病毒性肺炎(viral pneumonia,VP)是由病毒入侵呼吸道上皮和肺泡上皮所致的肺间质和实质性急性炎症病变。全年都可发生,冬春季高发。易感人群多为2岁以下婴幼儿、65岁以上老人及孕产妇等。临床常见的VP病原体包括流感性病毒、冠状病毒、麻疹病毒、呼吸道合胞病毒、腺病毒及鼻病毒等[1-2]。腺病毒肺炎是常见的小儿VP之一[3],主要表现为局灶或融合性肺坏死性浸润及支气管炎;呼吸道合胞病毒肺炎以肺间质及毛细支气管病变为主[4],胸片上可见斑点状影,常伴有不同程度的肺气肿;流感病毒肺炎常可侵犯中枢神经系统或循环系统,以肺间质病变为主;甲型流感病毒肺炎较乙型流感病毒肺炎症状更严重,胸部X光片显示片状高密度影,扩散迅速,常有肺间质受累,多伴有胸腔少量积液,病灶吸收后可残留纤维灶[5];冠状病毒肺炎以发热、干咳、乏力为主,可伴有消化道等症状或无症状[6];麻疹病毒肺炎多表现为呼吸道卡他、持续发热等,并出现不同程度的疹退后脱屑、特征性皮疹、色素沉着、口腔科氏斑等临床表现[7];鼻病毒主要感染气道上皮细胞,可引起普通感冒、肺炎、支气管炎和慢性呼吸道等多种疾病,是临床常见的呼吸道感染病原体[8]。然而,VP作为当前临床常见的一种社区获得性肺炎,在西医治疗方面一直缺乏特异性药物。相反,我国传统中医药在治疗VP过程中则拥有悠久的历史和成功经验。从中医角度看,VP属“风温”和“温病”。根据临床资料发现,清肺排毒汤、麻杏石甘汤、化湿解毒方等是临床上最常用于治疗VP的中药汤剂,且疗效显著[9]。其作用机制可能与其调控机体免疫平衡、调控体内微生态、抑制炎症反应、抑制肺纤维化、保护组织及直接抗病毒活性有关。 病证结合动物模型是一种重要的中医药疾病动物模型[10-12],通过对证候发生发展的机制研究,可很好地展现中医“证”的不同发展阶段特征,体现疾病发展的中医病因病机,已成为中医证候研究动物模型的必然趋势,为中医基础向临床治疗的转变提供了理论依据,有利于中药筛选及方剂作用机制的深入研究,是中医药新药研发的重要途径。目前,病证结合动物模型在建模理念上已逐渐成熟,主要可划分为以下3种:(1)以中医理论为依据,中医病因病机为“证”,西医病因为“病”,构建同时具有“病”“证”2个特征的模型动物,这是一种中西医结合多因素造模理念;(2)在西医病态模式基础上观察中医病证,分别归纳疾病初期的证候发展特征及后期出现的典型中医证候,以此判断该疾病是否属于某种中医证型;(3)运用传统中医病因学方法对模式动物进行干预,通过一般状况观察、客观指标检测、常用方药反证等方法,初步建立动物证候模型,并寻找与之匹配的临床病证来进行验证,即在证候模型基础上探察西医疾病类型[13]。 目前现有的VP动物模型多为西医模型,对中医证候模型的研究还较为薄弱,不能反映中医辨证论治的特色。因此,本文对现阶段中医疾病动物模型及相关VP病证模型的建模方法、证型分类、证候研究和评价指标的研究现状进行了梳理,为建立符合中医辨证论治特点的VP动物模型提供参考。 1 VP病证结合动物模型的相关建模研究 1.1 实验动物选择 在选取实验动物时,要尽可能具有与人的相似性,并对各种治疗因子有较高的敏感性,以便能较好地模拟人类疾病症状。目前报道的VP造模动物包括Balb/c小鼠[14]、昆明小鼠[15]、美国癌症研究所ICR小鼠[16]、豚鼠[17]、叙利亚仓鼠[18]、人类血管紧张素转换酶II小鼠[19]、Wistar大鼠[20]、恒河猴[21]、雪貂[22]、树鼩[23]等。虽然部分动物如恒河猴、雪貂、树鼩的病情与人类极为类似,但造模成本高、技术难度大,尚未得到推广应用。目前临床上最常使用的中医证候造模动物仍为小鼠和大鼠,主要是由于其成本低,并且人们对其生活习性和制作方式也较熟悉。 1.2 证候的造模方法 目前公认的中医证候建模方法主要有3种,分别为西医病因病机法、中医病因病机法和病证结合法[24]。其中,病证结合法因稳定性、可操作性高、相对容易评价,且能够体现中医临床辨病与辨证相结合的特点,被认为是比较理想的造模方法[25-26]。表1归纳了3种造模方法各自的应用现状(文献研究举例)、造模依据、干预方法及优缺点。 1.3 VP中医证候学 中医大师根据中医辨证论治体系对VP的证候进行了论述,常见症状包括:发热、咳嗽、咳痰、精神乏力、鼻塞、头痛、流鼻涕、舌色红、苔黄、苔腻、脉滑、脉浮,这些是VP主要的舌象和脉象,可体现VP的中医证候特点,并且与《中医内科学》《温病学》中的相关描述基本相符。依据《中药新药临床研究指导原则(试行)》(2002年)[37]、《小儿病毒性肺炎中医诊疗指南》(2019)[38]及相关文献[39-40],VP的中医辨证分型主要包括风寒郁肺、风热郁肺、痰热郁肺、毒热闭肺、阴虚肺热、肺脾气虚、心阳虚衰和邪陷厥阴等,对不同证型的造模方法归纳见表2。 2 VP病证结合动物模型相关评价指标的研究 病证结合动物模型研究近年来得到广泛关注和应用,针对模型建模的系统评价指标是现在研究的主要方向。目前倾向于从2个层面展开研究:(1)将宏观表象和微观指标相结合,建立人与动物四诊转换模式;(2)强调结合有效经典方药进行反证。 2.1 宏观表征评价 中医辨证以望、闻、问、切为主要手段,以患者临床症状、体征为主要依据进行综合评价,而动物模型则需在动物宏观表象上寻找可供量化、判定的依据,如以模型动物体温上升为发热表现,耸毛或蜷卧为恶寒表现[57]。在脾虚为主的湿热证动物模型研究中,周祎青等[58]发现模型组小鼠表现出精神倦怠、不思饮食、反应迟钝、毛发黯淡等脾虚为主的湿热证症状,证实造模成功。此外,在情志研究中,动物的行为变化是重要评估指标。王枭宇等[59]通过评估多种经典的模型,如旷场实验、强迫游泳实验、悬尾实验等,发现行为学指标能够反映实验动物整体变化的特征,特别是能够反映动物心理情感变化。 需要注意的是,目前对动物模型的宏观判断标准多以人的证候为依据,人与动物在某些方面存在明显差异,同时某些主观因素如动物心理和情绪等变化,都会影响宏观表征结果的可靠性。 2.2 微观指标评价 微观指标能更直观、准确地反映动物机体状态,是判断VP病证结合是否成功的重要依据。 2.2.1 一般情况观察 观察动物情绪、活动、体毛、排泄、饮食、呼吸、体质量、肛温及死亡情况等。如将大鼠置于寒冷条件下连续6 d造模,表现出恶风寒、弓背毛松、打喷嚏、流鼻涕、食欲下降、饮水增加、体温升高、体质量下降及血压升高等明显风寒感冒症状。该症状符合中医的风寒表证[41]。 2.2.2 肺脏指数的测定与肺脏损伤程度的判定 吴莎[60]提出用肺指标、肺损伤程度来评价造模疗效,结果证实病毒感染后小鼠肺部炎症反应加剧且肺指数升高。