维权声明:本文为012304原创作品,本作者与仪器信息网是该作品合法使用者,该作品暂不对外授权转载。其他任何网站、组织、单位或个人等将该作品在本站以外的任何媒体任何形式出现的,均属侵权违法行为,我们将追究法律责任。本实验主要考察实验过程中时间、光照、以及温度对不稳定药物在样本基质中的变化;从而使检测得到的数据结果更加的可靠;本实验以己烯雌酚为目标药物,鸡肉、鸡肝为样本基质;进行验证;实验基础样本种类:鸡肉、鸡肝药物类型:己烯雌酚检测手段:酶联免疫试剂盒检测方法检测限:0.5ppb药物浓度:空白添加3ppb 药物环境条件实验室温度:15-20度 湿度:20-30%样本添加方式:将一大份样本分为两份,将药物溶解后以喷雾的行洒在已经匀浆的样本中;进行多次混匀,并检测该样本和等条件下没有添加的另外半份样本(除了没有添加药物外其他条件完全相同);实验设置条件设置如下:避光 太阳光直射 37度温箱 正常条件下2小时 1小时 1小时 30min6小时 2小时 2小时 30min1天 3小时 3小时 30min2天 4小时 4小时 30min试剂/药品(以下药品均为分析纯级别)乙腈、丙酮、三氯甲烷、磷酸、氢氧化钠(分析纯),去离子水前处理方法鸡肉样本的处理过程称取2+-0.05g样本到40ml塑料离心管中,加入6ml乙腈-丙酮(80:20),振摇10min,离心后取3ml吹干,取3ml到玻璃试管中,于40度水浴氮气吹干,加入0.5ml三氯甲烷涡动溶解后,再加入2ml M氢氧化钠溶液,涡动30s,离心后去上层1ml,加入200ul 6M磷酸,混合后加入6ml乙腈,振荡5min,离心后取全部上层吹干,并加入1ml溶解进行溶解;鸡肝的前处理处理过程称取2+-0.05g样本到40ml塑料离心管中,加入6ml乙腈-丙酮(80:20),振摇10min,离心后取3ml吹干,取3ml到玻璃试管中,于40度水浴氮气吹干,加入0.5ml三氯甲烷涡动溶解后,再加入2ml M氢氧化钠溶液,涡动30s,离心后去上层1ml,加入200ul 6M磷酸,混合后加入6ml乙腈,振荡5min,离心后取全部上层吹干,并加入2ml溶解进行溶解;以下是鸡肉样本的数据闭光放置时间 2小时 6小时 1天 2天空白值 0.21 0.16 0.27 0.17检测值 2.93 2.80 2.71 2.45回收率 98% 93% 90% 82%37度时间 1小时 2小时 3小时 4小时空白值 0.20 0.15 0.24 0.21检测值 2.96 2.46 2.21 1.81回收率 99% 82% 74% 64%阳光照射时间 1小时 2小时 3小时 4小时空白值 0.14 0.19 0.17 0.16检测值 2.81 2.31 1.92 1.74回收率 94% 77% 64% 58%正常条件下 30min空白值 0.13检测值 2.89回收率 96%鸡肝的数据如下闭光放置时间 2小时 6小时 1天 2

http://ng1.17img.cn/bbsfiles/images/2012/01/201201190749_346306_1643453_3.jpgFISH样本制备到发单过程样本的制备1. 1000转/分离心悬液5分钟,用1ml新的固定液重新悬浮细胞。4℃保存固定的样本30分钟以上,直至FISH检测前。若要长期保存,-20℃保存在固定液中2.直接滴加细胞悬液至1-2片预冷的玻片上,样本的老化1. 将样本片子放入2×SSC 37℃1小时2. 从70%乙醇中取出,依次放入85%、100%乙醇中重复以上步骤样本DNA的变性1.将湿润的杂交盒放入37℃孵箱内预热至37℃2. 染色缸中加入变性溶液,73±1℃水浴30分钟以上。3. 用镊子拿出片子立刻放入室温的70%乙醇洗液中5. 从70%的乙醇中拿出片子,依次放入85%、100%乙醇中重复上述步骤在加入探针溶液前将片子加热至45-50℃2分钟探针的预备1. 让探针加热至室温,降低探针的粘度,使用合适的移液管2. 振荡混合。用微型离心机将内容物离心([color=#3
请教各位,我在看文献资料是,总会看到阳性样本(样品)和阴性样本(样品),这两个分别指的是什么呢?谢谢!
公司最新样本已印出,综合样本里面有各种国产和进口(韩国英麟、大韩仪器、赛多利斯、梅特勒等),还有韩国英麟的小样本,如需要请与本公司联系索取,有电子版。
样品法A(%)法B(%)样10.25660.2477样20.28890.2786样30.45010.4334样40.42110.4025样50.21480.2061样60.46620.4433请问上面的6个样本,分别用两种方法测定某物质含量,怎样判断B方法与A方法一样能准确测定?在EXCEL中能操作吗?应该是多样本的显著性分析吧?分析化学书上都是单样本的显著分析。t检验?好像都是同一样本的哦。
各位,领导让我做产品对比,电话打到WTW中国技术服务中心后,让我打到他的代理公司,可代理公司不给样本,难道不买就不能看吗?要样本怎么这么难啊。谁有在线COD、氨氮、总磷总氮、五参的样本啊,贡献一下吧。
请大家看看我的加标回收率实验做得对不对我要用[url=https://insevent.instrument.com.cn/t/yp][color=#3333ff]ICP-MS[/color][/url]分析全血中的某元素A,我要做加标回收率看方法的准确度。采用低、中、高(分别为5ug/l、10ug/l、20ug/l)三种浓度的加标实验。具体做法是:用已知样品A浓度(曾经测得4.8ug/l、9.8ug/l、18.8ug/l)的全血三份,把浓度为4.8ug/l的全血平行做两份,一份消解-定容-测量以获得样本测定值,一份加标-消解-定容-测定,加标体积为样本体积的1%,加标浓度为5ug/l,然后计算。另外两个浓度也这样做。这样对吗?每个样本做几次,还是每个浓度的样本需要几份?还是每个样本都加高中低浓度的标液?有些文献说做标准曲线,怎么做?
