用同样的数据,同样的数学处理得到的模型为什么不一样?今天我用一组数据做一个模型,然后把这组数据按一成分含量高低排序,重新做模型,做模型的数学处理方法也是一样的。但是为什么模型不一样呢?两个模型预测另外一组数据,预测结果有的差的还很大? 这是什么原因呢? 大虾们有知道的吗? http://simg.instrument.com.cn/bbs/images/brow/em09501.gif
[size=3][font=宋体]一、医学数学化的发展历史[/font][/size][size=3][font=宋体] [/font][/size][size=3][font=宋体]数学应用于生命科学研究的历史可追溯到17 世纪。1615 年英国医生哈维(Farvey W)在研究心脏时应用流体力学知识和逻辑推理方法推断出血流循环系统的存在,18世纪欧拉利用积分方法计算了血流量问题,这些都是历史上应用数学研究生命科学的突出事例。但是,真正大范围地将数学应用于生命科学与医学研究则出现在20世纪中叶。1935年,Mottram对小白鼠皮肤癌的生长规律进行了研究,认为肿瘤细胞总数N随时间的变化速度与N成正比,并获得了瘤体在较短时间内符合指数生长规律的研究成果。1944 年奥地利著名物理学家薛定谔(Schrodinger E)出版了《生命是什么》(What is life)一书,应用量子力学和统计力学知识描述了生命物质的重要特征。在薛定谔的影响下,沃森(Watson JD)和克里克(Crick FHC)利用当时对蛋白质和核酸所做的射线结晶学研究以及其他与DNA结构有关的研究,于1953年建立了DNA超螺旋结构分子模型,验证了薛定谔的设想。在书中,薛定谔还利用非平衡热力学从宏观的角度解释生命现象,认为生命的基本特征是从环境中取得“负熵”,以使生物系统内的熵始终处于低水平。20多年后,普律高津(Prigogine I)等人提出耗散结构理论,将对生命系统的研究推广到薛定谔预言的领域,为此普律高津于1977年荣获了诺贝尔奖。作为医学领域的最高奖项,诺贝尔医学和生理学奖背后的许多数学影像也许更能说明数学在生命科学中的巨大潜力:英国生理学家、生物物理学家Hodgkin和Huxley建立了神经细胞膜产生动作电位时膜电位变化的模型,揭示了神经电生理的内在机制,因而于1963年共享诺贝尔奖;基于二维雷当变换(Radon transform)创建CT成像理论的美国科学家Cormack AM获得了1979年的诺贝尔奖,丹麦科学家Jerne NK则应用数学原理研究免疫网络理论获得1984年的诺贝尔奖。这些奖项有力地表明现代生命科学的研究离不开数学,数学在其中所起的作用和影响越来越重大,高层次的成果往往有赖于合理的数学模型的建立。[/font][/size][size=3][font=宋体] [/font][/size][size=3][font=宋体]数学不仅推动了人们探索生命世界的步伐,事实上两者结合已经产生了多个十分活跃的学科。1901年Peanson 创建生物统计学后,概率论与数理统计方法在医学上得到了非常广泛的应用,如目前常用的显著性检验、回归分析、方差分析、最大似然模型、决策树概率分布、微生物检测等,都属于基于统计学原理的数学模型及分析。1931年,Volterra在研究食物链的基础上,应用微分方程组研究生物动态平衡,完成了《生态竞争的数学原理》,开创了生物数学(biomathematics)这一新的分支。近年来,可视人及虚拟人的研究、计算医学(computational medicine/biology)、生物信息学(bioinformatics)、生理组学(Physiome)等新的学科及领域的出现,使数学这一工具在生物医学研究中的作用日益突出。[/font][/size][size=3][font=宋体] [/font][/size][size=3][font=宋体]生物系统是一个动态系统,作为世界上最复杂的系统之一,它具有调节机制复杂、多输入、多输出等特点,而且由于很多变量或参数很难在体测量及控制,仅仅通过实验研究来揭示其间的复杂关系,会非常困难且不易得到一致的结论。建立生物系统的数学模型,有利于获得生物系统的动态与定量变化,帮助阐明生物医学中有关作用机制等基础性问题,同时通过模型及仿真实验不仅可以得到正常状态,还可以获得异常或极端异常状态下的生理变化预测,以及代替一些技术复杂、代价高昂或难以控制和重现的实验,为临床或特定条件下的方案设计提供预测及指导。此外,从伦理学的角度,人们也希望医学研究中能够减少实验动物的数量,减轻临床试验中人体试验对象不必要的痛苦,因此生理系统的仿真与建模在生物医学领域中的研究中日益受到重视。目前,包括呼吸、血压、体温、各种调节系统等,都已建立了相应的数学模型,并进行了相应的模拟实验。针对特定应用的模型,如细胞动力学、药物动力学模型、生物种群生长模型、神经网络、心血管模型、临床计量诊断模型等,也不断呈现并得到应用。在本节下面的内容中,我们将以应用最为成功的模型之一,药物动力学模型为例,说明医用数学模型的建立过程。[/font][/size][size=3][font=宋体] [/font][/size][size=3][font=宋体]二、医用数学模型实例:药物动力学模型[/font][/size][size=3][font=宋体] [/font][/size][size=3][font=宋体]药物动力学(pharmacokinetics)是定量研究药物在生物体内吸收、分布、排泄和代谢等过程的动态变化规律的一门学科。于1937年由Teorell开创,主要内容是应用动力学原理、体外实验数据以及人体生理学知识,结合数学模型,定量研究药物在体内的运转规律,为药物的筛选提供指导。[/font][/size][size=3][font=宋体] [/font][/size][size=3][font=宋体]众所周知,新药研发过程费用昂贵、时间冗长、淘汰率高,大约有90%的候选药物在临床期间被淘汰,主要原因有口服吸收性差、生物利用度低、半衰期过短等等。