角度来考虑的。但事实上,从DNA、mRNA到蛋白质存在三个层次的调控,mRNA自身也存在着贮存、转运和降解等问题,从mRNA角度考虑,实际上仅包括了转录水平调控,并不能全面代表蛋白质表达水平。实验也证明,组织中mRNA丰度与蛋白质丰度的相关性并不好,尤其对于低丰度蛋白质来说,相关性更差。蛋白质复杂的翻译后修饰,蛋白质的亚细胞定位或迁移,蛋白质-蛋白质相互作用则几乎无法从mRNA水平来判断(曾嵘,夏其昌,2002)。新生肽链合成后存在多种加工、修饰过程,蛋白质间也存在类似于mRNA分子内的剪切、拼接,研究证明基本元件“intein”广泛存在于蛋白质中(Perler et al., 1997)。基因与其编码产物蛋白的线性对应关系只存在于新生肽链而不是最终的功能蛋白质中。 蛋白质是生理功能的执行者和生命现象的直接体现者,对蛋白质结构和功能的研究将直接阐明生命在生理或病理条件下的变化机制;蛋白质本身的存在形式和活动规律,如翻译后修饰、蛋白质间相互作用及蛋白质构象等问题,仍依赖于直接对蛋白质的研究来解决。因此要对生命的复杂活动有全面和深入的认识,必然要在整体、动态、网络的水平上对蛋白质进行研究(钱小红,贺福初,2003)。 蛋白质组学研究中常用的技术体系 方法学上,二维凝胶电泳-质谱仍然是目前最流行和可靠的技术平台(Rabilloud et al., 2000)。其一般过程是:细胞或组织样品——样品制备——二维凝胶电泳(2D-PAGE)分离蛋白质——计算机辅助分析2D-PAGE图象——对感兴趣的蛋白质进行酶解——质谱分析——数据库检索——蛋白质鉴定——分析蛋白质在细胞与组织中的表达情况。 2-D PAGE 样品制备 2D-PAGE 的操作流程基本上实现了程序化。但是,样品制备是一个非常关键与复杂的过程。成功的2D-PAGE取决于对样品中蛋白质有效的抽提和它的溶解性。与核酸不同,目前没有一种通用的方法适用于所有的蛋白质,来源不同的蛋白质都受到自身蛋白质制备方法的挑战。 正确的样品制备方法从收集样品开始时就要防止样品的裂解和被蛋白水解酶降解(Rabilloud et al., 2000)。要尽可能溶解更多的蛋白,并且在2D-PAGE过程中保持它的溶解性,阻止蛋白质的人为修饰。在样品制备过程中,各个实验室也通过实验建立了更为可行的方法。目前通过建立分步提取方法可以有效地提取出更多的蛋白质(兰彦等,2001)。另一种对蛋白质采用预分离的方法称为“多间隔电解法(multi-compartment-electrolyser)”,采用这种方法后,分辨率和胶的质量均明显改善(Herbert et al., 2000)。 但是,由于生物样品的多样性和复杂性,目前所采用的样品制备方法具有局限性。其它物质对蛋白质样品制备存在干扰。核酸通过与蛋白质结合,增加样品黏度而干扰等点聚焦(IEF)分离的效果。当然,通过实验探索,采取一些措施可以减轻它的干扰。例如,在样品制备过程中加入非特异性的核酸酶或RNase与DNase的混合物,在等电聚焦时将每个胶条的电流限制在50mA以内通常可以消除其影响。脂类物质的影响可以通过利用有机溶剂的方法将其去除,但是这常常会导致蛋白质的不可逆沉淀。除了蛋白质的降解之外,糖基化是蛋白质的最重要的人工修饰,样品中的尿素在这一过程中起着非常重要的作用。样品中的尿素在降解的过程中会形成能够与蛋白质的氨基反应的氰酸盐,这种结果会导致蛋白质带有更多的正电荷。所以,在2D-PAGE中要用新鲜的尿素溶液,在等电聚焦过程中要控制温度不能太高(Beranova-Giorgianni, 2003)。但是,目前还没有一种简单有效的方法来去除样品中的多糖。 样品分离和分析 样品制备完成后运用IEF和SDS-PAGE电泳对它进行分离,常采用银染和考马斯亮兰染色即可观察到具有许多蛋白质斑点的凝胶图像。等电聚焦电泳与SDS-PAGE的具体操作步骤已经实现了程序化,均有详细操作流程参考,但是由于样品的不同,不同样品的具体条件还需要试验探索。第二相SDS-PAGE运行结束,染色完毕后,利用计算机软件对凝胶图像进行分析,如PD-QUEST软件,LIPS,HERMES,GEMINI等,对凝胶图像上的蛋白质斑点进行匹配,对图像进行数字化处理等分析(贾宇峰等,2001),对感兴趣的蛋白质采用质谱分析。 低丰度蛋白质的检测 低丰度蛋白在蛋白质组学研究中常常是人们非常感兴趣的,因为细胞或组织中的一些生物活性物质,如细胞分泌的一些活性物质,受体等表达量都非常低。按照一般电泳的上样量,这些小分子是根本看不到的,但如果单纯地增加上样量,细胞或组织中的大量表达的蛋白就会将其覆盖,而且上样量过大也会影响电泳结果。所以对这些低丰度的样品可以进行富集,富集的方法可以通过层析,如亲和层析,离子交换层析等方法,还可以通过利用样品等电点性质等方法将pH范围相近的蛋白质富集(Santoni et al., 2000; Beranova-Giorgianni, 2003)。