能实时监控样本的当前状态,大家有没有好点的软件推荐
[font=宋体][font=宋体]奇异样本([/font][font=Times New Roman]outlier[/font][font=宋体])有时也称为异常值、不规则点、离群点或界外点,至今没有严格的定义,一般是指那些落在总体之外的样本向量。[/font][/font]
用原子荧光做汞,样本加硝酸和抗坏血酸处理之后,放置2小时左右,个别样本会出现红色物质,且管壁上出现大量气泡,想知道是什么原因?[img]https://ng1.17img.cn/bbsfiles/images/2023/09/202309181529133467_9747_5055194_3.png[/img][img]https://ng1.17img.cn/bbsfiles/images/2023/09/202309181529133897_6176_5055194_3.png[/img][img]https://ng1.17img.cn/bbsfiles/images/2023/09/202309181529133663_3701_5055194_3.png[/img][img]https://ng1.17img.cn/bbsfiles/images/2023/09/202309181529132719_2006_5055194_3.png[/img][img]https://ng1.17img.cn/bbsfiles/images/2023/09/202309181529135099_5728_5055194_3.png[/img]
问一下各位,忘记加qc样本的数据可以用不?就是混合样
[font=宋体][font=宋体]相较于传统分析化学方法,结合化学计量学的[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]分析更容易出现过拟合现象。因此对化学计量模型的验证尤为重要。在建模之前通常需要将采集的样本光谱和参考值分为校正集([/font][font=Times New Roman]calibrationset[/font][/font][font='Times New Roman'][font=宋体])[/font][/font][font=宋体][font=宋体]和验证集([/font][font=Times New Roman]validationset[/font][font=宋体])。前者主要用于建立多元校正或化学模式识别模型,后者用来验证所建立模型的预测性能。通常校正集和验证集中样本个数的划分比例介于[/font][font=Times New Roman]0[/font][/font][font='Times New Roman'].5~0.8[/font][font=宋体]之间(两者的样本数量具体根据样本、模型的复杂程度来定)。常见的样本分组方法包括:随机算法、[/font][font='Times New Roman']Kennard-Stone [font=宋体]([/font][/font][font=宋体][font=Times New Roman]KS[/font][font=宋体])算法、光谱[/font][font=Times New Roman]-[/font][font=宋体]理化值共生距离算法([/font][font=Times New Roman]S[/font][/font][font='Times New Roman']ample set [/font][font=宋体][font=Times New Roman]p[/font][/font][font='Times New Roman']artitioning based on joint x[/font][font=宋体][font=Times New Roman]-[/font][/font][font='Times New Roman']y distances[/font][font=宋体][font=Times New Roman], SPXY[/font][/font][font='Times New Roman'][font=宋体])[/font][/font][font=宋体]等。[/font][b][b][font=宋体]一、[/font][font=宋体]随机分组方法[/font][/b][/b][font=宋体]随机分组方法是从数据集中随机选择一部分样本作为校正集,其余样本作为预测集。[/font][font=宋体]其中,随机分组算法的选择过程具有不确定性,在样品量较少或者建模效果波动较大时难以建立高效的模型。[/font][font=宋体]随机分组不能保证每次选择的校正集样本都具有代表性,因而在验证新提出方法的性能时,为了保证模型性能不受分组方法的干扰,常采用多次随机分组方法进行综合评价。即将数据多次采用随机分组的方法进行分组,对校正集多次建模,计算模型预测结果的平均值。该预测结果不受数据分组的影响,能较好体现模型的性能。[/font][b][b][font=宋体]二、[/font][font=宋体]KS分组方法[/font][/b][/b][font=宋体][font=Times New Roman]KS[/font][font=宋体]算法由[/font][/font][font='Times New Roman']Kennard[font=宋体]和[/font][font=Times New Roman]Stone[/font][font=宋体]提出[/font][/font][sup][font=宋体][font=Times New Roman][[/font][/font][/sup][sup][font='Times New Roman']2[/font][/sup][sup][font=宋体][font=Times New Roman]][/font][/font][/sup][font=宋体],是一种基于光谱距离迭代选择样本的方法,旨在选择出覆盖范围广,且均匀分布的样本集。首先,选择一个初始样本,之后每一步都选择与已选样本光谱距离(通常为欧氏距离或者马氏距离)最远的一个样本,直到选择出的样本达到预设的数量为止。