刘珊宏等[61]采用风扇吹风联合体表降温7 d的方法构建风寒犯表的太阳病小鼠动物模型,发现小鼠造模后体质量显著下降,肺指数显著升高,脾指数显著下降。同时肺部出现明显病变,表现为局部有代偿性空泡、局部出血、肺间质增生、血管壁增厚,嗜中性粒细胞浸润等。杨进等[57]给小鼠滴鼻感染仙台病毒构建风热模型,发现感染病毒8 h内小鼠肺部指标无显著变化,8 h后肺内可见轻度病灶,12 h后肺泡壁厚度显著增加,大量单核细胞和淋巴细胞浸润,说明病证已经从表到里,证实仙台病毒在小鼠滴鼻后的4~12 h可视为类表热证阶段。 2.2.3 炎症因子 近年来关于病毒诱发细胞因子释放及对病毒感染的影响研究结果表明肿瘤坏死因子-α(tumor necrosis factor-α,TNF-α)、白细胞介素-6(interleukin-6,IL-6)是介导炎症反应的重要介质,可促进TNF-α分泌,加剧炎症发生[62-63]。王晓萍[64]采用人工气候箱、高脂饮食、甲型H1N1流感病毒滴鼻法等复制蒿芩清胆汤动物模型,发现病毒感染后TNF-α和IL-6均异常增高,同时死亡率、肺组织病理改变等结果提示模型组气道炎症反应处于持续状态,经蒿芩清胆汤治疗后小鼠肺组织中炎症因子水平显著下降,且可显著降低肺炎的发生,提示蒿芩清胆汤可能通过多靶点调控机体促炎和抑炎平衡;刘珊宏等[61]发现风寒犯表太阳病小鼠模型肺部炎性因子TNF-α、IL-6及IL-1β的表达显著增加;Wan等[65]发现寒冷造模后大鼠血清炎症因子TNF-α、L-1β、IL-6水平显著增加。 2.2.4 免疫功能 呼吸道病毒感染及其发病机制与机体的免疫状态密切相关[66]。白细胞分化抗原4阳性(cluster of differentiation 4+,CD4+)/CD8+、辅助性T细胞1(T helper cell 1,Th1)/Th2是人体内重要的免疫细胞[67],而在动物模型中存在细胞免疫水平显著降低、免疫失衡现象。CD4+/CD8+ T细胞失衡反映了病毒感染导致的机体免疫损伤,Th1/Th2(γ干扰素/IL-4)失衡反映了内、外环境因素和病毒感染综合因素共同作用下的机体应激状态。从微观上看,CD4+/CD8+的值倒置,Th1/Th2细胞因子偏向Th1,使细胞免疫成为优势而导致肺脏损伤,加重疾病,会对证候的发展方向产生影响。通过湿热环境+流感病毒构建流感病毒湿热证模型,采用蒿芩清胆汤能逆转湿热环境和病毒感染综合作用引起的CD4+/CD8+的值下降。蒿芩清胆汤治疗6 d后湿热证模型大鼠外周血γ干扰素/IL-4水平显著高于对照组,表明蒿芩清胆汤具有调节大鼠T淋巴细胞亚群、Th1/Th2平衡、提高抗病毒能力的作用[68]。综上,蒿芩清胆汤抗病毒免疫损伤的机制可能是通过上调细胞免疫功能,使CD4+/CD8+和Th1/Th2重新平衡从而减轻应激状态[69]。 2.2.5 水液代谢 水通道蛋白(aquaporins,AQPs)是一种能特异性转运水分的蛋白。是人体对水液代谢调节的关键因素[70]。迄今共发现13种AQPs蛋白,其中主要体现在肺部的以AQP1、AQP5为主。肺脏中AQP1表达下降可引起气道上皮细胞分泌增多,促进黏蛋白5ac在肺脏中的表达,从而导致气道炎症的加重,而炎性介质分泌增多,纤毛和杯状细胞比率失衡、肺部水分代谢失衡等进一步加重炎症性水肿[71]。AQP5在肺组织水代谢稳态中发挥重要作用,AQP5功能失调是导致肺损伤的重要原因[72-74]。AQP1、AQP5的表达在造模后免疫组化数值和光密度均有明显提高。如在采用环境+膳食+诱发因素+生物感染因素复制湿热证病毒肺炎动物模型中,模型组大鼠AQP1、AQP5免疫组化数值较对照组显著增高,光密度增加。与模型组对比,甘露消毒丹组AQP1蛋白表达显著降低,说明甘露消毒丹治疗湿热证型病毒性肺炎的作用途径之一是通过影响炎性相关的AQP1,加快肺泡内液体的清除、减轻肺组织的水肿程度,抑制湿热证病毒性肺炎模型的炎性反应来实现的[75]。 2.2.6 血脂代谢 VP发病的内因与患者的饮食习惯密切相关,嗜食肥甘厚味,酿生痰浊从而造成了脾胃的运化功能失调,临床上血脂异常通常与其饮食密切相关,因此,湿邪与血脂异常间的关系亦受到广泛关注。有研究采用环境+膳食(喂饲高脂肪食物)+诱发因素+生物感染性因素的方法建立湿热证病毒肺炎动物模型,发现模型小鼠血清中的总胆固醇和低密度脂蛋白胆固醇显著增高,高密度脂蛋白胆固醇显著下降,且存在脂代谢异常,证实了饮食失调是引起内湿的重要因素[69,76]。 2.2.7 Toll样受体(Toll-like receptor,TLR)介导的信号通路 TLR家族在细胞表面或细胞内表达,以模式识别形式与多种病原分子结合激活固有免疫应答,是连接天然免疫与获得性免疫的桥梁,在抵御病原体感染方面具有关键作用[77-82]。 潘沅[69]采用环境+高脂膳食+生物感染性因素的方法复制湿热证动物模型,研究发现,TLR2可以促进下游核因子-κB(nuclear factor-κB,NF-κB)的过度活化,导致大量炎症因子和细胞因子的产生,造成机体自身免疫损伤。而ig蒿芩清胆汤后,小鼠腹腔巨噬细胞中的TLR2受体及其下游NF-κB分子的表达显著降低,表明蒿芩清胆汤可能通过干预TLR2/NF-κB信号转导通路调控细胞因子的产生,从而减少机体自身炎症因子造成的免疫损伤。 2.3经典方药反向验证 中药配伍要遵循“方从法出、法随证立”的原则,所选用的药和方药应与所用的证候密切相关。即在方剂学理论体系下,所选药物或方剂与其主治的证要有较强的相关性。这样可以判断证候是否复制成功。当前,VP病证结合动物模型反证方剂主要集中在中医经典名方和经验方,有麻杏石膏汤、参附龙牡救逆汤、宣白承气汤、三仁汤、蒿芩清胆汤、甘露消毒丹、茵陈蒿汤和龙胆泻肝汤等加减方剂。这些反证方剂在治疗的原则上包含了疏风解表、清热解毒、清化痰热、宣肺开闭、补气养阴、清肺扶正等配伍特点。用一些代表方剂对动物模型进行干预后,动物的临床症状和各项客观指标均得到了显著的改善。汤朝晖等[43]以清热化湿(蒿芩清胆汤)、辛凉透表(银翘散)、益气固表(玉屏风散)为代表的3个治法对风热型流感VP小鼠模型进行干预,均取得较好疗效,提示造模成功。 3 结语与展望 病证结合动物模型是联系中医基础研究与临床应用的重要纽带。中医药基础理论是中华民族几千年同疾病抗争的结晶,在防疫治疫方面积累了丰富的经验[83],近年来,病毒性新发呼吸道传染病全球频发,而中医药在治疗VP等疫情防控中发挥了显著优势和关键作用,VP病证结合动物模型也开始受到越来越多的研究和探索,近年来发展较快。但另一方面,尽管VP动物模型研究在证候模型建模方法等方面已有很多创新,但仍然存在一些难点问题需要和重点关注。 