6 质谱仪的最新进展用质谱检测蛋白,首先考虑到用PMF与 MALDI-TOF联用,如果无法检测,下一步就用ESI-MS/MS创建序列标签。在PMF分析中,MALDI的平板中只需一小部分样本就足以检测,剩下的样本就可以用来创建序列标签。并且,在MALDI-TOF仪器上,用一种叫做“源后延迟”的方法可以对只有部分序列的肽段进行检测。然而,用这个方法产生的质谱图比较难说明,精确性也很差。最近,用MALDI联合四级杆-时间质谱分析器[30,31]以及原始的MALDI-TOF/TOF[32]方法产生了。因此同一份标本可以首先考虑用PMF检测蛋白[33],如果有必要的话,再用MS/MS创建序列标签。MALDI联合四级杆-TOF检测高通量蛋白是有希望的[31]。7 蛋白质组研究中的转录后修饰分析蛋白组分析很重要的一点就是能对蛋白表达水平以及转录后修饰,如磷酸化和糖基化进行研究。蛋白质的磷酸化是很有趣的,因为在信号转导途径中它扮演了重要的角色。最早检测蛋白质表达水平的方法是进行2-DE之前用35S-Met对样本进行代谢性标记,再在2-DE上进行放射自显影[34-36]。在凝胶中,不同蛋白的磷酸化和糖基化位点通常在凝胶中显示一连串蛋白质点,但是还需要做更详细的分析来确定修饰类型。蛋白质磷酸化的改变既可以用32P标记细胞,也可以用特异性磷酸化抗体做western blotting进行研究。如果用32P标记的方法,仍然需要做2-DE。经过凝胶比较后,把感兴趣的点从胶上切下来,然后用质谱鉴定[36]。Soskic使用的是印迹法,两个2-DE同时进行,一个用于做特异的磷酸化抗体实验,另一个做常规染色。蛋白质磷酸化和糖基化更为详细的特性可以用质谱来检测,但是需要更多的起始材料而不仅仅是二维凝胶上的一个点。另外这些分析不能产生直接的序列信息,技术上也比用质谱检测蛋白要难的多。在蛋白上查找磷酸化位点有很多种方法。为了检测消化后的混和肽中哪一个是磷酸化的,可以用MALDI-MS在磷酸化前后对混合肽做PMF分析:经过磷酸酯酶处理后,磷酸化的肽将会失去一个磷酸基团,分子量将比处理前小80Da.糖基化研究中,多聚糖从蛋白中释放出来,对多聚糖结构的检测就是从这些游离的多聚糖中得到的。一般把MALDI仪和外源性糖苷酶[37-40]联合使用进行检测。如果需要更为详细的信息,可以用ESI-MS联合使用前体离子扫描仪[41-44]。到目前为止,能够用电泳分离后的蛋白进行糖蛋白结构检测的报道很少。其中有一项研究是N端糖蛋白酶切以后用一维SDS-PAGE分离,然后用MALDI-MS以及外源性的糖苷酶进行结构分析[45]。8 用质谱研究蛋白-蛋白之间的作用经典的蛋白组学着重于研究蛋白质在何时何处表达。因为大部分的细胞功能都是由蛋白质复合体而不是由单个蛋白来执行的,所以鉴定蛋白质的成分和相互作用是非常重要的。这个过程可以用生物化学方法纯化蛋白质后用质谱来鉴定不同的成分,如人类剪接体的成分,酵母的核孔复合体[46]以及核蛋白体等都可以用此策略检测出来。一般的蛋白复合体是用亲和层析的方法纯化和分离,如免疫沉淀反应[47,48]。 DNA结合蛋白可以用同它们有特异性亲和力的核酸来分离,然后用质谱来鉴定[49]。Rigaut等人在串联层析的基础上,建立了一种通用的蛋白质复合体纯化方法[50]。在这个方法中,一种TAP标签和靶蛋白融合在一起,然后把蛋白转移到宿主细胞或者组织中,融合蛋白在宿主细胞和组织中能持续表达。TAP标签包括一种A蛋白和一种钙调蛋白,在标签之间有一个TEV蛋白酶切位点。用串联亲和层析法能将融合蛋白及与它相互作用的蛋白成分从细胞提取物中有效的分离,纯化出来。Rappsiber等人分别用亲和层析,交叉耦合以及质谱等方法[51]对酵母的核孔复合物Nup85p的亲和性进行研究。经过层析以后,用一维SDS-PAGE方法就可以分离蛋白复合体中的各个成分,因此二维电泳的不足之处就可以避免。同样也有可能直接用[url=https://insevent.instrument.com.cn/t/Yp][color=#3333ff]LC-MS[/color][/url]方法分析大分子量蛋白质复合体[52]。蛋白组分析的优越之处主要是用于蛋白和蛋白之间的相互作用以及蛋白的转录后修饰的研究,同时也可以用于基因表达水平的研究。