为提高新药研究效率和安全性、降低药物研发成本,药物动力学模型已为全球各大制药公司应用。传统的新药研发流程中,药物动力学的应用主要在药物研发的中后期,近年来,人们开始在药物研发的早期对其药物动力学特性进行模拟研究,以尽早淘汰药物动力学参数不理想的候选药物,提高研发效率、降低成本。比如药物虚拟筛选(virtual screening)就是指在化合物合成前,先通过计算机模拟预测其药动学相关特性,进行初步筛选。此外,药物动力学模型在研究药物处置及作用机制、治疗药物监测及个体化用药、新药开发等方面也发挥着重要作用。[/font][/size][size=3][font=宋体] [/font][/size][size=3][font=宋体]药物动力学的数学模型包括房室模型、非线性药物动力学模型、生理药物动力学模型、药理药物动力学模型、统计矩模型等。下面以最常用的房室模型,结合前面所述的建模步骤,对药物动力学模型的建模过程进行分析描述。[/font][/size][size=3][font=宋体] [/font][/size][size=3][font=宋体](一)背景和问题表述[/font][/size][size=3][font=宋体] [/font][/size][size=3][font=宋体]药物进入机体后,在随血液输送到各个器官和组织的过程中,不断地被吸收、分布、代谢,最终被排出体外。药物在血液中的浓度,即单位体积血液中药物的含量,称为血药浓度。血药浓度的大小直接影响到药物的疗效。因此,药物动力学研究的主要对象是血药浓度随时间变化的规律——药时曲线,建模目的是建立能反映药物在体内分布的数学模型及参数,并能反映给药方式、给药时间间隔、给药剂量等对分布的影响。[/font][/size][size=3][font=宋体] [/font][/size][size=3][font=宋体](二)模型构建[/font][/size][size=3][font=宋体] [/font][/size][size=3][font=宋体]上述问题属于人体与外界以及人体内部的物质交换问题,研究这类问题最常用的是房室模型。药物动力学的房室分析方法将人的机体看做由不同房室构成的系统,每个房室代表药物在其中分布大致均匀的组织或体腔。如血液及供血丰富的肝、心、肾在特定情况下可视为一个房室,而血供不足的组织如肌肉、皮肤等可视为另一个房室。为了进行严格数学描述,常对模型做如下假设:①房室具有固定容量,且药物在每个房室内的分布是均匀的;②各房室间可进行物质交换,且至少有一个房室可与外环境进行交换;③房室间的物质交换或药物转移服从质量守恒定律,即系统中物质总量的改变等于输入总量与输出总量之差;④线性假设:药物的转移速率与药物浓度成正比。[/font][/size]
本人研究生期间主要做的就是近红外的建模和模型分析,但不知道毕业后找啥工作?
我们知道在近红外的实际应用中,在某一近红外仪(称源机)上建立的校正模型,即便在另外一台与源机相同功能的近红外仪(称为目标机)上使用时,因各仪器测量的光谱有差异,模型不再适用,计算结果偏差很大或根本无法使用,解决这类问题的过程称为模型转移,也称为仪器标准化。众所周知建立近红外校正模型时往往需要测量大量样品的化学值或基础性质作为数据基础,投入大、成本高,因此使用模型转移技术实现模型共享和有效利用非常必要。模型转移可克服样品在不同仪器上的量测信号(或光谱) 间的不一致性,通过信号处理以消除仪器对量测信号的影响 ,不仅使已有模型具有较好的动态适应性,而且可以减少因重复建模造成的人力、物力、财力以及时间的浪费。大家在模型转移过程中遇到过什么问题,或有什么好的经验及建议,欢迎一起讨论。下面的四篇英文文献都是近红外模型转移的一些介绍
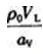
如何建立数学模型讲授人:中国计量科学研究院研究员 倪育才 在测量不确定度评定中,建立数学模型也称为测量模型化,目的是要建立满足测量不确定度评定所要求的数学模型,即建立被测量Y和所有各影响量X间的函数关系,其一般形式可写为: Y=f(X1,X2,…,Xn) 可以说,建立数学模型是进行测量不确定度评定最关键的第一步,也是许多初学者在进行测量不确定度评定时遇到的第一个困难。 《测量不确定度表示指南》(GUM)在摘要介绍测量不确定度评定步骤时,首先就提到要建立数学模型,并说:“The function f should contain everyquantity, including all corrections and correction factors, that can contributea significant component of uncertainty to the result of measurement. ”。其意是数学模型f中应包含所有对测量结果的不确定度有影响的修正值和修正因子。也就是说,数学模型中应包含所有应该考虑的影响量,而每一个影响量将对测量结果贡献一个值得考虑的不确定度分量。因此一个好的数学模型,其中所包含的影响量和此后不确定度评定中所考虑的每一个不确定度分量应该是一一对应的。这样建立起来的数学模型,既能用来计算测量结果,又能用来全面地评定测量结果的不确定度。 要找出每一个影响量与被测量之间的函数关系,往往是很困难的,有时简直不可能得到两者关系的解析表达式。于是许多初学者往往将测量中用来获得被测量的计算公式作为数学模型而列出。例如在各种测量中,最经常采用的方法之一是比较测量。将被测量值y和参考标准所提供的标准量值s相比较,通过测量两者之差Δ可以计算出被测量y。于是在已经发表的各种测量不确定度评定的文章中,经常见到将y=x+Δ作为数学模型的情况。但在进行不确定度评定时,则又往往脱离数学模型而重新考虑各个不确定度分量。这样的数学模型对测量不确定度评定实际上毫无帮助。 在某些特殊情况下(例如某些检测项目)将计算公式作为数学模型可能是允许的,但一般说来不要把数学模型简单地理解为就是计算测量结果的公式,也不要理解为就是测量的基本原理公式。两者之间经常是有区别的。 