首先,目前VP证候模型的造模方法还很不完善。如风寒郁肺[41]、肺脾气虚模型[52-53]中常使用病因建模,但却在造模时未与病毒相结合,如何使用病毒来复制风寒郁肺、肺脾气虚模型可能是未来的研究方向;目前诸如痰热郁肺模型在细菌性肺炎中有较成熟的造模方法,心阳虚衰模型则多用于冠心病[55]、心衰[84]等,而尚未有关于痰热郁肺模型[45]、毒热闭肺模型、心阳虚模型、邪陷厥阴模型在VP中的造模方法和应用报道,如何借鉴其他病证构建VP病证结合模型也是后续需要重点关注的难题;VP阴虚肺热模型[39]目前还常用单因素造模方式,而单因素的改变难以复制理想的病证结合模型,存在齐同性差的弊端;在西医造模基础上施加中医证候干预因素的造模方法,亦无法很好地反映病证间的因果关系,无法准确识别疾病主证类型,未来基于证候建模的疾病诱发因子的引入有望成为解决这一难题的重要思路。 其次,实验动物的选择和模型评估技术也是目前制约VP病证结合模型研究的主要难点。目前常用的大鼠、小鼠在某些结构、功能、代谢和疾病表征方面尚不能很好地模拟人类病证特点,同时模型评估指标尚无统一规范,且因动物和人类疾病的差异性,很多动物模型无法直接应用于人类证候表征,而微观指标由于存在“一证多方”及多个证候叠加等现象,均给评估带来了巨大困难。 中医证候研究是一个复杂的过程,建立病证结合动物模型要以中医药理论为指导,与现代医学的理论方法相结合,融合多学科知识,从基因组、蛋白质组学、代谢组学、生物信息学等多层次进行深入研究[85-86]。虽然VP病证结合动物模型尚处于不断探索阶段,但随着新知识、新技术的不断融入和创新,相信不久的将来能够得到迅速发展和完善,更好地反映中医“证”的本质,为推动中医药现代化与国际化做出重要贡献。
大家好,我是一个新手,请大家多多关照. 是这样的,我是一个学生,这学期需要做论文,所以特向网上的高手请教几个问题: (1)我论文是关于肥胖的,所以需要建立起肥胖的动物模型(老鼠),尽管我查了很多资料,都没有完全找到肥胖的动物模型的标准评价体系,也就是说什么样的指标可以证明我在老鼠身上的肥胖模型建立成功了,我打算用高脂饮食将老鼠喂胖. (2)另外还有一个脂肪酸合成酶的在脂肪酸形成过程中的通路情况,以及测试方法. (3)什么地方可以下载到和的讲义. 请帮帮忙哦!小女子感谢不尽哦![em06]
我们知道在近红外的实际应用中,在某一近红外仪(称源机)上建立的校正模型,即便在另外一台与源机相同功能的近红外仪(称为目标机)上使用时,因各仪器测量的光谱有差异,模型不再适用,计算结果偏差很大或根本无法使用,解决这类问题的过程称为模型转移,也称为仪器标准化。众所周知建立近红外校正模型时往往需要测量大量样品的化学值或基础性质作为数据基础,投入大、成本高,因此使用模型转移技术实现模型共享和有效利用非常必要。模型转移可克服样品在不同仪器上的量测信号(或光谱) 间的不一致性,通过信号处理以消除仪器对量测信号的影响 ,不仅使已有模型具有较好的动态适应性,而且可以减少因重复建模造成的人力、物力、财力以及时间的浪费。大家在模型转移过程中遇到过什么问题,或有什么好的经验及建议,欢迎一起讨论。下面的四篇英文文献都是近红外模型转移的一些介绍
用于激光颗粒测试技术的非球形颗粒的椭圆衍射模型任中京 王少清( 山东建材学院科研处 济南250022)提要:激光颗粒大小测试的结果与颗粒形状密切相关。通过对椭圆衍射谱的研究, 提出在激光粒度分析中以椭圆谱代替球形颗粒谱。计算机模拟计算与对金刚砂实测的结果表明椭圆衍射模型可以有效地抑制粒度反演结果的展宽, 更准确地获得非球形颗粒群的粒度分布。关键词 激光衍射, 椭圆模型, 颗粒大小分析, 颗粒形状, 反演1 引言 由于颗粒大小对粉末材料的重要影响, 颗粒粒度测试在建材、化工、石油等许多领域已经成为一种不可缺少的检测技术。由于颗粒形状的多样性, 无论何种测量方法, 均需要颗粒模型。通常假定颗粒为球体, 与被测颗粒等体积的球体直径称为粒径, 或称等效粒径 。然而球体模型在激光衍射(散射) 粒度分析技术中却遇到严重困难—对非球形颗粒测试常常产生较大误差, 表现为所测得的粒度分布较真实分布有展宽且偏小。来自日本和美国的颗粒测试报告也有相同的倾向 。从光学原理上看,激光粒度分析技术是通过检测颗粒群的衍射谱来反演颗粒群的尺寸分布的。非球形颗粒的衍射谱与球体有很大不同: 前者是非圆对称的, 而后者是圆对称的。欲使二者具有可比性需要新的物理模型, 新的模型应满足: 1) 更加逼近真实颗粒;2)对一系列颗粒有普遍的适用性;3)可给出衍射谱解析式;4)在激光测粒技术中能校正颗粒形状引起的测量误差;5)能函盖球体模型。本文将证明椭圆衍射模型是满足以上条件的最佳选择。2 非球形颗粒衍射模型的椭圆屏逼近颗粒虽然是三维物体, 但是在激光测粒技术中其横截面是使光波发生衍射的主要几何因素, 因此只需研究与入射光垂直的颗粒横截面。球体衍射模型即是取颗粒的体积等效球的投影圆作为该颗粒的衍射模型。如图1 所示, 将形状任意颗粒的横截面视为一衍射屏。可分别做出其轮廓的最大内接圆和最小外接圆。设外圆直径为2b, 内圆直径为2a。分别以2a, 2b 为长短轴做椭圆。下面将证明该椭圆屏即为与图1 所示的颗粒横截面等效的非圆屏的最佳解析逼近。2. 1非圆屏与椭圆屏的几何关系由图1 可见,与非球颗粒相对应的椭圆屏的面积S e 恰好为其横截面外接圆与内接圆面积的几何中值,而与该椭圆屏面积相等的圆( 面积等效圆) 的直径Do 恰好为其长短轴2a 与2b 的几何中值。http://ng1.17img.cn/bbsfiles/images/2013/05/201305281105_441929_388_3.jpg此颗粒对球体的偏离可用形状系数K 表示, K 定义为:K=b/a[fon
影响模型转移转移的因素有那些? 现在近红外仪器在模型转移上有何区别?
请教:影响模型转移的因素有哪些?现在市场的近红外仪器模型转移效果如何?
目前,模型转移比较容易在同一品牌型号仪器间实现模型转移,不同品牌,或同一品牌不同型号仪器间模型转移较为困难,即使实现模型转移,转移模型预测误差也较大,大家有何想法,欢迎踊跃讨论