质谱对于蛋白组分析来说是一项非常重要的技术,近年来仪器以及数据库软件的发展使得质谱成为能力更强大的工具。参考文献[1] O’Farrell PH. J Biol Chem,1975,250:4007–4021.[2] Karas M, Bachmann D, Bahr U, et al. Int J MassSpecrom Ion Process,1987,78:53–68.[3] Meng CK, Mann M, Fenn JB. et al. Atoms, Mol Clusters,1988,10:361–368.[4] Fenn JB, Mann M, Meng CK, et al.Science,1989,6(246):64–71.[5] Corthals GL, Wasinger VC, Hochstrasser DF, et al.Electrophoresis,2000,21:1104–1115.[6] Celis JE, Kruhoffer M, Gromova I, et al. FEBS Lett,2000,480:2–16.[7] Anderson L, Seilhamer J. Electrophoresis,1997,18:533–537.[8] Gygi SP, Rochon Y, Franza BR, et al. Mol Cell Biol,1999,19:1720–1730.[9] Henzel WJ, Stults JT, Wong SC, et al. ProcNatl Acad Sci USA,1993,90:5011–5015.[10] Mann M, Hojrup P, Roeppstorff P. Biol Mass Spectrom,1993,22:338–345.[11] Pappin DJ, Hojrup P, Bleasby AJ. Curr Biol,1993,3:327–332.[12] James P, Quadroni M, Carafoli E, et al. Biochem BiophysRes Commun,1993,195:58–64.[13] Yates JRD, Speicher S, Griffin PR, et al. AnalBiochem,1993,214:397–408.[14] Mann M, Wilm M. Anal Chem,1994,66:4390–4399.[15] Eng JK, McCormack AL, Yates JR. J Am Soc Mass Spectrom,1994,5:976–989.[16] Wilm M, Mann M. Int J Mass Spectrom Ion Process,1994,136:167–180.[17] Wilm M, Shevchenko A, Houthaeve T, et al. Nature 1996 379:466–469.[18] Wilm M, Mann M. Anal Chem,1996,68:1–8.[19] Morris HR, Paxton T, Panico M, et al. JProtein Chem,1997,16:469–479.[20] Rosenfeld J, Capedeville J, Guillemot JC, et al. AnalBiochem,1992,203:173–179.[21] Shevchenko A, Wilm M, Mann M. Anal Chem,1996,68:850–858.[22] Pandey A, Andersen JS, Mann M. Science’s STKE: www.stke.org/cgi/content/full/OC–sigtrans 2000/37/pl1.[23] Kussmann M, Nordhoff E, Rahbek-Nielsen H, et al. J Mass Spectrom,1997,32:593–601.[24] Gobom J, Nordhoff E, Mirgorodskaya E, et al. J Mass Spectrom,1999,34:105–116.[25] Clauser KR, Baker P, Burlingame AL. Anal Chem,1999,71:2871–2882.[26] Binz PA, Muller M, Walther D, et al. Anal Chem,1999,71:4981–4988.[27] Bienvenut WV, Sanchez JC, Karmime A, et al. Anal Chem,1999,71:4800–4807.