从原则上说,似乎所有对测量结果有影响的输入量都应该在计算公式中出现,但实际情况却不然。有些输入量虽然对测量结果有影响,但由于信息量的缺乏,在具体测量时无法定量地计算它们对测量结果的影响。也有些输入量由于对测量结果的影响很小而被忽略,故在测量结果的计算公式中也不出现,但它们对测量结果的不确定度的影响却可能是必须考虑的。因此如果仅从计算公式出发来进行不确定度评定,则上述这些不确定度分量就可能被遗漏。当然,在某些特殊情况下如果所有其他不确定度贡献因素的影响都可以忽略不计时,数学模型也可能与计算公式相同。 对于不同的被测量和不同的测量方法,数学模型的具体形式可能差别很大,但实际上都可以用一种比较系统的方式来给出数学模型,或者说可以给出数学模型的通式。 根据测量误差的定义:误差=测量结果-真值。同时误差又可以分为随机误差和系统误差两类,且三者之间的关系为:误差=系统误差+随机误差。于是可以得到: 真值=测量结果-误差 =测量结果-系统误差-随机误差 由于修正值等于负的误差,于是上面的关系式就成为: 真值=测量结果-系统误差-随机误差 =测量结果+系统误差的修正值+随机误差的修正值 实际上,真值就是想得到的被测量的测量结果,于是上式可写成 被测量=测量结果+系统误差的修正值+随机误差的修正值 例1:对于常见的量块比较测量,若ls为标准量块的长度,Δl为测得的两量块的长度差,于是被测量块长度lx的计算公式为: lx=ls+Δl 由于测量时量块的温度通常会偏离标准参考温度20℃,考虑到温度和线膨胀系数对测量结果的影响,计算公式成为: lx=ls+Δl+lsδαθx+lsαsδθ 式中α和θ分别表示线膨胀系数和对标准参考温度20℃的偏差;脚标“s”、“x”分别表示标准量块和被测量块;以及δθ=θs-θx和δα=αs-αx。 考虑到量块测量点可能偏离量块测量面中心点对测量结果的影响,数学模型成为: lx=ls+Δl+lsδαθx+lsαsδθ+δl 将此数学模型和上面给出的通式相比较就可以发现,等式右边的第一、二项ls+Δl即是由测量得到的未修正的测量结果。等式右边的第三、四项lsδαθx+lsαsδθ是对由温度偏差所引入的系统误差的修正值,在本例中这两项的数值十分小而可以忽略,但它们对测量结果不确定度的影响是必须考虑的。等式右边的最后一项δl,是表示由于测量点可能偏离量块中心对测量结果的影响。测量点的偏离对测量结果引入随机误差,因此最后一项实际上是对该随机误差的修正值。由下图可见两者之间的对应关系。http://ng1.17img.cn/bbsfiles/images/2013/10/201310181455_471725_2771427_3.jpg 例2:砝码校准,将被测砝码的质量与具有相同标称值的标准砝码相比较。若被校准砝码和标准砝码的折算质量分别为mx和ms,测得两者的质量差为Δm,于是被校准砝码折算质量mx的计算公式为: mx=ms+Δm 考虑到标准砝码的质量自最近一次校准以来可能产生的漂移Δmd,质量比较仪的偏心度和磁效应的影响Δmc,以及空气浮力对测量结果的影响δB后,其数学模型成为: mx=ms+Δm+δmd+δmc+δB 模型中等式右边的第一、二项为未修正的测量结果。该测量不存在值得考虑的系统误差,也就是说,在数学模型中不存在对系统误差的修正值。等式右边的第三、四、五项为对三项随机误差分量的修正量。与数学模型通式之间的对应关系为:http://ng1.17img.cn/bbsfiles/images/2013/10/201310181455_471726_2771427_3.jpg 在建立数学模型时,未修正的测量结果和系统误差的修正值通常都能比较容易地得到解析形式的数学表达式。惟有随机误差的修正值无法得到其解析形式的表达式。因此只能在数学模型中简单地加上一项,表示对随机误差的修正值。根据随机误差的定义,无限多次测量结果的随机误差的平均值等于零,因此这些项的数学期望为零。也就是说,增加这些修正值后不会对被测量的数值有影响。需要知道的是这些修正值的可能取值范围,通常可以由测量者的经验或
FOSS的定标模型目前是否有成熟的方法可转移成布鲁克的模型?
各位前辈,我是菜鸟,问的问题可能有点弱智,我想咨询一下建立定量模型的问题,在建立定量模型的时候,因样本较少(50多份),我用校正集建立模型,在参数检验的时候,用的是交叉检验,在曲线下面,如果选用Validation检验,R2较小,RMSECV较大,我应该怎样调整我的模型呢,我还想想问一下怎么评价一个模型的好坏,谢谢!
[em09502]各位我现在也需要近红外模型建立及模型转移方面的相关资料,中英文皆可。希望各位同事帮帮忙。万谢万谢!!
[font=宋体][font=宋体]在模型的应用过程中,原料种植环境和工艺条件等的改变或调整都会导致模型不再适用,这时就需要进行模型的更新和维护。模型的更新过程需要收集多个有代表性的新样本,然后,按照常规建模流程添加到原模型校正集中,重新建立模型。如果进行了模型更新则需要重新进行验证过程。对模型更新验证集的要求与新建模型时相同,原有的验证集样本可以用于新模型的验证,但是,必须补充代表新范围或新类型的样本。读者可参考分子光谱多元校正定量分析通则[/font] [font=Times New Roman](GB/T[/font][/font][font='Times New Roman'] 29858[/font][font=宋体][font=Times New Roman]-[/font][/font][font='Times New Roman']2013[/font][font=宋体][font=Times New Roman])[/font][font=宋体]。[/font][/font]
ARIMA模型一般是利用预测变量的过去值、当前值和误差值进行预测。那么如何利用含有自变量的ARIMA模型进行预测?模型阶数的确定方法还是一样的么?模型的参数怎么确定呢?有什么软件可以实现还是继续用eviews?希望高手帮助解答,谢谢。
建立近红外模型之后,怎样验证模型或者评价模型的好坏?