[font=宋体]在[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]分析中,由于两台仪器之间存在差异,使得同一样品在两台仪器上所获得的光谱存在差别,导致一台仪器上所建立的模型不能用于另外一台仪器。仪器间的差异包括不同型号仪器之间的差异和相同型号仪器之间的差[/font][font=宋体]异。对于不同型号的仪器,由于分光原理或采用的检测器等不同,导致波长范围、波长精度及光谱响应会存在差异。对于相同型号的仪器,由于加工工艺水平局限及仪器随时间老化等原因,也会使仪器波长及光谱响应存在差异。在许多应用领域中,建立模型是一项烦琐、重复的工作,浪费人力、物力等资源,而且有些情况下样品可能不易获得或不易保存,存在重新建模困难,需要采用数学方法解决仪器之间的模型适用性问题,称之为模型传递。[/font][font=宋体][font=宋体]模型传递([/font][font=Times New Roman]Model transfer[/font][font=宋体]),也称仪器标准化([/font][font=Times New Roman]Standardization of spectrometric instruments[/font][font=宋体])是指经过数学处理后,使一台仪器上的模型(称为源机,[/font][font=Times New Roman]Master[/font][font=宋体])能够用于另一台仪器(称为目标机,[/font][font=Times New Roman]Slave[/font][font=宋体]),从而减少重新建模所带来的巨大工作量,实现样品和数据资源的共享。在确定仪器间光谱关系时,需要在两台仪器上同时测定某些样品的光谱,这些样品称为传递样品。根据是否需要传递样品,将模型传递分为无标样方法和有标样方法[/font][/font][sup][font=宋体][font=Times New Roman][6][/font][/font][/sup][font=宋体][font=宋体]。无标样方法在模型转移过程中不需要任何传递样品,主要以有限脉冲响应([/font][font=Times New Roman]Finite impulse response[/font][font=宋体],[/font][font=Times New Roman]FIR[/font][font=宋体])算法为代表。有标样方法必须选择一定数量的样品组成标样集,并在源机和目标机上分别测得其信号,从而找出该函数关系。这类算法又分为两种,一是基于预测结果的校正,如斜率[/font][font=Times New Roman]/[/font][font=宋体]偏差([/font][font=Times New Roman]Slope/Bias[/font][font=宋体])算法;二是基于仪器所测光谱信号的校正,如直接校正([/font][font=Times New Roman]Direct standardization[/font][font=宋体],[/font][font=Times New Roman]DS[/font][font=宋体])算法、分段直接校正[/font][/font][font=宋体][font=宋体]([/font][font=Times New Roman]Piecewise direct standardization[/font][font=宋体],[/font][font=Times New Roman]PDS[/font][font=宋体])算法和[/font][font=Times New Roman]Shenk[/font][font=宋体]’[/font][font=Times New Roman]s [/font][font=宋体]算法。此外,光谱空间转换([/font][font=Times New Roman]SST[/font][font=宋体])算法,已证明是一种效果良好的方法,其主要通过主从光谱空间之间的转换消除测量条件变化或仪器引起的光谱差异。[/font][/font]
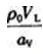
如何建立数学模型讲授人:中国计量科学研究院研究员 倪育才 在测量不确定度评定中,建立数学模型也称为测量模型化,目的是要建立满足测量不确定度评定所要求的数学模型,即建立被测量Y和所有各影响量X间的函数关系,其一般形式可写为: Y=f(X1,X2,…,Xn) 可以说,建立数学模型是进行测量不确定度评定最关键的第一步,也是许多初学者在进行测量不确定度评定时遇到的第一个困难。 《测量不确定度表示指南》(GUM)在摘要介绍测量不确定度评定步骤时,首先就提到要建立数学模型,并说:“The function f should contain everyquantity, including all corrections and correction factors, that can contributea significant component of uncertainty to the result of measurement. ”。其意是数学模型f中应包含所有对测量结果的不确定度有影响的修正值和修正因子。也就是说,数学模型中应包含所有应该考虑的影响量,而每一个影响量将对测量结果贡献一个值得考虑的不确定度分量。因此一个好的数学模型,其中所包含的影响量和此后不确定度评定中所考虑的每一个不确定度分量应该是一一对应的。这样建立起来的数学模型,既能用来计算测量结果,又能用来全面地评定测量结果的不确定度。 要找出每一个影响量与被测量之间的函数关系,往往是很困难的,有时简直不可能得到两者关系的解析表达式。于是许多初学者往往将测量中用来获得被测量的计算公式作为数学模型而列出。例如在各种测量中,最经常采用的方法之一是比较测量。将被测量值y和参考标准所提供的标准量值s相比较,通过测量两者之差Δ可以计算出被测量y。于是在已经发表的各种测量不确定度评定的文章中,经常见到将y=x+Δ作为数学模型的情况。但在进行不确定度评定时,则又往往脱离数学模型而重新考虑各个不确定度分量。这样的数学模型对测量不确定度评定实际上毫无帮助。 在某些特殊情况下(例如某些检测项目)将计算公式作为数学模型可能是允许的,但一般说来不要把数学模型简单地理解为就是计算测量结果的公式,也不要理解为就是测量的基本原理公式。两者之间经常是有区别的。 从原则上说,似乎所有对测量结果有影响的输入量都应该在计算公式中出现,但实际情况却不然。有些输入量虽然对测量结果有影响,但由于信息量的缺乏,在具体测量时无法定量地计算它们对测量结果的影响。也有些输入量由于对测量结果的影响很小而被忽略,故在测量结果的计算公式中也不出现,但它们对测量结果的不确定度的影响却可能是必须考虑的。因此如果仅从计算公式出发来进行不确定度评定,则上述这些不确定度分量就可能被遗漏。当然,在某些特殊情况下如果所有其他不确定度贡献因素的影响都可以忽略不计时,数学模型也可能与计算公式相同。 