[/font][b][b][font=宋体]三、[/font][font=宋体]SPXY分组方法[/font][/b][/b][font=宋体][font=Times New Roman]KS[/font][font=宋体]算法仅考虑了光谱的信息,没有考虑参考值的影响。当待测组分含量较低时,若光谱特征不显著,采用[/font][font=Times New Roman]KS[/font][font=宋体]方法可能不会得到满意的校正集样本。[/font][font=Times New Roman]Galvao[/font][font=宋体]等[/font][/font][sup][font='Times New Roman'][3][/font][/sup][font=宋体][font=宋体]在[/font][font=Times New Roman]KS[/font][font=宋体]方法的基础上提出了光谱[/font][font=Times New Roman]-[/font][font=宋体]理化值共生距离算法([/font][font=Times New Roman]SPXY[/font][font=宋体])。该方法兼顾参考值和光谱距离,从而保证选择的样本的光谱和参考值都覆盖较大的范围并且均匀分布。[/font][font=Times New Roman]SPXY[/font][font=宋体]方法的逐步选择过程与[/font][font=Times New Roman]KS[/font][font=宋体]方法相同,只是在计算样本[/font][/font][i][font=宋体][font=Times New Roman]i[/font][/font][/i][font=宋体]和样品[/font][i][font=宋体][font=Times New Roman]j[/font][/font][/i][font=宋体][font=宋体]之间的距离时,采用了同时考虑光谱[/font][font=Times New Roman]x[/font][font=宋体]和目标参考值[/font][font=Times New Roman]y[/font][font=宋体]的新的距离定义[/font][font=Times New Roman]d[/font][/font][sub][font='Times New Roman']xy[/font][/sub][font=宋体][font=Times New Roman]([/font][/font][i][font='Times New Roman']i[/font][/i][font=宋体][font=Times New Roman],[/font][/font][i][font='Times New Roman']j[/font][/i][font=宋体][font=Times New Roman])[/font][font=宋体]。[/font][/font][align=center][i][font='Times New Roman']d[/font][sub][font='Times New Roman']xy[/font][/sub][/i][font='Times New Roman']([/font][i][font='Times New Roman']i[/font][/i][font='Times New Roman'],[/font][i][font='Times New Roman']j[/font][/i][font='Times New Roman'])[font=宋体]=[/font][/font][img=,262,49]https://ng1.17img.cn/bbsfiles/images/2024/06/202406281001238984_1952_4070220_3.png!w262x49.jpg[/img][font='Times New Roman'][font=宋体],[/font][/font][i][font='Times New Roman']i[/font][/i][font='Times New Roman'][font=宋体],[/font][/font][i][font='Times New Roman']j[/font][/i][font=宋体]∈[/font][font='Times New Roman'][1,...,[/font][i][font='Times New Roman']z[/font][/i][font='Times New Roman']][/font][font=宋体] [font=Times New Roman](5-1)[/font][/font][/align][font=宋体]式中,[/font][font='Times New Roman']d[/font][sub][font='Times New Roman']x[/font][/sub][font='Times New Roman']([/font][i][font='Times New Roman']i[/font][/i][font='Times New Roman'],[/font][i][font='Times New Roman']j[/font][/i][font='Times New Roman'])[/font][font=宋体][font=宋体]是以光谱[/font][font=Times New Roman]x[/font][font=宋体]为特征参数计算的样本[/font][/font][i][font=宋体][font=Times New Roman]i[/font][/font][/i][font=宋体]和[/font][i][font=宋体][font=Times New Roman]j[/font][/font][/i][font=宋体]之间的欧式距离,[/font][font='Times New Roman']d[/font][sub][font='Times New Roman']y[/font][/sub][font='Times New Roman']([/font][i][font='Times New