大家好,我想建一个MSF模型,但是看美国人的说明书,看了以后也不知道怎么做.有没有谁做过,能否告诉我一下怎么做.谁有这样方面的资料,最好是有例子.
前几天看到坛里的一则帖子:《从一次曲线看二次曲线》,很简单地表达了自己的看法:相关系数与拟合模型无关。我自己也编写过原子吸收软件,很清楚相关系数是怎样算出来的。根据《数学手册》上的定义,相关系数只与自因变量的统计特性有关,而与所用的拟合模型是没有关系的。不过帖主“冰山”同学很快就贴出某软件的截图反驳了我的观点,贴图上很清楚显示不同的拟合模型有着不同的“相关系数”。这是什么回事呢?要搞清楚这个问题,需要搞清楚一个概念,即何为相关系数?其实相关系数是表示两个变量的相关程度的,一个模型中的自因变量如果存在单调性,如变量A增加则变量B增加(或者减小),以及相反,变量A减小则变量B减小(或增加),我们说两个A与B变量之间存在很强 的相关性。那么相关性的大小有如何计算呢?人们用的是线性相关系数R,它是一个衡量自因变量之间线性关系的一个指标。如果线性相关系数等于1或者-1,说明因变量可以用自变量的一次方程完美表达。因此,线性相关系数和所选择的拟合方程式确实是没有关系的,因为它只对线性方程有意义。那么如何比较两条工作曲线的优劣了。通常,人们会用剩余误差来说明工作曲线的质量。所谓剩余误差,指的是对所有实验样本的因变量与模型估计值之差的平方求和,不过这个数值有些主观,因为它与因变量的取值范围有关。例如,显然,一个取值在1000附近的变量显然比在0.1 附近取之的变量有大得多的误差,因此更“客观的”指标是所谓的“相对剩余误差”,即总剩余误差除以变量变异数(所有实验样本的变量与其算术平均值之差的平方求和)所得之结果。很显然,这个“相对剩余误差”(Qse)越小,拟合质量越好,它与所选择的拟合方程模型是相关的。对于线性拟合模型,Qse^2和R^2之和恰好等于1,所以在线性拟合模型中,常用线性相关系数的平方来说明拟合质量,因为这个值越大(越接近1),拟合质量越好,这很符合人们的思维习惯。对于非线性拟合方程,所谓的相关系数已经不适用了,于是,人们用1减去Qse^2杜撰出一个“相关系数”,更确切地说,这个系数实际上是“模型相关系数”。个人认为,分析软件中的相关系数,还是用“模型相关系数”更加合适。
为什么不少非线性测量模型 可按JJF1059.1评定测量不确定度 JJF1059.1—2012《测量不确定度评定与表示》(以下简称JJF1059.1),第1章范围中就指出本规范主要适用的条件之一:测量模型为线性模型、可以转化为线性的模型或可用线性模型近似的模型。其第4.2.8条也明确指出:本规范主要适用于测量模型为线性函数的情况。如果是非线性函数,应采用泰勒级数展开并忽略其高阶项,将被测量近似为输入量的线性函数,才能进行测量不确定度评定。若测量函数为明显非线性,合成标准不确定度评定中必须包括泰勒级数展开中的主要高级项。 这是因为JJF1059.1评定不确定度依据的不确定度传播律,其必要条件就是当被测量Y是由N个其他量X1,X2,…,XN通过线性测量函数f确定。 但是,在计量学中最典型的测量模型:相对误差 = (示值-真值)/真值,也是非线性测量模型。为什么平时并没有进行泰勒级数展开并忽略其高阶项,将该被测量近似为输入量的线性函数。即并没有将该测量模型进行线性化,能直接据该非线性测量模型正确地评定测量不确定度。而且在JJF1059.1之附录A.2 合成标准不确定度评定方法举例中,给出的四个例子,有两个测量模型是非线性的。JJF1059.1同样也没有进行泰勒级数展开并忽略其高阶项,将其测量模型线性化。 这是因为按JJF1059.1评定测量不确定度,进行合成标准不确定度计算时,对被测量Y与有关的输入量Xi之间函数,求输入量xi的偏导,即求输入量xi的灵敏系数。实际上相当于进行微分近似,即对于非线性函数y对于自变量Δxi = xi2-xi1的增量Δy = y2- y1。用非线性函数y对自变量在xi1处的曲面(或曲线)对于xi的切线所构成的线性函数,进行近似计算。也许这也是导致有的文献说到,不确定度传播律在求灵敏系数很困难时不适用的原因之一。 当然,如果这样的线性的近似,不满足测量任务对测量不确定度评定的要求时。则应对非线性测量函数用泰勒级数展开,并在合成标准不确定度评定中包括泰勒级数展开中的主要高阶项。如果仍不能满足测量任务对测量不确定度评定的要求,则可考虑采用JJF1059.2—2012《用蒙特卡洛法评定测量不确定度》进行不确定度评定。
提 要 通过 1949 年以来在各种出版物上已发表的 27 种生物多样性模型分析发现,大多数多样性模型在理论上是不完善的。例如,被应用最广泛的 Shannon 模型至少有 4 个缺点:①没有考虑物种间生物量的区别;②如果要使用 Shannon 模型,每种物种的个数或每种景观单元的个数不能小于 100;③模型中没有隐含面积参数;④不能够表达多样性的丰富性方面。因此,作者推举了一种理论上完善的综合生物多样性模型,并为了满足实际操作和生物多样性自相似性研究的需要,对其中的一些参数进行了修正。关键词 多样性;丰富性;均一性;理论模型[img]http://www.instrument.com.cn/bbs/images/affix.gif[/img][url=http://www.instrument.com.cn/bbs/download.asp?ID=103383]生物多样性模型研究[/url]
[font=宋体]在[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]分析中,由于两台仪器之间存在差异,使得同一样品在两台仪器上所获得的光谱存在差别,导致一台仪器上所建立的模型不能用于另外一台仪器。仪器间的差异包括不同型号仪器之间的差异和相同型号仪器之间的差[/font][font=宋体]异。对于不同型号的仪器,由于分光原理或采用的检测器等不同,导致波长范围、波长精度及光谱响应会存在差异。对于相同型号的仪器,由于加工工艺水平局限及仪器随时间老化等原因,也会使仪器波长及光谱响应存在差异。在许多应用领域中,建立模型是一项烦琐、重复的工作,浪费人力、物力等资源,而且有些情况下样品可能不易获得或不易保存,存在重新建模困难,需要采用数学方法解决仪器之间的模型适用性问题,称之为模型传递。[/font][font=宋体][font=宋体]模型传递([/font][font=Times New Roman]Model transfer[/font][font=宋体]),也称仪器标准化([/font][font=Times New Roman]Standardization of spectrometric instruments[/font][font=宋体])是指经过数学处理后,使一台仪器上的模型(称为源机,[/font][font=Times New Roman]Master[/font][font=宋体])能够用于另一台仪器(称为目标机,[/font][font=Times New Roman]Slave[/font][font=宋体]),从而减少重新建模所带来的巨大工作量,实现样品和数据资源的共享。在确定仪器间光谱关系时,需要在两台仪器上同时测定某些样品的光谱,这些样品称为传递样品。根据是否需要传递样品,将模型传递分为无标样方法和有标样方法[/font][/font][sup][font=宋体][font=Times New Roman][6][/font][/font][/sup][font=宋体][font=宋体]。无标样方法在模型转移过程中不需要任何传递样品,主要以有限脉冲响应([/font][font=Times New Roman]Finite impulse response[/font][font=宋体],[/font][font=Times New Roman]FIR[/font][font=宋体])算法为代表。有标样方法必须选择一定数量的样品组成标样集,并在源机和目标机上分别测得其信号,从而找出该函数关系。