对于不同的被测量和不同的测量方法,数学模型的具体形式可能差别很大,但实际上都可以用一种比较系统的方式来给出数学模型,或者说可以给出数学模型的通式。 根据测量误差的定义:误差=测量结果-真值。同时误差又可以分为随机误差和系统误差两类,且三者之间的关系为:误差=系统误差+随机误差。于是可以得到: 真值=测量结果-误差 =测量结果-系统误差-随机误差 由于修正值等于负的误差,于是上面的关系式就成为: 真值=测量结果-系统误差-随机误差 =测量结果+系统误差的修正值+随机误差的修正值 实际上,真值就是想得到的被测量的测量结果,于是上式可写成 被测量=测量结果+系统误差的修正值+随机误差的修正值 例1:对于常见的量块比较测量,若ls为标准量块的长度,Δl为测得的两量块的长度差,于是被测量块长度lx的计算公式为: lx=ls+Δl 由于测量时量块的温度通常会偏离标准参考温度20℃,考虑到温度和线膨胀系数对测量结果的影响,计算公式成为: lx=ls+Δl+lsδαθx+lsαsδθ 式中α和θ分别表示线膨胀系数和对标准参考温度20℃的偏差;脚标“s”、“x”分别表示标准量块和被测量块;以及δθ=θs-θx和δα=αs-αx。 考虑到量块测量点可能偏离量块测量面中心点对测量结果的影响,数学模型成为: lx=ls+Δl+lsδαθx+lsαsδθ+δl 将此数学模型和上面给出的通式相比较就可以发现,等式右边的第一、二项ls+Δl即是由测量得到的未修正的测量结果。等式右边的第三、四项lsδαθx+lsαsδθ是对由温度偏差所引入的系统误差的修正值,在本例中这两项的数值十分小而可以忽略,但它们对测量结果不确定度的影响是必须考虑的。等式右边的最后一项δl,是表示由于测量点可能偏离量块中心对测量结果的影响。测量点的偏离对测量结果引入随机误差,因此最后一项实际上是对该随机误差的修正值。由下图可见两者之间的对应关系。http://ng1.17img.cn/bbsfiles/images/2013/10/201310181455_471725_2771427_3.jpg 例2:砝码校准,将被测砝码的质量与具有相同标称值的标准砝码相比较。若被校准砝码和标准砝码的折算质量分别为mx和ms,测得两者的质量差为Δm,于是被校准砝码折算质量mx的计算公式为: mx=ms+Δm 考虑到标准砝码的质量自最近一次校准以来可能产生的漂移Δmd,质量比较仪的偏心度和磁效应的影响Δmc,以及空气浮力对测量结果的影响δB后,其数学模型成为: mx=ms+Δm+δmd+δmc+δB 模型中等式右边的第一、二项为未修正的测量结果。该测量不存在值得考虑的系统误差,也就是说,在数学模型中不存在对系统误差的修正值。等式右边的第三、四、五项为对三项随机误差分量的修正量。与数学模型通式之间的对应关系为:http://ng1.17img.cn/bbsfiles/images/2013/10/201310181455_471726_2771427_3.jpg 在建立数学模型时,未修正的测量结果和系统误差的修正值通常都能比较容易地得到解析形式的数学表达式。惟有随机误差的修正值无法得到其解析形式的表达式。因此只能在数学模型中简单地加上一项,表示对随机误差的修正值。根据随机误差的定义,无限多次测量结果的随机误差的平均值等于零,因此这些项的数学期望为零。也就是说,增加这些修正值后不会对被测量的数值有影响。需要知道的是这些修正值的可能取值范围,通常可以由测量者的经验或
[font=宋体]这个问题在炼化企业应用中经常会被问及,因为校正样品收集比较困难,累积到足够数量和范围需要比较长的时间,而炼厂需要测定来源于不同工艺的各种汽油样品,需要建立多个模型。如果不同种类的汽油样品建立一个模型,则可以同时满足校正集关于数量和范围的要求。但是很遗憾,不同种类的汽油往往不能建立在一个模型中,主要原因是:[/font][font=宋体][font=宋体]([/font][font=Times New Roman]1[/font][font=宋体])不同种类的汽油组成差异很大,样品光谱在光谱空间中形成分类聚集,无法满足校正样品均匀分布的要求。[/font][/font][font=宋体][font=宋体]([/font][font=Times New Roman]2[/font][font=宋体])部分性质,如辛烷值,与光谱存在复杂的非线性关系,很难在宽范围内建立模型,同时又满足测量准确性要求。[/font][/font]
[size=3][font=宋体]一、医学数学化的发展历史[/font][/size][size=3][font=宋体] [/font][/size][size=3][font=宋体]数学应用于生命科学研究的历史可追溯到17 世纪。1615 年英国医生哈维(Farvey W)在研究心脏时应用流体力学知识和逻辑推理方法推断出血流循环系统的存在,18世纪欧拉利用积分方法计算了血流量问题,这些都是历史上应用数学研究生命科学的突出事例。但是,真正大范围地将数学应用于生命科学与医学研究则出现在20世纪中叶。1935年,Mottram对小白鼠皮肤癌的生长规律进行了研究,认为肿瘤细胞总数N随时间的变化速度与N成正比,并获得了瘤体在较短时间内符合指数生长规律的研究成果。1944 年奥地利著名物理学家薛定谔(Schrodinger E)出版了《生命是什么》(What is life)一书,应用量子力学和统计力学知识描述了生命物质的重要特征。在薛定谔的影响下,沃森(Watson JD)和克里克(Crick FHC)利用当时对蛋白质和核酸所做的射线结晶学研究以及其他与DNA结构有关的研究,于1953年建立了DNA超螺旋结构分子模型,验证了薛定谔的设想。在书中,薛定谔还利用非平衡热力学从宏观的角度解释生命现象,认为生命的基本特征是从环境中取得“负熵”,以使生物系统内的熵始终处于低水平。20多年后,普律高津(Prigogine I)等人提出耗散结构理论,将对生命系统的研究推广到薛定谔预言的领域,为此普律高津于1977年荣获了诺贝尔奖。作为医学领域的最高奖项,诺贝尔医学和生理学奖背后的许多数学影像也许更能说明数学在生命科学中的巨大潜力:英国生理学家、生物物理学家Hodgkin和Huxley建立了神经细胞膜产生动作电位时膜电位变化的模型,揭示了神经电生理的内在机制,因而于1963年共享诺贝尔奖;基于二维雷当变换(Radon transform)创建CT成像理论的美国科学家Cormack AM获得了1979年的诺贝尔奖,丹麦科学家Jerne NK则应用数学原理研究免疫网络理论获得1984年的诺贝尔奖。