Roman']i[/font][/i][font='Times New Roman'],[/font][i][font='Times New Roman']j[/font][/i][font='Times New Roman'])[/font][font=宋体]是以目标参考值[/font][i][font=宋体][font=Times New Roman]y[/font][/font][/i][font=宋体]为特征参数计算的样本[/font][i][font=宋体][font=Times New Roman]i[/font][/font][/i][font=宋体]和[/font][i][font=宋体][font=Times New Roman]j[/font][/font][/i][font=宋体]之间的距离,[/font][i][font='Times New Roman']z[/font][/i][font=宋体]是样品的总数目。[/font][font='Times New Roman'][font=宋体]为了对[/font]x[font=宋体]和[/font][font=Times New Roman]y[/font][font=宋体]空间中的样本分布赋予同等重要性,距离[/font][font=Times New Roman]d[/font][/font][sub][font='Times New Roman']x[/font][/sub][font='Times New Roman']([/font][i][font='Times New Roman']i[/font][/i][font='Times New Roman'],[/font][i][font='Times New Roman']j[/font][/i][font='Times New Roman'])[font=宋体]和[/font][font=Times New Roman]d[/font][/font][sub][font='Times New Roman']y[/font][/sub][font='Times New Roman']([/font][i][font=宋体][font=Times New Roman]i[/font][/font][/i][font='Times New Roman'],[/font][i][font=宋体][font=Times New Roman]j[/font][/font][/i][font='Times New Roman'])[font=宋体]除以它们在数据集中的最大值[/font][/font][font=宋体]进行标准化处理。[/font][b][b][font=宋体]四、最优[/font][font=宋体]K[/font][font=宋体]相异性方法[/font][/b][/b][font=宋体][font=宋体]在选择校正样本时,需要同时考虑样本的代表性和多样化,所谓的代表性是所选样本要尽可能反映整个数据集中所有样本的属性,而多样化是指所选样本之间的差异应尽可能大,彼此容易区分。最优[/font][font=Times New Roman]K[/font][font=宋体]相异性方法([/font][font=Times New Roman]Optimizable K-[/font][/font][font='Times New Roman']d[/font][font=宋体][font=Times New Roman]issimilarity [/font][/font][font='Times New Roman']s[/font][font=宋体][font=Times New Roman]election[/font][font=宋体],[/font][font=Times New Roman]OptiSim[/font][font=宋体])是一种能选择既有代表性又兼顾多样化样本的方法[/font][/font][sup][font='Times New Roman'][4][/font][/sup][font=宋体][font=宋体]。最优[/font][font=Times New Roman]K[/font][font=宋体]相异性算法涉及三个参数:[/font][font=Times New Roman]K[/font][font=宋体]定义为每一次迭代中子样本集的大小;[/font][font=Times New Roman]R[/font][font=宋体]定义为一个有效的候选样本与任何一个已经选定的样本之间所允许的最小相似性;[/font][font=Times New Roman]M[/font][font=宋体]为所选的代表性子集样本的总数目。通过[/font][font=Times New Roman]K[/font][font=宋体]值可控制所选样本代表性和多样性之间的平衡,低的[/font][font=Times New Roman]K[/font][font=宋体]值能选出更具代表性的样本,较大[/font][font=Times New Roman]K[/font][font=宋体]值能选出更多样化的样本。[/font][/font]
[font=宋体][/font][font=宋体][/font][size=5][b][font=黑体]样本前处理在样本分析中的地位[/font][/b][/size][size=3][font=宋体]在分析化学发展的过程中,样本前处理技术一直没有受到重视,相对与现代分析技术的快速发展,样本前处理技术以及仪器的发展滞后并制约了分析化学的发展,在过去的很多年中,分析化学的发展集中在研究分析方法的本身:如何提高灵敏度、选择性以及分析速度;如何应用物理、化学、生物学等方面的理论来发展新的分析方法与技术,以满足新技术对分析化学提出的新目标与高要求;如何采用新技术的成果改进分析仪器的性能、速度、以及自动化的程度。长期以来忽视对前处理方法与技术的研究,是样本前处理技术成为制约分析化学发展的瓶颈。