这类算法又分为两种,一是基于预测结果的校正,如斜率[/font][font=Times New Roman]/[/font][font=宋体]偏差([/font][font=Times New Roman]Slope/Bias[/font][font=宋体])算法;二是基于仪器所测光谱信号的校正,如直接校正([/font][font=Times New Roman]Direct standardization[/font][font=宋体],[/font][font=Times New Roman]DS[/font][font=宋体])算法、分段直接校正[/font][/font][font=宋体][font=宋体]([/font][font=Times New Roman]Piecewise direct standardization[/font][font=宋体],[/font][font=Times New Roman]PDS[/font][font=宋体])算法和[/font][font=Times New Roman]Shenk[/font][font=宋体]’[/font][font=Times New Roman]s [/font][font=宋体]算法。此外,光谱空间转换([/font][font=Times New Roman]SST[/font][font=宋体])算法,已证明是一种效果良好的方法,其主要通过主从光谱空间之间的转换消除测量条件变化或仪器引起的光谱差异。[/font][/font]
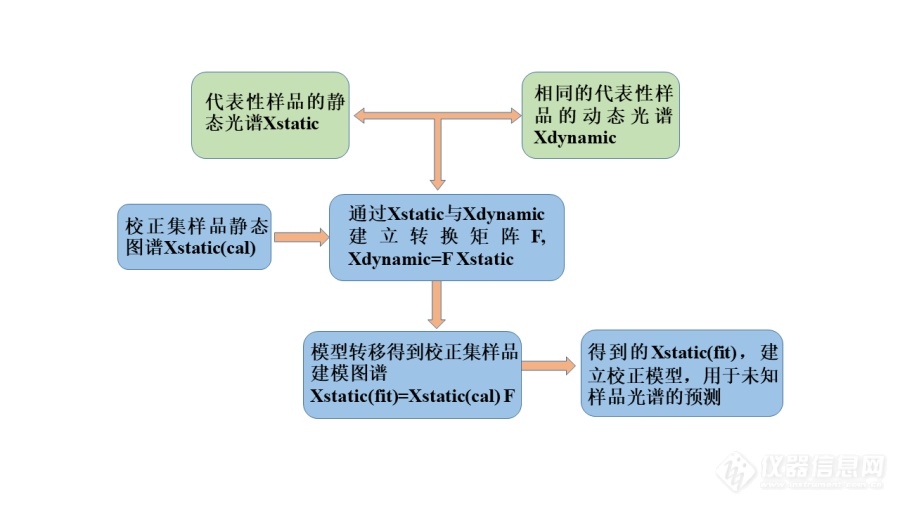
[font='times new roman'][size=18px][b]模型转移[/b][/size][/font][font='times new roman'][size=18px][b]简介[/b][/size][/font][font='times new roman'][size=16px]模型转移可以定义为光谱数据或校准模型的数学转换,以便使所开发的方法与不同的仪器或不同的测量条件兼容。[/size][/font][font='times new roman'][size=16px]模型转移[/size][/font][font='times new roman'][size=16px]的目的是确保在不同情况下获得的[/size][/font][font='times new roman'][size=16px]模型[/size][/font][font='times new roman'][size=16px]结果的互换性,而不必对每种情况进行耗时的重新校准。化学计量[/size][/font][font='times new roman'][size=16px]学[/size][/font][font='times new roman'][size=16px]用于纠正仪器和环境的差异,如仪器反应功能的变化[/size][/font][font='times new roman'][size=16px]([/size][/font][font='times new roman'][size=16px]由仪器更换部分零件或设备老化[/size][/font][font='times new roman'][size=16px]引起)[/size][/font][font='times new roman'][size=16px]、样品的物理或化学组成[/size][/font][font='times new roman'][size=16px]的[/size][/font][font='times new roman'][size=16px]改变[/size][/font][font='times new roman'][size=16px]([/size][/font][font='times new roman'][size=16px]例如[/size][/font][font='times new roman'][size=16px]颗粒[/size][/font][font='times new roman'][size=16px]大小、表面结构、粘度等[/size][/font][font='times new roman'][size=16px])[/size][/font][font='times new roman'][size=16px]及测量条件的变化[/size][/font][font='times new roman'][size=16px]([/size][/font][font='times new roman'][size=16px]如温度和湿度的变化[/size][/font][font='times new roman'][size=16px])等。在本研究中,使用[/size][/font][font='times new roman'][size=16px]相[/size][/font][font='times new roman'][size=16px]同的仪器设备采集的在线与离线[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]被解释为测量条件的变化,[/size][/font][font='times new roman'][size=16px]样品以不同的方式呈现给光谱[/size][/font][font='times new roman'][size=16px]采集[/size][/font][font='times new roman'][size=16px]系统。[/size][/font][font='times new roman'][size=16px]此外,随着光谱采集时间的推移,即使同一样品的光谱也会出现漂移、波长转变、线性或非线性改变等变化,[/size][/font][font='times new roman'][size=16px]因此[/size][/font][font='times new roman'][size=16px]建立的校正集模型需要定期进行维护。如果这些变化不通过定期采集新的校正集光谱进行维护,建立的模型会出现不可估量的误差[/size][/font][font='times new roman'][size=16px],[/size][/font][font='times new roman'][size=16px]且在线模型较离线模型的收集需要消耗更多的物料,模型的定期维护需要更多的经济投入。为了提高在线模型的精度,节省成本,减少校正集光谱收集及模型维护带来的经济成本,采用化学计量学方法对离线光谱与在线光谱间模型传递进行研究,提高了模型的精度和稳定性。[/size][/font][font='times new roman'][size=16px]离线模型的建立验证了便携式[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱仪[/color][/url]用于流化床混合过程[/size][/font][font='times new roman'][size=16px]API[/size][/font][font='times new roman'][size=16px]含量监测的可行性。由于物料的动态特性及其他影响因素的干扰,在线模型精度较低。此外,随着光谱采集时间、环境等的推移,即使同一样品的光谱也会出现漂移、线性或非线性改变等变化,[/size][/font][font='times new roman'][size=16px]故建立[/size][/font][font='times new roman'][size=16px]的校正集模型需要定期进行维护。如果这些变化不通过定期采集新的校正集光谱进行维护,建立的模型会出现不可估量的误差,给生产和检验带来不可估量的损失,且在线模型较离线模型的收集需要消耗更多的物料,模型的定期维护需要更多的经济投入。