这些奖项有力地表明现代生命科学的研究离不开数学,数学在其中所起的作用和影响越来越重大,高层次的成果往往有赖于合理的数学模型的建立。[/font][/size][size=3][font=宋体] [/font][/size][size=3][font=宋体]数学不仅推动了人们探索生命世界的步伐,事实上两者结合已经产生了多个十分活跃的学科。1901年Peanson 创建生物统计学后,概率论与数理统计方法在医学上得到了非常广泛的应用,如目前常用的显著性检验、回归分析、方差分析、最大似然模型、决策树概率分布、微生物检测等,都属于基于统计学原理的数学模型及分析。1931年,Volterra在研究食物链的基础上,应用微分方程组研究生物动态平衡,完成了《生态竞争的数学原理》,开创了生物数学(biomathematics)这一新的分支。近年来,可视人及虚拟人的研究、计算医学(computational medicine/biology)、生物信息学(bioinformatics)、生理组学(Physiome)等新的学科及领域的出现,使数学这一工具在生物医学研究中的作用日益突出。[/font][/size][size=3][font=宋体] [/font][/size][size=3][font=宋体]生物系统是一个动态系统,作为世界上最复杂的系统之一,它具有调节机制复杂、多输入、多输出等特点,而且由于很多变量或参数很难在体测量及控制,仅仅通过实验研究来揭示其间的复杂关系,会非常困难且不易得到一致的结论。建立生物系统的数学模型,有利于获得生物系统的动态与定量变化,帮助阐明生物医学中有关作用机制等基础性问题,同时通过模型及仿真实验不仅可以得到正常状态,还可以获得异常或极端异常状态下的生理变化预测,以及代替一些技术复杂、代价高昂或难以控制和重现的实验,为临床或特定条件下的方案设计提供预测及指导。此外,从伦理学的角度,人们也希望医学研究中能够减少实验动物的数量,减轻临床试验中人体试验对象不必要的痛苦,因此生理系统的仿真与建模在生物医学领域中的研究中日益受到重视。目前,包括呼吸、血压、体温、各种调节系统等,都已建立了相应的数学模型,并进行了相应的模拟实验。针对特定应用的模型,如细胞动力学、药物动力学模型、生物种群生长模型、神经网络、心血管模型、临床计量诊断模型等,也不断呈现并得到应用。在本节下面的内容中,我们将以应用最为成功的模型之一,药物动力学模型为例,说明医用数学模型的建立过程。[/font][/size][size=3][font=宋体] [/font][/size][size=3][font=宋体]二、医用数学模型实例:药物动力学模型[/font][/size][size=3][font=宋体] [/font][/size][size=3][font=宋体]药物动力学(pharmacokinetics)是定量研究药物在生物体内吸收、分布、排泄和代谢等过程的动态变化规律的一门学科。于1937年由Teorell开创,主要内容是应用动力学原理、体外实验数据以及人体生理学知识,结合数学模型,定量研究药物在体内的运转规律,为药物的筛选提供指导。[/font][/size][size=3][font=宋体] [/font][/size][size=3][font=宋体]众所周知,新药研发过程费用昂贵、时间冗长、淘汰率高,大约有90%的候选药物在临床期间被淘汰,主要原因有口服吸收性差、生物利用度低、半衰期过短等等。为提高新药研究效率和安全性、降低药物研发成本,药物动力学模型已为全球各大制药公司应用。传统的新药研发流程中,药物动力学的应用主要在药物研发的中后期,近年来,人们开始在药物研发的早期对其药物动力学特性进行模拟研究,以尽早淘汰药物动力学参数不理想的候选药物,提高研发效率、降低成本。比如药物虚拟筛选(virtual screening)就是指在化合物合成前,先通过计算机模拟预测其药动学相关特性,进行初步筛选。此外,药物动力学模型在研究药物处置及作用机制、治疗药物监测及个体化用药、新药开发等方面也发挥着重要作用。[/font][/size][size=3][font=宋体] [/font][/size][size=3][font=宋体]药物动力学的数学模型包括房室模型、非线性药物动力学模型、生理药物动力学模型、药理药物动力学模型、统计矩模型等。下面以最常用的房室模型,结合前面所述的建模步骤,对药物动力学模型的建模过程进行分析描述。[/font][/size][size=3][font=宋体] [/font][/size][size=3][font=宋体](一)背景和问题表述[/font][/size][size=3][font=宋体] [/font][/size][size=3][font=宋体]药物进入机体后,在随血液输送到各个器官和组织的过程中,不断地被吸收、分布、代谢,最终被排出体外。药物在血液中的浓度,即单位体积血液中药物的含量,称为血药浓度。血药浓度的大小直接影响到药物的疗效。因此,药物动力学研究的主要对象是血药浓度随时间变化的规律——药时曲线,建模目的是建立能反映药物在体内分布的数学模型及参数,并能反映给药方式、给药时间间隔、给药剂量等对分布的影响。[/font][/size][size=3][font=宋体] [/font][/size][size=3][font=宋体](二)模型构建[/font][/size][size=3][font=宋体] [/font][/size][size=3][font=宋体]上述问题属于人体与外界以及人体内部的物质交换问题,研究这类问题最常用的是房室模型。药物动力学的房室分析方法将人的机体看做由不同房室构成的系统,每个房室代表药物在其中分布大致均匀的组织或体腔。如血液及供血丰富的肝、心、肾在特定情况下可视为一个房室,而血供不足的组织如肌肉、皮肤等可视为另一个房室。为了进行严格数学描述,常对模型做如下假设:①房室具有固定容量,且药物在每个房室内的分布是均匀的;②各房室间可进行物质交换,且至少有一个房室可与外环境进行交换;③房室间的物质交换或药物转移服从质量守恒定律,即系统中物质总量的改变等于输入总量与输出总量之差;④线性假设:药物的转移速率与药物浓度成正比。[/font][/size]