[/font][/size][size=3][/size][size=3][font=宋体]现代分析化学所面临的样本性质的复杂程度是前所未有的,分析的对象不仅包括气、液、固相中的所有物质,而且往往以多相形式存在;其组成不但复杂,而且测定的时往往相互干扰;同时被检测物的浓度要求越来越低,稳定性随时变化,因而给分析带来了一系列困难,尤其是各种环境与生物样本采集后直接进行的可能性很小,一般都要经过样本制备与前处理以后才能测定[/font][/size][size=3][/size][size=5][b][font=黑体]样本前处理的目的[/font][/b][/size][size=3][font=Times New Roman] [/font][/size][size=3][font=宋体]一个完整的样本分析过程,从采样开始到写出分析报告,大致可以分为[/font][/size][size=3][font=Times New Roman]4[/font][/size][size=3][font=宋体]个步骤:[/font][/size][size=3][font=Times New Roman]1[/font][/size][size=3][font=宋体]、样本采集、样本前处理、分析检测;数据处理与报告结果。统计结果表明,这个步骤中样本前处理占用了相当多的时间,有的甚至可以占有全程时间的[/font][/size][size=3][font=Times New Roman]70%[/font][/size][size=3][font=宋体],甚至更多;比样本本身的检测分析多近一半的时间。因此近些年来样本前处理方法和技术的研究引起了分析学家的关注。各种新技术与新方法的探索与研究已经成为当代分析化学的重要课题与发展方向之一,快速、简便、自动化的前处理技术不仅省时、省力,而且可以减少由于不同人员操作以及样本多次转移带来的误差,同时可以避免使用大量有机溶剂并减少对环境的污染,样本前处理技术的深入研究必将对分析化学的发展起到积极的推动作用。[/font][/size][size=3][/size]
t检验中的“平均值的成对二样本分析”、“双样本等方差假设”、“双样本异方差假设”各自应用范围是什么?
一个废弃的化工厂需要重新整修,有些土壤已经被不同的化学原料污染过。而且周围有居民区。工厂面积12000平方米。图纸上面的比例是1:500.请教各位大侠们,1.我应该确定多少个样本。图纸上,格子图的距离应该多少? 2.存在污染物的地方,我应该如何取样本? 3.如何确定混合样本,以及参照样本。参照样本一般取多少?谢谢!!
[font=宋体]随着样本数量的增多,单个样本增加引起的模型提升效果越来越小。当样本数量超过一定的限度后,建模算法可能成为限制模型进一步优化的瓶颈,此时选择更加复杂的算法可能获得进一步的模型提升。但是样本量增加,可能增加实验成本和计算成本,需要综合考虑成本和收益,以确定合适的建模样本。[/font]
[font=宋体][font=宋体]代表性样本是指能够覆盖待测样本中关键特征的样本,通常是拓展模型预测范围、覆盖检测体系中各种变动因素的样本。可以采用[/font][font=Times New Roman]KS[/font][font=宋体]、[/font][font=Times New Roman]SPXY[/font][font=宋体]等方法选择,每种方法的原理具体参考本章第[/font][font=Times New Roman]2[/font][font=宋体]节。代表性样本选择方法主要通过方法的原理、观察法和建模效果来选择。观察法是对分组后的校正集和预测集样本进行主成分分析([/font][font=Times New Roman]P[/font][/font][font='Times New Roman']CA[/font][font=宋体]),观察主成分空间中校正集和预测集样本的分布情况来选择更合理的样本选取方法。根据建模效果先采用数据分组方法将总体数据进行分组,然后采用一种合适的建模方法建立模型,根据模型预测的误差来选择合适的代表性样本选择方法。[/font]
目前,我国关于蔬菜水果农药残留检测样本取样量的规定主要有两个标准,分别为NY/T789-2004《农药残留分析样本的选取方法》和GB/T8855-2008《新鲜水果和水果取样方法》。那么要取样时要用这两个标准,还是用其中一个标准就行。
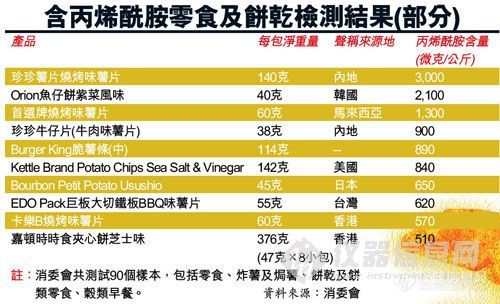
薯片、炸薯条、朱古力饼等零食美味可口,但原来含有不同程度的致癌物丙烯酰胺。香港消费者委员会及食安中心测试香港90款香脆零食、饼干、谷类早餐样本,发现89个样本含丙烯酰胺,愈脆薄含量愈高,当中珍珍薯片烧烤味被验出每公斤含3,000微克丙烯酰胺,含量最高。专家认为,市民每天不应进食超过1、2公斤油炸食物,或选吃粗切、以大米制的零食,避免进食土豆、小麦或粟米制的零食。 http://ng1.17img.cn/bbsfiles/images/2010/12/201012171404_267647_1641058_3.jpg 据香港文汇报报道,消委会表示,含丰富碳水化合物、低蛋白质的植物性食物,例如谷类食物、咖啡及土豆等,经摄氏120度或以上高温加工处理时,会生成一种无味的白色结晶体丙烯酰胺(acrylamide)。世卫联合食物添加剂专家委员会(JECFA)动物实验证实,丙烯酰胺会增加动物的甲状腺、肾上腺、乳腺、睾丸及中枢神经等器官组织出现肿瘤的比率。国际癌症研究机构(IARC)把丙烯酰胺分类为可能令人患癌的物质。 消委会与食安中心调查香港市面90款食物样本,包括零食、炸薯及饼类零食、谷类早餐,结果发现大部分样本含丙烯酰胺。薯片含量普遍偏高,珍珍薯片烧烤味的含量每公斤达3,000微克,是所有样本中最高,仅由木薯淀粉制成的明辉牌印尼虾片,检测不到该物质。在快餐店抽验的炸薯小食,含量由每公斤15微克至890微克。饼干及饼类零食样本,介乎每公斤32微克至2,100微克。谷类早餐的含量相对较低,由每公斤29微克至460微克。 食安中心(风险评估及传达)首席医生蔡敏欣昨表示,国际及香港现时未有法例规管食物中的丙烯酰胺含量,虽然该物质可以排出体外,但人体接触到已生成风险。食安中心根据香港市民食物消费量调查的数据计算,认为香港成年人对丙烯酰胺摄取情况值得关注,建议市民尽量少吃经高温加工的植物性食物,不宜过度烹煮食物,包括加热时间太长或温度过高,并保持均衡饮食,多吃蔬果。 食安中心已草拟《减低食品中丙烯酰胺的业界指引》,建议制造商改进配方及加工技术,降低该物质的含量,“是否低温保存、烹煮温度、时间及食材质量都有影响。”例如在高温加工植物性食物时,应该选用较不容易生成丙烯酰胺的食物品种,例如大米、燕麦或黑麦;油炸、烧烤或烘焙容易生成丙烯酰胺,需控制温度及时间。 有医生表示,高温油炸食物愈薄愈脆,丙烯酰胺含量愈高,该物质主要于食物表面形成,粗切土豆制品的含量会较细切土豆制品为低。香港中文大学生物化学系副教授陈竟明认为,市民毋须过于惊慌,“根据测试数据,每人每天不应进食超过1、2公斤油炸食物。”有关食品引发心血管、肥胖的风险,亦相对偏高。