为了提高在线模型的精度,节省成本,减少校正集光谱收集及模型维护带来的经济成本,[/size][/font][font='times new roman'][size=16px]针[/size][/font][font='times new roman'][size=16px]对流化床混合过程中建立的[/size][/font][font='times new roman'][size=16px]API[/size][/font][font='times new roman'][size=16px]含量[/size][/font][font='times new roman'][size=16px]定量分析模型,采用化学计量学方法对离线光谱与在线光谱间模型传递进行研究,提高了模型的精度和稳定性,将模型转移后建立的新模型用于中试生产过程[/size][/font][font='times new roman'][size=16px]API[/size][/font][font='times new roman'][size=16px]含量的在线监测,实现了实验室到中试应用的理论和实践研究。[/size][/font][font='times new roman'][size=16px]目前,模型转移方法主要包括两大类:光谱数据的模型传递法和结果校正的[/size][/font][font='times new roman'][size=16px]模型传递法[/size][/font][font='times new roman'][size=16px][color=#080000][73, 74][/color][/size][/font][font='times new roman'][size=16px]。其中光谱数据的模型传递包括光谱吸光度及波长(或波数)的校正两个方面。在诸多模型传递方法中,分段直接标准化法[/size][/font][font='times new roman'][size=16px](Piecewise direct standardization,[/size][/font][font='times new roman'][size=16px] [/size][/font][font='times new roman'][size=16px]PDS)[/size][/font][font='times new roman'][size=16px]是最常用的方法之一,也是常用的评价模型传递新方法的参比方法,在模型传递方法中占有重要地位。另一个常用的方法是分段反向标准化法[/size][/font][font='times new roman'][size=16px](Piecewise reverse standardization,[/size][/font][font='times new roman'][size=16px] [/size][/font][font='times new roman'][size=16px]PRS)[/size][/font][font='times new roman'][size=16px]。[/size][/font][font='times new roman'][size=16px]PDS[/size][/font][font='times new roman'][size=16px][color=#080000][75, 76][/color][/size][/font][font='times new roman'][size=16px]法和[/size][/font][font='times new roman'][size=16px]PRS[/size][/font][font='times new roman'][size=16px]法在原理相同的,但数据转换方向不同。[/size][/font][font='times new roman'][size=16px]PDS[/size][/font][font='times new roman'][size=16px]法是将辅仪器[/size][/font][font='times new roman'][size=16px](slave instrument)[/size][/font][font='times new roman'][size=16px]的光谱数据向主仪器方向转换或者将精度低的光谱数据向精度高的方向转换,[/size][/font][font='times new roman'][size=16px]PRS[/size][/font][font='times new roman'][size=16px]法相反,是将将精度高的光谱数据向精度低的方向转换。[/size][/font][font='times new roman'][size=16px]采用化学计量学方法对离线光谱和在线光谱间模型传递进行研究,提高了模型精度,节省了校正集收集及模型维护成本,实现了由实验室到工厂实际应用的理论和实践研究,具体计算过程如图所示,研究内容主要包括:[/size][/font][font='宋体'][size=16px]①[/size][/font][font='times new roman'][size=16px]流化床混合过程中,标准离线光谱[/size][/font][font='times new roman'][size=16px]([/size][/font][font='times new roman'][size=16px]Xstatic[/size][/font][font='times new roman'][size=16px])[/size][/font][font='times new roman'][size=16px]的收集和标准在线光谱[/size][/font][font='times new roman'][size=16px]([/size][/font][font='times new roman'][size=16px]Xdynamic[/size][/font][font='times new roman'][size=16px])[/size][/font][font='times new roman'][size=16px]的收集。[/size][/font][font='宋体'][size=16px]②[/size][/font][font='times new roman'][size=16px]通过标准离线光谱[/size][/font][font='times new roman'][size=16px]([/size][/font][font='times new roman'][size=16px]Xstatic[/size][/font][font='times new roman'][size=16px])[/size][/font][font='times new roman'][size=16px]和标准在线光谱[/size][/font][font='times new roman'][size=16px]([/size][/font][font='times new roman'][size=16px]Xdynamic[/size][/font][font='times new roman'][size=16px])[/size][/font][font='times new roman'][size=16px]建立转换矩阵[/size][/font][font='times new roman'][size=16px][b]F[/b][/size][/font][font='times new roman'][size=16px]。