[28] Neubauer G, King A, Rappsilber J, et al. Nat Genet,1998,20:46–50.[29] Yates III JR, Carmack E, Hays L, et al. MethodsMol Biol,1999,112:553–569.[30] Loboda AV, Krutchinsky AN, Bromirski M, et al. Rapid Commun Mass Spectrom,2000,14:1047–1057.[31] Shevchenko A, Loboda A, Schevchenko A, et al. Anal Chem,2000,72:2132–2141.[32] Medzihradszky KF, Campbell JM, Baldwin MA, et al. Anal Chem 2000,72:552–558.[33] Krutchinsky AN, Zhang W, Chait BT. J Am Soc Mass Spectrom,2000,11:493–504.[34] Nyman TA, Matikainen S, Sareneva T, et al. Eur J Biochem 2000 267:4011–4019.[35] Celis JE, editor. Cell Biology: A Laboratory Handbook, vol. 4,2nd. Academic Press, 1998,375–385.[36] Gerner C, Frohwein U, Gotzmann J, et al. J Biol Chem,2000,Sep 7 [epubahead of print].[37] Colangelo J, Orlando R. Anal Chem,1999,71:1479–1482.[38] Geyer H, Schmitt S, Wuhrer M, et al. Anal Chem1999 71:476–482.[39] Harvey DJ. Mass Spectrom Rev,1999,18:349–450.[40] Nyman TA, Kalkkinen N, et al. Eur J Biochem,1998,253:485–493.[41] Sheeley DM, Reinhold VN. Anal Chem,1998,70:3053–3059.[42] Reinhold VN, Reinhold BB, Costello CE. Anal Chem,1995,67:1772–1784.[43] Kuster B, Hunter AP, Wheeler SF, et al. Electrophoresis,1998,19:1950–1959.[44] Rout MP, Aitchison JD, Suprapto A, et al. J Cell Biol,2000,148:635–651.[45] Yamaguchi K, Subramanian AR. J Biol Chem ,2000,275:28 466–28 482.[46] Yamaguchi K, von Knoblauch K, Subramanian AR. J BiolChem,2000,275:28 455–28 465.[47] Rotheneder H, Geymayer S, Haidweger E. J Mol Biol,1999,293:1005–1015.[48] Boehning D, Joseph SK. EMBO J,2000,19:5450–5459.[49] Nordhoff E, Krogsdam AM, Jorgensen HF, et al. Nat Biotechnol,1999,17:884–888.[50] Rigaut G, Shevchenko A, Rutz B, et al. Nat Biotechnol,1999,17:1030–1032.[51] Rappsilber J, Siniossoglou S, Hurt EC, et al. Anal Chem2000 72:267–275.[52] Link AJ, Eng J, Schieltz DM, et al. Nat Biotechnol,1999,17:676–682.T.A. Nyman /Biomolecular Engineering, 2001:18 .221–227.