[url=https://insevent.instrument.com.cn/t/bp][color=#3333ff]GC-MS[/color][/url]用内标法检测样本时,由于样本量大,需要清洗离子源,所以样本需要分多次检测,那么在清洗离子源前后检测点样本是否还具有可比性
急寻岛津LC-10A液相样本/电子样本哪位有的请给我邮件发一份感激不尽cnhplc@yahoo.cn
最近做的植物样本多,遇到这么几个问题,跟论坛里面的大佬请教:1.植物样本甲醇水提取后,离心,上清普遍是颜色偏深,色素太多,对这种植物提取样本怎么怎么净化能有效去除色素?有那些下方案?望大佬指点,目前做过的萃取、过SPE柱(C18,和GCB)效果都不是太理想(过C18的还好点)。2.有些植物样本经过上述处理后经0.22um滤膜过滤后,-80℃冷冻,复溶,会有很多絮状物产生,这种絮状物可能会是什么?为什么冷冻复溶后会出现呢?(手机拍摄照片不清晰,看不清楚)希望论坛里面做前处理的大佬指点下,谢谢[img]https://simg.instrument.com.cn/bbs/images/default/em09509.gif[/img]
样本自动进入废液
一. 取材和编号/标签部分 在本环节进行组织和血液的取材,并制作条形码标签,将样本进行分装。1. 取材单:手术医生根据临床病例情况在术前一日通知样本库次日取样本,同时在医嘱中注明需要抽取血样数量、种类。样本库根据次日样本情况预先准备样本提取单,并预先定义好流水编号。样本提取单上的信息可包含并不仅限于以下内容中的一部分:A. 个体流水编号B. 个体基本信息:如住院号,病理号,手术科室,手术医生,病人姓名,性别等C. 样本特征信息:如脏器名称,样本类型(肿瘤,癌旁,正常,淋巴结,息肉,囊壁),样本性质(原发/复发/转移)等D. 样本采集信息:如样本份量,体积,分管数,术前/术后等E. 诊断信息:如临床诊断,病理诊断,分化程度,UICC 分期,ICD10/ICDO-3 代码等F. 治疗信息:如放疗,化疗,手术等G. 生物安全信息:有/无传染性H. 时间信息:采集时间,样本离体时间,低温时间,等I. 工作人员信息:取材员,记录员等J. 以及备注信息。2. 组织样本:从手术室收集组织样本,填写取材表。在组织库冻存管理软件上登记部分栏目,如通过输入住院号码,软件从HIS 中自动调入该病例的个体信息(基本信息、临床信息等)。如果输入部分信息,由系统自动生成连续于上次的个体编号,如选择脏器名,样本类型,样本保存方式,以及分管数,软件按照规则生成样本编号,如1012345D19TF1~1012345D19TF4,在对应的样本信息栏中输入各分管的样本采集信息等特性,点击保存将所有信息存入数据库,同时自动在手术室的耐液氮的条形码标签上生成样本条形码信息。将离体的组织样本存入耐液氮冻存管,贴好标签后,在30分钟内浸入液氮。当天样本采集完成后,使用小型液氮转移罐或者冰盒将样本转移到实验室。【组织样本的编号命名1012345D19TF1,代表该1012345 号病收集的D19 脏器的癌旁样本(T肿瘤,P 癌旁,N 正常,L 淋巴结,Y 息肉,C 囊壁)用F 方式(Frozen Tissues/OCT/RNAlater/DNA/Paraffin embedding 等)保存的第一份。】
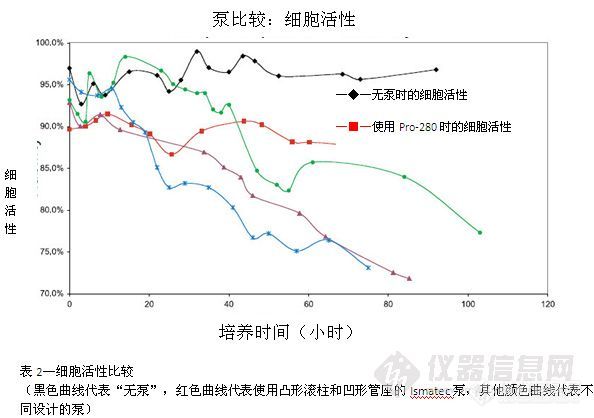
随着全球对生物技术和生物替代燃料开发的日益重视,使用包含生物材料的流体进行的分析工作也越来越多。无论该种分析涉及血细胞计数还是细菌培养(涉及许多其他生命科学应用),它们都有一个共同点,这就是经常需要将生物样本从一个地方转移到另一个地方。有时这种转移可手动完成(例如手持式移液器),但对高通量的需求持续推动着人们开发更加自动化的技术。目前很多研究人员面临的挑战就是,各种泵送技术对细胞物质造成的负面影响:· 往复泵——生命科学分析工作中最常使用的两种往复泵为隔膜泵和柱塞/注射泵。隔膜泵通常由单向阀和一个柔性膜片(安装在驱动电机轴上)组成,该隔膜通过自身“脉冲”动作推动液体在泵内进出。柱塞/注射泵则将正排量活塞或柱塞与某些类型的旋转剪切阀结合,通过活塞或柱塞的移动推动液体移动。这两种类型的往复泵都会带来细胞活性的问题,这是由于细胞会暴露在较强的真空力和剪切力下。这些力量会使细胞破裂,从而大大降低细胞活性以及进行更长期试验的可能性。此外这两种泵送技术还会造成清洁困难,从而导致样本夹带和交叉污染的可能性增加。· 齿轮泵——齿轮泵通过两个(或多个)啮合齿轮的高速旋转进行工作。随着“主动”齿轮和“从动”齿轮在高速旋转时相互接合,流体也在轮齿间向前移动。由于流体在高速转移时会受到物理应力的影响,因此这种泵送方式会为生物样本带来一些问题。例如轮齿经常会剪切细胞物质,从而导致分析样本或液体失效。此外,由于流体会接触泵的机械部分,样本间的交叉污染也难以避免。目前运用日益普遍的一种泵送技术采用了蠕动泵。蠕动泵通过一系列滚柱,很容易地对软壁管道进行压缩和扩展。该种泵送技术具有维持细胞活性和减少样本间交叉污染的多种优势:· 真空力小——蠕动泵通常采用软壁弹性管道。这种管道很容易被压缩,并可以很快恢复原始形状。蠕动泵使用的滚柱能够在管座下旋转的同时完全压缩流路管道。压缩后滚柱继续移动,管道也会重新扩张至原始形状,形成的低真空则可以在下一个滚柱再次压缩管道前将液体拉进管道。管道重复扩张形成的低真空足以移动液体但不会损害细胞物质。· 剪切力小——蠕动泵可保持相当一致的流量(泵的固有脉动效应除外)并避免流体与泵的机械部件直接接触。这两种特性都能将样本可能承受的剪切力减到最小,并帮助增加样本存活率。