[align=center] [/align] [font=宋体, SimSun][size=15px][color=#48494d]目前在食品和饮料产品上标明的保质期通常为消费者提供了一个粗略的指南,告诉他们在既定加工、包装、运输和储存条件下该产品的货架寿命。[/color][/size][/font] [font=宋体, SimSun][size=15px][color=#48494d]但在实际产品生命链条中,储存条件、运输对包装的破坏等因素的改变可能会使产品的实际保质期短于或长于产品预期的保质期,从而导致与食品安全和浪费相关的问题。[/color][/size][/font] [font=宋体, SimSun][size=15px][color=#48494d]因此保质期预测和评估的进展对提高食品供应的安全性、可靠性和可持续性起到至关重要的作用。[/color][/size][/font] [font=宋体, SimSun][size=15px][color=#48494d]在保质期预测方法中选择合适的动力学模型和数据分析技术是至关重要的,可以根据环境条件的变化,更加准确的预测产品使用寿命,还可以进行实时监控。本文梳理了基于品质衰变原理的保质期预测方法。[/color][/size][/font] [font=宋体, SimSun][size=15px][color=#48494d]近年来,国内外学者利用动态模型研究了肉制品、蔬菜、水果等的品质变化,并对其贮藏期进行预测,取得了较好的结果。[/color][/size][/font] [font=宋体, SimSun][size=15px][color=#48494d]通过分析影响产品质量变化的主要因素确定用于货架期结束的关键指标,形成基于品质衰变原理的货架期预测方法体系。[/color][/size][/font] [font=宋体, SimSun][size=15px][color=#48494d]食品品质变化由内在品质性质因素Ci表示(如浓度、pH 值、水分活度等)与外在环境因素Ej表示(如温度、相对湿度、包装等)决定,食品品质衰变可表示为:rQ=f(Ci,Ej)。食品品质衰变一般包括化学品质衰变、微生物生长动力和食品感官失效三个方面的改变。[/color][/size][/font] [font=宋体, SimSun][color=#007aaa][b][size=15px]1.化学品质衰变动力学模型[/size][/b][/color][/font] [font=宋体, SimSun][size=15px][color=#48494d]食品劣变大多由化学反应引起的食品,一般采用化学品质衰变动力学模型来进行保质期预测。[/color][/size][/font] [font=宋体, SimSun][size=15px][color=#48494d]常用的化学品质衰变动力学模型为阿伦尼乌斯模型(Arrhenius 模型)。[/color][/size][/font] [font=宋体, SimSun][size=15px][color=#48494d]阿伦尼乌斯模型应用于脂肪氧化、美拉德反应、蛋白质变性等易被化学反应破坏的食品。[/color][/size][/font] [font=宋体, SimSun][size=15px][color=#48494d]一般来说,温度越高,化学反应的速度越快,这意味着产品质量下降的速度越快。Q10 模型侧重于温度对货架期的影响,而导致其预测精度比较低,在Arrhenius 模型中,用Q10 这个概念来确定温度对反应的敏感程度。[/color][/size][/font] [font=宋体, SimSun][size=15px][color=#48494d]食品保质期的损失通常通过测量特征质量指数A随时间t的变化来评估,通常表示为f(A)=k(T)t,其中f(A)为食品的质量函数,k 为反应速率常数。[/color][/size][/font] [font=宋体, SimSun][size=15px][color=#48494d]速率常数是绝对温度T 的逆指数函数,由Arrhenius阿伦尼乌斯表达式给出,k=kAexp(–EA/RT),其中kA为常数,EA为控制质量损失的反应活化能,R为通用气体常数。根据以下拟合方程,可以推算货架终点产品品质:[/color][/size][/font] [font=宋体, SimSun][size=15px][color=#48494d]–d[A]/dt=k[A]n,–d[b]/dt=k′[b]n′[/b][/b][/color][/size][/font][b][b] [font=宋体, SimSun][size=15px][color=#48494d]式中:k 和k′为品质变化速率常数;[/color][/size][/font] [font=宋体, SimSun][size=15px][color=#48494d]n 和n′为反应级数;[/color][/size][/font] [font=宋体, SimSun][size=15px][color=#48494d]d[A]/dt 和d/dt 为品质变化速率。[/color][/size][/font] [font=宋体, SimSun][size=15px][color=#48494d]化学指标A(如营养素或特征风味)的损失或不期望的化学指标B(异味成分或褪色色素含量)[/color][/size][/font] [font=宋体, SimSun][size=15px][color=#48494d]若满足A 或B 与时间t 的线性拟合,则为零级模式;[/color][/size][/font] [font=宋体, SimSun][size=15px][color=#48494d]若满足A 或B 半对数与t 的线性拟合,则为一级模式;[/color][/size][/font] [font=宋体, SimSun][size=15px][color=#48494d]若满足1/A 或1/B 与t 的线性拟合,则为二级模式。[/color][/size][/font] [font=宋体, SimSun][color=#007aaa][b][size=15px]2.微生物生长动力学模型[/size][/b][/color][/font] [font=宋体, SimSun][size=15px][color=#48494d]微生物腐烂是食品变质的主要方式之一,特别是对新鲜或最低限度加工的冷藏产品。[/color][/size][/font] [font=宋体, SimSun][size=15px][color=#48494d]微生物可引起食物腐败或引起食源性疾病。研究表明微生物导致的食品腐烂,主要是食品贮藏中的特定腐败菌(specific spoilage organisms,SSO)活动导致的,并且微生物菌群不是静态的,随着不同品类食品内在因素和外界环境因素发生改变,其增长态势是预测食品货架期的重要因素。