[/size][/font][font='宋体'][size=16px]③[/size][/font][font='times new roman'][size=16px]将采集到的校正集样品离线光谱[/size][/font][font='times new roman'][size=16px]X[/size][/font][font='times new roman'][size=16px]static[/size][/font][font='times new roman'][size=16px]([/size][/font][font='times new roman'][size=16px]cal[/size][/font][font='times new roman'][size=16px])[/size][/font][font='times new roman'][size=16px]通过转换矩阵得到新的校正集建模光谱[/size][/font][font='times new roman'][size=16px]X[/size][/font][font='times new roman'][size=16px]static[/size][/font][font='times new roman'][size=16px](fit)=[/size][/font][font='times new roman'][size=16px]Xstatic[/size][/font][font='times new roman'][size=16px]([/size][/font][font='times new roman'][size=16px]cal[/size][/font][font='times new roman'][size=16px]) [/size][/font][font='times new roman'][size=16px][b]F[/b][/size][/font][font='times new roman'][size=16px].[/size][/font][font='宋体'][size=16px]④[/size][/font][font='times new roman'][size=16px]将得到的校正集光谱矩阵[/size][/font][font='times new roman'][size=16px]X[/size][/font][font='times new roman'][size=16px]static[/size][/font][font='times new roman'][size=16px](fit)[/size][/font][font='times new roman'][size=16px]用于建立校正集模型,用于未知样品的预测。[/size][/font][font='宋体'][size=16px]⑤[/size][/font][font='times new roman'][size=16px]模型传递后与原在线模型及离线模型的比较。[/size][/font][font='宋体'][size=16px]⑥[/size][/font][font='times new roman'][size=16px]将模型转移后的模型用于中试流化床混合过程在线监测并对测量结果进行评价。[/size][/font][align=center][img]https://ng1.17img.cn/bbsfiles/images/2020/09/202009102207075705_1626_3890113_3.png[/img][/align][align=center][font='times new roman']模型转移计算流程图[/font][/align]
食品近红外模型建立,两种较相似的食品,检测同一种指标,可用这两种食品建立同一种指标的模型吗?
现在使用最广的模型转移算法是所谓的pair matching方法,我的问题是怎么保证那个光谱或者说光谱所测量的体系在校正转移前后是绝对一样的,而不受温度,湿度等等的影响。换句话说,在模型转移的过程中怎么提供一个绝对不变的被测体系呢?
分享一下 预处理和波长选择对近红外玉米品种鉴别模型的影响
各位大哥大姐,小弟初试Zismpwin, 想模拟EIS数据,但是软件里面的所有模型都不适合,请问可以自己建立电路模型吗?如何建立?求达人指点。
影响模型转移转移的因素有那些? 现在近红外仪器在模型转移上有何区别?
求书《色谱模型理论导引》,科学出版社的,林炳昌老师编写的,很好的制备色谱理论书,那里有电子版,拿出来分享一下吗,
请教:影响模型转移的因素有哪些?现在市场的近红外仪器模型转移效果如何?
[font=宋体][font=宋体]在线分析校正模型的建立主要分为[/font][font=Times New Roman]5[/font][font=宋体]个步骤:[/font][/font][font=宋体][font=宋体]([/font][font=Times New Roman]1[/font][font=宋体])获取代表性样品并采集对应的[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]。校正模型预测性能的稳健性很大程度上取决于样品本身的代表性,因此获取有良好代表性的样品是建模过程中及其关键的一环。待获取样品后,利用光谱采集装置进行在线[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]的采集,然后利用标准方法测定各份样品待测指标的数值,最后获得样品待测指标与对应光谱信息一一对应的数据集。[/font][/font][font=宋体][font=宋体]([/font][font=Times New Roman]2[/font][font=宋体])校正样本集与验证样品集的选择。校正样本集用来模型训练而验证样本集则用来验证模型的预测性能。理想的校正集应包含未来待测样本中可能存在的所有化学成分,其浓度范围应大于待测样本。目前,常利用[/font][font=Times New Roman]Kennard[/font][/font][font='Times New Roman']-Stone[/font][font=宋体]法、光谱[/font][font='Times New Roman']-[/font][font=宋体]理化值共生距离法进行校正集和验证集的选取。[/font][font=宋体][font=宋体]([/font][font=Times New Roman]3[/font][font=宋体])光谱预处理及波长筛选。在建模过程中,光谱预处理往往是必不可少的,运用适当的方法进行预处理可以有效保留光谱中的关键信息并剔除噪声信息,以提升校正模型的预测性能。波长选择也是重要环节之一,进行波长筛选一方面可以简化模型,更主要的是由于不相关或非线性变量的剔除,可以得到预测能力强、稳健性好的模型。[/font][/font][font=宋体][font=宋体]([/font][font=Times New Roman]4[/font][font=宋体])异常样本的剔除。异常样本会极大的影响建模过程,降低模型的预测准确性和稳定性,因此需要异常样本的识别与剔除。[/font][/font][font=宋体][font=宋体]([/font][font=Times New Roman]5[/font][font=宋体])校正模型的建立。待前面[/font][font=Times New Roman]4[/font][font=宋体]个部分的工作完成后,借助化学计量学算法建立定量校正模型,运用校正标准误差、预测标准误差、决定系数或相关系数等对校正模型的预测性能进行评价。涉及建立、评价定量校正模型或定性判别模型(类模型)可参考[/font][/font][font='Times New Roman']ASTM E-1655[/font][font=宋体]、[/font][font='Times New Roman']GB/T29858-2013[/font][font=宋体]和[/font][font='Times New Roman']GB/T37969-2019[/font][font=宋体]等[/font][font='Times New Roman'][font=宋体]标准[/font][/font][font=宋体]。[/font][font='Times New Roman'][font=宋体]此外,在线模型也可由实验室建立的离线模型通过模型传递技术获得。[/font][/font]
怎样去评价一个好的模型呀!都有什么标准呀!http://simg.instrument.com.cn/bbs/images/default/em09511.gif
饲料行业NIR氨基酸模型如何建立? 如题,百思不解,请各位大仙指点迷津!原料氨基酸模型的湿法化学数据怎么获得(氨基酸分析仪还是液相),怎么处理,需要哪些工作,有无可参考的进度安排(最少需要多少样品量,保守的时间进度)?