· 管道压缩点数量最少——由于软壁蠕动管道仅在有限的点完全压缩,大部分管道保持开放,从而降低了生物材料被压缩和损害的可能性。· 仅使用管道流路——蠕动泵的一个独特设计在于只有管道与被转移材料接触,被转移的材料不会接触泵的机械部分。这将使管道能够在用于不同分析工作前进行清洗、灭菌或更换,从而消除了样本间交叉污染的可能性。滚柱和管座设计也是大部分单通道Ismatec®泵的特色,它们通过滚柱在管座上推压管道。目前的很多泵都采用平面滚柱和管座,而大部分Ismatec单通道泵采用凸面滚柱和有一定弧度的凹面管座。Ismatec的滚柱在接触管道时仅会压缩管道中心,生物材料可通过缝隙进入管道壁以避免受到损害或破坏。(见下图1)http://ng1.17img.cn/bbsfiles/images/2017/01/201701191653_630768_1587_3.jpg为对比此种滚柱/管座设计与其他设计而进行的独立研究清楚表明,该种设计可以同时提高细胞浓度(培养期间)和细胞活性。(见下表1和2)http://ng1.17img.cn/bbsfiles/images/2017/10/201105201109396510_01_1587_3.jpghttp://ng1.17img.cn/bbsfiles/images/2017/10/201105201110103059_01_1587_3.jpg蠕动泵也存在需要考虑的一些缺陷,例如泵在工作时经受的压差十分有限。另外管道本身也需要克服一些挑战,例如弹性管道的化学兼容性不够广泛,使用过程中也会发生磨损,从而导致管道在使用期间流量不稳定及/或发生变化。事实上最重要的或许是蠕动泵需要承受脉动,这是其工作过程中的固有现象。脉动流会在离开管道流路时导致液体“喷洒”,另外分析腔内流量的不断变化也会导致实时流量分析无法提供确定的结果。虽然蠕动泵技术的这些局限阻碍了其在一些应用中的使用,但对很多应用—尤其是那些因涉及生物样本而被分类为“生命科学”的应用—蠕动泵是最佳选择。

维权声明:本文为012304原创作品,本作者与仪器信息网是该作品合法使用者,该作品暂不对外授权转载。其他任何网站、组织、单位或个人等将该作品在本站以外的任何媒体任何形式出现的,均属侵权违法行为,我们将追究法律责任。本文是一次动物源食品中残留级检测的样本前处理的过程,本文涵盖了整个过程,以及过程中的很多注意事项,并提带一些相关处理设备和技术,由于准备的不是很充分,所以部分图片没有做收集,总结本文一方面希望对大家能有一定的启发,同时也希望大家多多提意见完善本过程;样本前处理的概念在《样本前处理概述》一文中有较为详细的讲述,本处仅对样本前处理的过程做出讲解一、样本准备1、样本预处理一般的样本不是可以直接开始实验操作的,还有一个样本粉碎或匀浆的过程A, 需匀浆的样本新鲜的肉类、熟食等一般含水量较大的样本固体块状样本需要该项处理,冻存的样本要先解冻再行处理。首先,将其切为小块或小片,然后放入匀浆机匀浆,一般以匀到呈糊状为止,器具按照“样本污染的防止处理”进行处理以后再行下一个样本的处理,处理完的样本要进行编号以后分包保存,B, 需粉碎的样本如饲料、干燥蔬菜等干燥固态块状或颗粒状样本应进行粉碎处理,如果颗粒或块状样本尺寸太大时,预先用锤子等将其敲碎,再用匀浆机或粉碎机将样本处理至粉状,器具按照“样本污染的防止处理”进行处理以后再行下一个样本的处理C, 不需要处理的样本如牛奶、蜂蜜、尿样等不需要进行该项处理。部分尿样在保存前可以进行离心去杂处理,但是不是必须要求D, 特殊样本的处理对于某些非常特殊的样本会针对它进行较为特殊的处理,如毛发在剁碎以后经过研钵研细后保存,又如葡萄干,我们可以用定量的比例加水使它发涨软化以后更容易进行匀浆处理等2、样本编号以及登记预处理完的样本需要有一个有规律、唯一的编号;一般的编号规则如下A、 采集于多个点的样本必须分别编号B、 单个分量大于2KG的样本可分别编号C、 不同种类的样本必须分别编号D、 不同批次的样本必须分别编号E、 样本的编号应该涵盖采购时间、采购地点、样本种类等相关信息,一般附带编号规则(本处不再敷述)登记的要求登记主要的目的是满足库存管理以及溯源的要求http://ng1.17img.cn/bbsfiles/images/2010/12/201012301023_270738_1600026_3.jpg 鸡大胸3、样本储存(略)二,样本前处理操作(以肉类为例子)A,各种溶液配制在实验开始前按照实验的要求或设计方案要求,配制出各种实验中需要的溶液,实验室现有的的溶液也应考虑溶液的配制日期以及有效期,过期的溶液按照本组制定的《溶剂/溶液的管理办法》进行处理。不是很特别要求情况下不要再实验的过程中配制溶液;B,样本称量/量取前的处理有的样本的是冷冻保存,有的样本在较低温度时粘度较大在样本且变得不均一,它们称量/量取前必须解冻或加热,夏天采用放置室内解冻即可,冬天可以是防水的温水浴解冻,或24/37度温箱解冻,也可以采用暖气片解冻,但是无论是什么样的方式在解冻完成以后必须立即转到室温环境中来,以免变质,值得一提的是某些药物的实验样本的解冻方式必须使用室温解冻,其他的解冻方式均对结果都有很大的影响http://ng1.17img.cn/bbsfiles/images/2010/12/201012301024_270739_1600026_3.jpg 图片中显示的是匀浆后并解冻的袋装鸡肉和虾肉C,样本称量/量取按照说明书规定的量进行称量/量取,对于外来复核的样本称量/量取应更加的精确,当称量的量很少的情况下可由一般的天平转到分析天平去称量,天平也要按时进行校正,部分样本采用量取的方式取样,在量取前必须保证量取容器的准确行;以保证样本量准确 http://ng1.17img.cn/bbsfiles/images/2010/12/201012301024_270740_1600026_3.jpg 天平是实验室必须配备的工具之一
现在实验室想推样本条形码管理大家有做吗?分享一下
大家好:我是一个新手,过几天我准备用显微激光拉曼光谱仪来做大鼠血清的代谢组学研究,有个疑问向大家请教: 样本(血清)在仪器上用什么来放置?载玻片可以吗?有人说要用石英毛细管,请问什么样的石英毛细管呢?为什么要用它呢?如果来消除基底对样本图像的干扰?