传统的蛋白鉴定方法,如免疫印迹法、内肽的化学测序、已知或未知蛋白的comigration分析,或者在一个有机体中有意义的基因的过表达通常耗时、耗力,不适合高流通量的筛选。 目前,所选用的技术包括对于蛋白鉴定的图象分析、微量测序、进一步对肽片段进行鉴定的氨基酸组分分析和与质谱相关的技术。1 图象分析技术(Image analysis)“满天星”式的2-DE图谱分析不能依靠本能的直觉,每一个图象上斑点的上调、下调及出现、消失,都可能在生理和病理状态下产生,必须依靠计算机为基础的数据处理,进行定量分析。 在一系列高质量的2-DE凝胶产生(低背景染色,高度的重复性)的前提下,图象分析包括斑点检测、背景消减、斑点配比和数据库构建。 首先,采集图象通常所用的系统是电荷耦合CCD(charge coupled device)照相机;激光密度仪(laser densitometers)和Phospho或Fluoroimagers,对图象进行数字化。 并成为以象素(pixels)为基础的空间和网格。 其次,在图象灰度水平上过滤和变形,进行图象加工,以进行斑点检测。 利用Laplacian,Gaussian,DOG(difference of Gaussians) opreator使有意义的区域与背景分离,精确限定斑点的强度、面积、周长和方向。图象分析检测的斑点须与肉眼观测的斑点一致。 在这一原则下,多数系统以控制斑点的重心或最高峰来分析,边缘检测的软件可精确描述斑点外观,并进行边缘检测和邻近分析,以增加精确度。 通过阈值分析、边缘检测、销蚀和扩大斑点检测的基本工具还可恢复共迁移的斑点边界。 以PC机为基础的软件Phoretix-2D正挑战古老的Unix为基础的2-D分析软件包。 第三,一旦2-DE图象上的斑点被检测,许多图象需要分析比较、增加、消减或均值化。 由于在2-DE中出现100%的重复性是很困难的,由此凝胶间的蛋白质的配比对于图象分析系统是一个挑战。 IPG技术的出现已使斑点配比变得容易。 因此,较大程度的相似性可通过斑点配比向量算法在长度和平行度观测。 用来配比的著名软件系统包括Quest,Lips,Hermes,Gemini等,计算机方法如相似性、聚类分析、等级分类和主要因素分析已被采用,而神经网络、子波变换和实用分析在未来可被采用。 配比通常由一个人操作,其手工设定大约50个突出的斑点作为“路标”,进行交叉配比。 之后,扩展至整个胶。例如:精确的PI和MW(分子量)的估计通过参考图上20个或更多的已知蛋白所组成的标准曲线来计算未知蛋白的PI和MW。 在凝胶图象分析系统依据已知蛋白质的pI值产生PI网络,使得凝胶上其它蛋白的PI按此分配。 所估计的精确度大大依赖于所建网格的结构及标本的类型。 已知的未被修饰的大蛋白应该作为标志,变性的修饰的蛋白的PI估计约在±0。25个单位。 同理,已知蛋白的理论分子量可以从数据库中计算,利用产生的表观分子量的网格来估计蛋白的分子量。 未被修饰的小蛋白的错误率大约30%,而翻译后蛋白的出入更大。 故需联合其他的技术完成鉴定。
向大家请教几个问题1. 在使用MALDI-TOF的时候,为什么大分子量的蛋白质可以被有效分析,而大于80bp的DNA分析的效果不好?2. Electrospray-TOF和MALDI-TOF在分析蛋白质的时候有那些区别?3. 质谱用于蛋白质测序中的几种方法及原理?先道谢!本人对蛋白质分析实在是不熟悉。请解答的详细一些!再次致谢!
蛋白分析系统在我们选择蛋白分析工具的时候,通常是根据不同的蛋白来选择不同的分析手段,如凝胶电泳、化学荧光染色、质谱等等。但是目前已经研制出的蛋白分析工具的种类繁多,从这一方面也在一定程度上反映了蛋白分析的复杂性。以下是一些近期推出的蛋白分析系统,希望能帮助您轻松完成研究工作。