[font=宋体][font=宋体]异常样品对模型的稳健性会产生严重的干扰,在建模过程中需要进行剔除。异常样品一般分为两大类,第一类是高杠杆值样品,其光谱远离整体样品的平均光谱;第二类是预测值与参考值具有显著差异的样品,由参考值测量误差大、光谱测量误差大、参考值录入错误及模型不适用等原因造成。对于定量分析,一般可以采用马氏距离和杠杆值剔除第一类异常样品,利用学生化残差剔除第二类异常样品。对于定性分析,常采用[/font][font=Times New Roman]Hotelling[/font][/font][font='Times New Roman']’[/font][font=宋体][font=Times New Roman]s [/font][/font][i][font=宋体][font=Times New Roman]T[/font][/font][sup][font=宋体][font=Times New Roman]2[/font][/font][/sup][/i][font=宋体]检验或[/font][i][font=宋体][font=Times New Roman]F[/font][/font][/i][font=宋体]检验进行异常样品(光谱)的剔除。[/font][font=宋体][font=宋体]在剔除异常样品后,需要对模型进行优化,即选择合适的主成分或变量数建立模型。若所用的主成分或变量数过少,则可能未能充分利用信息,模型会欠拟合,导致模型预测精度下降;而主成分或变量数过多,则可能引入噪声,导致模型过拟合,使得模型稳定性变差。在实际建模中,一般采用交互验证方法进行模型优化,并根据交互验证误差([/font][font=Times New Roman]SECV[/font][font=宋体]或[/font][font=Times New Roman]RMSECV[/font][font=宋体])或预测残差平方和([/font][font=Times New Roman]PRESS[/font][font=宋体])最小来确定适宜的主成分或变量数。[/font][/font][font=宋体][font=宋体]在模型优化后,需要采用验证集样品对模型的有效性进行验证。验证集样品的选取一般要符合一定的要求。对于定量分析,一般采用验证标准误差([/font][font=Times New Roman]SEV[/font][font=宋体])对校正模型有效性进行验证。对于定性分析,通常采用判别正确率对类模型的有效性进行验证。[/font][/font][font=宋体]具体的异常值识别、模型优化与有效性验证方法及验证样品选取标准参见国家标准[/font][font='Times New Roman']GB/T 29858[/font][font=宋体][font=Times New Roman]-2013[/font][font=宋体]和[/font][/font][font='Times New Roman']GB/T37969[/font][font=宋体][font=Times New Roman]-2019[/font][font=宋体]。[/font][/font]
《土壤水环境中污染物运移双点吸附解吸动力学模型》摘要:在考虑对流弥散、平衡/非平衡双点吸附解吸、微生物降解等情况下,建立了土壤环境中有机污染物迁移转化的动力学模型,并给出了有限差分解。在此模型的基础上,详细讨论了有机污染物在土壤中的分布规律,并对一阶吸附解吸速率常数k和平衡吸附点位所占总点位的比例f进行了灵敏度分析。分析研究表明:参数k对于土壤中有机污染物浓度分布有着重要的影响,其影响程度又与非平衡吸附点位所占总点位的比例(1-f)有关;污染后期土壤吸附相的存在,也会起到增加土壤水溶质浓度的作用,且k越大,这种作用越明显。1 引言2 数学模型的建立2.1 污染物在土壤中迁移转化的控制方程2.2 定解条件3 数学模型的有限差分解4 模型分析4.1 有机污染物在土壤中的分布规律4.2 对模型参数k 的分析4.3 平衡吸附点位所占比例f 对参数k 的灵敏度的影响5 结论本文建立了双点平衡/动力学吸附溶质运移模型,并用有限差分法对其进行了离散,通过编制的相应程序对模型进行了初步研究。研究表明:(1)土壤中各点的浓度随着时间的增加,总是呈现先增加后减小的趋势,且在某一时刻形成一个峰值;随着深度的增加,这个峰值会逐渐减小;远离输入端的峰值要比靠近输入端的峰值出现的晚一些。(2)靠近输入端的土壤前期浓度要比远离输入端的土壤前期浓度大很多,而靠近输入端的土壤后期浓度要比远离输入端的土壤后期浓度略小些。(3)停止污染物输入之前,对应于每一时刻的土壤水相浓度沿深度均呈递减趋势,且随着时间的增加,土壤中各点的浓度也不断地增加。停止污染物输入之后,呈现先上升再下降的趋势,而且随着时间的增加,浓度的峰值逐渐降低且峰值点沿深度逐渐下移。(4)在污染后期土壤吸附相的存在,在一定程度上也会增加土壤水的溶质浓度。(5)参数k 对于土壤中浓度分布有着重要的影响; k 的敏感性与非平衡吸附点位所占总点位的比例有关,比例越大, k 的敏感性越强。
有版友做过近红外模型转移的研究吗??可以谈下经验吗







 我要推广仪器
我要推广仪器
 下载APP
下载APP