(二)泌尿系统感染病原菌的快速检测 因泌尿系统感染的中段尿样本中的细菌量相对很高, 中段尿样本也是MALDI-TOF MS直接检测的理想选择[30], 并且常常是单一菌种感染, 避免了MALDI-TOF MS在鉴定混合菌样本的不足[31]。泌尿系统感染是人类常见的感染性疾病, 临床泌尿系统感染最常见的病原菌为大肠埃希菌(70%~95%)、腐生葡萄球菌(5%~10%)以及其它肠杆菌科细菌, 如奇异变形杆菌和肺炎克雷伯菌。有研究表明MALDI-TOF MS对尿液样本中这些细菌的鉴定效率和准确率要优于传统鉴定方法和其他鉴定系统[7, 32, 33]。1.鉴定效能 FERREIRA等[7]选取尿液中细菌大于1× 105 cfu/mL的样本进行直接的MALDI-TOF MS鉴定, 结果显示尿液样本经过差速离心法处理后, 可将91.8%的菌株鉴定到种、92.7%的菌株鉴定到属的水平。 杨溪等[33]使用MALDI-TOF MS技术对临床收集到的1 040份尿液样本进行直接快速检测, 共鉴定出含细菌的样本526份, 其中尿细菌培养菌落数≥ 1× 105 cfu/mL, 培养出1种/2种菌的尿液样本MALDI-TOF MS的直接鉴定率分别为92.7%(430/464)和75%(96/128)。MALDI-TOF MS直接检测法的鉴定结果与尿细菌培养法鉴定出的细菌菌种一致, 符合率为100%。2.与流式细胞术联用 怀疑泌尿系统感染的尿液样本一般经离心后取沉淀直接进行检测, 但考虑到临床上有60%~80%的尿液样本是阴性的, 为了减少分析的时间和人工的工作量, 有学者将MALDI-TOF MS与流式细胞术联用检测, 用流式细胞术筛除细菌数量不足的尿液样本, 而MALDI-TOF MS用来检测筛选结果为阳性的尿液样本, 取得了良好的鉴定效果[34, 35]。MARCH ROSSELLó 等[34]建立了这样一种微生物鉴定程序:先用流式细胞仪进行菌落计数筛查出单一细菌阳性的尿液样本, 然后再进行MALDI-TOF MS检测, 发现细菌数在1× 107 cfu/mL时是足够的细菌浓度, 有87.5%的敏感性, 而细菌数在(1× 105)~(1× 107)cfu/mL之间的样本经过4 h的预增菌, 得到用于分析的足够的细菌数量后, 可以达到91.7%的敏感性。3.细菌含量对鉴定结果的影响 由于中段尿中病原菌数 2.0), 而随着样本中细菌数的降低, 鉴定成功的比例和鉴定分数也在下降, 当菌落数 1× 104 cfu/mL的中段尿样本, 应用MALDI-TOF MS直接检测即可取得满意的鉴定效果。4.中段尿样本直接检测的新方法 DEMARCO等[31]近期描述了一种透析过滤的方法, 通过脱盐、分馏、富集等步骤对100例阳性尿液样本在MALDI-TOF MS分析前进行了预处理, 实验结果表明这种预处理方法能够正确地鉴定阳性尿液样本, 并且正确分类了所有临床相关菌尿症的阴性尿液样本, 包括一组污染的尿液样本和一组临床上无关紧要的定植菌。敏感性和特异性分别是67%和100%。5.中段尿样本直接检测的不足之处 与直接检测培养阳性的血样本一样, 对于含有2种或2种以上细菌感染的中段尿样本, MALDI-TOF MS常常表现为鉴定能力不足[33, 35] 尿液蛋白质如α -防御素[8]会造成鉴定结果不能正确匹配数据库 对酵母菌的鉴定能力也有待于进一步提高 对于核糖体蛋白序列差异很小的菌种也常常不能区分。(三)其它无菌体液 MALDI-TOF MS直接检测和鉴定其它无菌体液样本如脑脊液、胸腹水和关节液等中细菌的报道尚不多。NYVANG HARTMEYER等[37]首次报道了通过直接将脑脊液样本离心取上清直接进行MALDI-TOF MS分析, 肺炎链球菌性脑膜炎可以在30 min内做出诊断, 为后续治疗方案的选择和结果的解释提供了重要的参考依据。SEGAWA等[38]也用同样的方法对一例肺炎克雷伯菌引起的脑膜炎做出了诊断, 但同时也指出在实际应用中能获得的样本量少, 细菌数少可能会限制它的应用。另外, 还可将无菌体液样本转移到血培养瓶中进行孵育, 待报阳后进行检测也是可行的。有研究应用MALDI-TOF MS检测了46份液体, 包括移植养护液、关节液、深部脓疱样本、骨小孔样本用血培养基孵育, 发现44/46(96%)能鉴定到种的水平, 余下的2份被鉴定到属的水平[18]。四、总结与展望 MALDI-TOF MS是一种简单、快速、高通量和高效的微生物鉴定手段, 在临床样本直接检测方面较传统的鉴定方法具有更大的优势, 能显著降低样本检测的周转时间和成本, 但尚存在着一些不足之处, 主要表现在:(1)MALDI-TOF MS在检测和鉴定细菌方面的敏感性还不高, 不能直接鉴定患者血样本中的病原菌(细菌数量太少) (2)对于一些核糖体蛋白差异较小的细菌用其辨别有较大的困难 (3)目前的研究都有各自不同的操作过程, 在样本处理、质谱图采集和分析等方面没有统一的标准, 可能会影响分析结果在实验室内和实验室间的可重复性 (4)标准的鉴定参考图谱数据库尚不够完善, 需要进一步拓展 (5)对一些细胞壁难以破坏的细菌(如革兰阳性菌、酵母菌)和混合菌等的鉴定能力还不够高。但是相信随着更加有效的样本预处理方法、更加严格的检测过程控制和更高分辨率的图像处理技术的实现, MALDI-TOF MS用于直接检测临床样本中的微生物会有更广阔的前景。

采集病原微生物样本应当具备下列条件:http://ng1.17img.cn/bbsfiles/images/2014/12/201412150942_527186_2433088_3.jpg







 我要推广仪器
我要推广仪器
 下载APP
下载APP