生物质谱技术帮助发现精神分裂症特征蛋白 (2006-12-28 9:34:47,新闻来源:人民网) 日前,四川泸州医学院附属医院硕士研究生姜伟,在导师王开正教授指导下,利用表面增强激光解析电离飞行时间质谱技术,发现了一组对精神分裂症的早期预警、鉴别诊断、治疗观察具有重要意义的蛋白标志物。 目前鉴别诊断精神分裂症缺乏有效的病理学、影像学和实验诊断依据,也缺乏客观的检查指标用于早期诊断,这也是造成对某些精神分裂症的评定产生分歧、鉴定困难的原因之一。 姜伟等人应用获得诺贝尔化学奖、高灵敏度高解析度的表面增强激光解析电离飞行时间质谱技术,检测精神分裂症血清蛋白质指纹图谱,将40名精神分裂症患者血清与44名其他人对照血清随机分为训练集和验证集,将筛选训练集精神分裂症差异蛋白建立人工神经网络诊断模型,再将验证集验证该模型的诊断效率。结果发现精神分裂症患者与对照组血清蛋白质指纹图谱有15个差异表达的蛋白质荷比峰,筛选出其中6个有明显表达差异的标志蛋白,建立的人工神经网络诊断模型对精神分裂症的诊断灵敏度和特异性分别为95.0%和95.8%,阴性预测值和阳性预测值分别为95.8%和95.0%。姜伟等人依据这一结果认为,精神分裂症患者血清具有高表达的特征蛋白,建立的人工神经网络模型为精神分裂症的实验诊断提供了一种蛋白组学的新方法。这种方法检查过程快速、简便,不会破坏所测定的蛋白质,结果可靠,可重复检测。 ————2006.12.27健康报也有报道--------------------------------------------------------------------另:两毫升血5小时鉴别精神分裂症 作者:周丽 文章来源:泸州晚报 点击数:0 更新时间:2006-12-20 只需要从体内抽取两毫升鲜血,经过5个小时的实验室检测,就能诊断是否患有精神分裂症。昨(19)日记者获悉,如此简便的方法已经在我市投入使用,这也是西南地区首次将诺贝尔化学奖应用到精神分裂症的实验室诊断中。 据悉,该技术在泸医附院检验科正式投入使用。泸医附院检验科主任王元正告诉记者,泸医附院引进的表面增强激光解析电离飞行时间质谱技术是获得2002年诺贝尔化学奖的高新技术,通过对患者的抽血检测,发现了一组对精神分裂症的早期预警、鉴别诊断、治疗观察具有重要意义的蛋白标志物。 而泸医附院引进的这种技术,将精神分裂症患者血清蛋白指纹图与健康人做差异蛋白组学分析,利用计算机程序找到了精神分裂症患者特征表达的蛋白质,将6个蛋白的相对含量建立人工神经网络诊断模型并进行盲法验证。结果显示,对精神分裂症的诊断灵敏度为95.0%,特异性为95.8%。整个实验检测过程只需要5个小时。 目前,全国对此技术的利用并不广泛,泸医附院在西南地区率先引进使用。这种技术还用于肿瘤、心血管疾病、风湿免疫性疾病、感染性疾病等疑难疾病的鉴别诊断,特别是对各种肿瘤的早期诊断灵敏度和特异性都在95%以上。
质谱与蛋白质组学蛋白质组学对一个细胞或组织所表达的蛋白质进行的系统分析,而质谱是它的关键性分析工具。在过去的两年中,标准蛋白质组技术中的进展增进了更高水平自动化和敏感性的蛋白质识别技术。另外,新的技术促成了鉴定蛋白质功能相关特性的里程碑性的进展,包括它们的定量和在蛋白质复合物中复杂情况。缩写2DE two-dimensional gel electrophoresis双向凝胶电泳CID collision-induced dissociation碰撞诱导的解离ESI electrospray ionization电喷雾离子化FT-ICR Fourier-transform ion cyclotron resonance傅里叶-变换离子回旋加速器共振ICAT isotope-coded affinity tagsIEF isoelectric focusing等电聚焦MALDI matrix-assisted laser desorption ionization基质辅助的激光解析离子化Q-TOF quadrupole-TOFRP reversed phase反向TOF time-of-flight飞行时间简介蛋白质组学的核心组成是系统识别一个细胞或组织中表达的每一个蛋白质,以及确定每个蛋白质的突出特征(比如,丰度、修饰状态以及在多蛋白质复合体中的复杂状态)。这些分析的技术包括分离蛋白质和肽的分离科学、识别和定量分析物的分析科学和数据管理和分析的生物信息学。它的初步工具包括使用IEF(等电点聚焦)/SDS-PAGE凝胶的高分辨率的双向凝胶电泳(2DE),结合质谱和数据库搜索来分离、识别和定量在一个复合样本中存在的个体蛋白质,最终识别被分离的蛋白质。一个常用的方法用在Fig1中用图解说明。此技术以及由此而来的变化(综述见[1])已经被用来识别和分类在复杂样本中存在的大量蛋白质,并在蛋白质组数据库中呈现它们,该过程我们这里称之为"描述蛋白质组学"比如,Shevchenko等[2]从2D凝胶上系统地鉴定了150个蛋白质。数目庞大的这样的数据库现在可以找到。同样的技术现在已经被作为普遍的发现工具来动态检测一个细胞或组织对外来或内部干扰反应而在蛋白质组中的改变。因为检测动态改变需要精确定量每个被检测成分,我们使用"定量蛋白质组学"来定义。在此报告中,我们总结了自1999年1月至2000年4月来报道的与蛋白质组学和质谱相关的最重要的进展。在核心质谱技术中的进展已经导致2DE为基础的蛋白质组学技术的进一步改进。它们同时又促进了传统凝胶为基础的方法的替代方法,诸如引入以同位素稀释理论为基础的精确蛋白质定量技术和蛋白质复合物的系统分析。蛋白质组分析的MS技术进展在此部分,我们总结了在MS设备、它们的控制和操作中的进展,以及比较质谱数据和序列数据库识别蛋白质所用的搜索工具的进展。随着新型质谱仪的引入,蛋白质组学研究现存类型的质谱仪性能已经显著改进了。在此综述期间最普遍使用的仪器是可以分为两类:单一阶段的质谱仪和串联质谱为基础的系统。单一阶段的质谱仪,最显著的是基质辅助的激光解吸电离(MALDI)飞行时间(TOF)仪器,被用于无数通过肽质谱图谱技术大规模蛋白质识别的项目中。此方法在鉴别表达自小一些的和完全测序的基因组的蛋白质特别成功[3,4]。串联质谱仪器诸如triple quadrpole、离子捕获(ion-trap)和近来引进的混合quadrupole飞行时间(Q-TOF)被常规应用于[url=https://insevent.instrument.com.cn/t/Yp][color=#3333ff]LC-MS[/color][/url]/MS或用电喷雾电离(ESI)来生成肽片段离子谱,以便通过搜寻序列数据库进行蛋白质鉴定。使用仪器控制程序来自动选择肽离子进行碰撞诱导的解离(CID)(数据依赖CID)的不断增多是这些MS/MS仪器的一个明显的趋势。一些新的构造的具有高潜能的质谱仪被引入到蛋白质组学研究中产生深刻影响。两个研究组近来一个MALDI离子源和一个混合Q-TOF耦联了起来[5,6]。Q-TOF提供的质量准确性和敏感性提升了数据库搜寻结果并同时使它成为MS/MS从头测序的当然仪器选择。MALDI Q-TOF构造提供了激动人心的机会进行自动化和高通量应用以及在一个样品盘上存档样品进行日后研究的可能。Medzihradszky等[7]描述了一个不同的混合仪器称之为MALDI TOF TOF。此设备享有许多MALDI Q-TOF的优点,另外能够进行高能量CID和非常快速的扫描速率。傅里叶-变换离子回旋加速器共振(FT-ICR)质谱对于蛋白质组学来说相对陌生。这些设备具有非常高的敏感性和分辨率,质量精确性可以达到1ppm。这些特征被用来在一次分析中测量和定量几百种蛋白质的完整的分子质量[8]。Goodlett等[9]表明FT-MS测量的一个肽的准确质量以及可以容易获得的限制因素能够通过序列数据库搜索被用来识别蛋白质。蛋白质组学如果没有软件工具来进行质谱数据和序列数据库的关联将变得几无可能。现存的数据库搜索程序已经变得越来越成熟和可以(从网络)可获得。另外,引入了新的算法。主要相关程序是Sequest[10],MASCOT[11],PeptedeSearch[12],PROWL[13]和Protein Prospector[14]。在它们中间,Sequest使用CID谱设置了蛋白质识别的实验室标准(benchmark),因为它与边界MS/MS数据工作得最好,并高度可信,可以从整个[url=https://insevent.instrument.com.cn/t/Yp][color=#3333ff]LC-MS[/color][/url]/MS实验中自动分析数据,并不需要任何使用者的破译工作。在所提的程序中,然而,只有Sequest不能在网络上搜索。MASCOT是一个新的、快速、网络可进入和多功能的程序,具有进行肽指纹分析、用部分破译或未破译的CID谱进行数据库搜索的功能。
分子量测定: Q:为什么测定的结果跟理论的结果不一致? A:因为机器测定会有一定的误差,如100000Da的蛋白质最大误差是100Da,如果测定的结果与理论值成倍数关系的可能原因是:0.3倍可能是三电荷峰,0.5倍可能是双电荷峰,原因是样品含碱氨基酸较多;2倍可能是二聚体,3倍可能是三聚体,原因可能是样品中含有过多的二硫键。 Q:为什么我的样品非常纯,但在主峰的附近会有一些小峰?同时在主峰一半或两倍的地方有一个小峰? A:这是因为在激光的扫描的过程中可能会使样品分子损失一些离子,如H2O、NH3等,或者出现样品分子与基质的加合峰,正常的情况下MALDI-TOF单电荷峰占主要,所以有时会在主峰一半或两倍的地方有一个小峰,是双电荷峰和二聚体峰; Q:为什么我的样品纯度、浓度都很好,盐浓度也很低,却得不到结果? A:这只能与蛋白质本身的结构有关,基质不能很好的分离样品,所以希望您能尽可能滇供样品其他的理化质,如酸、碱蛋白、糖蛋白等。的确,有时您的样品的所有质、状态都正常,还是不能得到您想要的结果,这种问题其实已经超出了我们能力的范围,我们仅仅是您整个实验的一个环节,能够做到的是向您提供一个准确的结果。 肽指纹图谱及数据库检索 Q:为什么考马斯染色的结果比银染的结果好。 A:主要是银染的灵敏度较高,得到的蛋白质量较少,再加上在处理样品的过程中银染要脱银,增加洗脱的次数,样品的损失较大,所以噪音和角蛋白污染对目的蛋白的影响较大,对最终的数据库检索也会产生影响 Q:我的PMF的峰值较少,为什么?这些片段数量及峰值是否达到最基本的数据库检索的要求?影响检索的结果吗? A:因为我们用的是胰酶对蛋白质进行降解的,胰酶是一种专一较强的酶,只水解精氨酸、赖氨酸的C端,可能是你的样品的酶解的位点偏多或偏少,偏多酶解为小片段,峰值跟基质在一起难以分辨,偏少肽段的分子量偏大,胶内的样品滞留在胶内,在质谱图上体现不出来,溶液样品可以收集到,但是分子量越大检索的结果越不准确;理论上图谱的峰越多越好,要是都能匹配上那么蛋白的确定程度就更高,相反就越低;一般至少要拿到4个肽段。 Q:如何理解这些片段峰值大小意义,越高(纵坐标值大)越精确吗?以及这些酶解片段的数量及峰值一般应达到什么标准才算比较好?? A:片段峰横坐标的大小的意义是酶解下来的肽段的质量大小,纵坐标表示的收集的该肽段的相对的信号的强度,左边是相对的,右边是绝对的,绝对的越高,抗干扰的能力越好,质谱的精确度由仪器来决定的。我们的仪器的精确度在10ppm以内。 Q:图谱上肽段多于8条,为什么选这8条? A:至于提交检索的肽段的数量是根据肽段的信号强度来选取的,同时在软件处理的过程中会过滤一部分峰, 如胰酶的自解峰等; Q:数据库检索报告中m/zsubmitted,MH+matched两项是什么意思? A:m/z submitted 的意思是您提交给数据库的m/z值(因为质谱仪用m/z来分离样品的), MH+matched指的是与你提交数值相匹配数值,因为在样品在离子化过程中从基质中得到一个质子,所以它会加一个H Q:这两项的分子量和你们的图谱上相应分子量不一致。 A:因为在用图谱数据在数据库检索之前需要通过一个数据的校正和处理,所以图谱上的值与提交检索的值有区别图谱中的峰值是经过一个软件处理后的结果,主要是经同位素峰的合并图谱上的结果会不一至的,例如在你的图上读到的是1519.402,在看图的时候把它给放大处理(只有我这里的图谱处理的软件才能看到),就会发现存在1518.402、1520.402、1521.402、1522.402等相差1的质谱峰,这是由于在天然界中好多物质都存在同位素如O16、O17、O18等,所以在提交给数据库之前会用一个类似于碳水化合物的通式进行校正,所以图谱上读到的数可能会与提交的相差1,还在处理的过程的设置也会影响给出的峰值,但应该在0.1Da以内的;同时在还会进行胰酶自解峰的扣除和空白对照峰的扣除。
我是新手,还没入门,想请教下大家有没有过质谱测蛋白的?大家都是用哪种质谱来测得蛋白,有哪些网站或者书籍之类的推荐学习吗?
请问,我在做蛋白质谱的过程中,酶切膜蛋白时,总有一些序列cover不到(哪怕胶内酶解PSM很高时,也没有改善)。请教有没有大佬传授一些经验,谢谢







 我要推广仪器
我要推广仪器
 下载APP
下载APP