[/color][/size][/font] [font=宋体, SimSun][size=15px][color=#48494d]货架寿命可以定义为从开始储存到SSOs 达到某一最大水平的时间。生产加工企业应进行货架期实验,以确定何时发生变质,并应有效验证致病性微生物生长趋势,使用合理科学研究来评估其食品的潜在风险。[/color][/size][/font] [font=宋体, SimSun][size=15px][color=#48494d]文献中有许多与温度相关的模型来描述微生物的生长还开发了一系列软件工具来预测食品中某些微生物的生长,然而只有少数是适用于实际的货架寿命预测。[/color][/size][/font] [font=宋体, SimSun][size=15px][color=#48494d]常见的微生物动力学一级模型主要包括四种,Linear 模型、Logistic模型、Gompertz 模型及Baranyi & Roberts 模型。其中Gompertz 模型是预测微生物学的基石,美国农业部开发的PMP(Pathogen Modeling Program)系统和英国农粮渔部开发的FM(Food Micromodel)系统都以Gompertz 函数作为初级模型。[/color][/size][/font] [font=宋体, SimSun][color=#007aaa][b][size=15px]3、感官预测保质期模型[/size][/b][/color][/font] [font=宋体, SimSun][size=15px][color=#48494d]感官预测保质期方法早在20 世纪80 和90 年代,Taoukis 等就描述了进行有效加速货架期测试(ASLT: Accelerated shelf-life testing)的原则和方法。[/color][/size][/font] [font=宋体, SimSun][size=15px][color=#48494d]在ASLT 方法中,温度是决定食品损伤的关键参数,因为温度越高,食品损伤越快。[/color][/size][/font] [font=宋体, SimSun][size=15px][color=#48494d]温度和变质速度之间的关系可以用阿伦尼乌斯方程来表示。通常有两类主要的测试可用于此目的:差异测试(特别是成对比较,双三联测试——通常在差异变化的控制测试中——和三角形测试)和使用适当尺度的测试(特征或某些特定属性)。[/color][/size][/font] [font=宋体, SimSun][size=15px][color=#48494d]目前国内外广泛使用的感官预测货架期方法为威布尔危险分析(Weibull hazard),这是一种较为实用的方法,有效地结合了ASLT 原理和感官方法并进行改进。[/color][/size][/font] [font=宋体, SimSun][size=15px][color=#48494d]威布尔概率函数在工程中被广泛用于描述失效现象,由Gacula 和Kubala提出用于货架寿命测试。该方法的原理主要为产品被消费者拒绝所体现的累计危害率与贮藏时间的关系式为:lgt=lgH/β+lgα[/color][/size][/font] [font=宋体, SimSun][size=15px][color=#48494d]式中:t 为发现新变质食品的时间/d;[/color][/size][/font] [font=宋体, SimSun][size=15px][color=#48494d]H 为累计危险率/%;[/color][/size][/font] [font=宋体, SimSun][size=15px][color=#48494d]α 是尺度威布尔分布参数;[/color][/size][/font] [font=宋体, SimSun][size=15px][color=#48494d]β 是形状威布尔分布参数。[/color][/size][/font] [font=宋体, SimSun][color=#007aaa][b][size=15px]4、保质期预测方法研究案例[/size][/b][/color][/font] [font=宋体, SimSun][size=15px][color=#48494d]Wahyuni等研究布朗尼蛋糕货架期的预测,采用加速货架期测试(ASLT)方法,并结合Arrhenius 模型。[/color][/size][/font] [font=宋体, SimSun][size=15px][color=#48494d]在该研究中,使用了20℃、30℃ 和40 ℃三种储存温度的变化,并选择硫代巴比妥酸(TBA)为变化指标进行监测。[/color][/size][/font] [font=宋体, SimSun][size=15px][color=#48494d]根据Ketaren的研究表明贮藏过程中脂肪等营养成分的变化会使食品发生酸败,氧化产物醛类可与TBA 生成有色化合物,用TBA 值来表示氧化程度,TBA 的数量是决定油脂损害程度的最重要因素。[/color][/size][/font] [font=宋体, SimSun][size=15px][color=#48494d]实验结果表明,TBA 的值随着贮藏温度的升高而增加,布朗尼的贮藏寿命通过阿伦尼乌斯方程来估计,即随着温度升高(20℃、30℃、40 ℃),产品货架期分别为1.57、4.9 和14 d。[/color][/size][/font] [font=宋体, SimSun][size=15px][color=#48494d]Nashi等对超高温瞬时处理后的燕麦谷物饮料进行风味特征的货架期研究,评价指标有不良风味混合物、正己醛和PVG,评价方法采用风味物质色谱分析法,并成立感官评价小组进行风味可接受程度打分,实验结果表明当正己醛含量高于初始值的3~5 倍时,燕麦谷物饮料风味为不可接受。[/color][/size][/font] [font=宋体, SimSun][size=15px][color=#48494d]HU 等研究壳聚糖包埋的鸡蛋在贮藏过程中品质变化和货架期,分别在5℃、20℃和35 ℃条件下,测定经包埋的鸡蛋在贮藏过程中品质的变化。并分析以哈夫值、密度和气室直径增加百分比的Pearson 相关系数,建立基于Arrhenius 方程的货架期预测模型。[/color][/size][/font] [font=宋体, SimSun][size=15px][color=#48494d]结果表明,随着贮藏时间的延长,鸡蛋品质呈下降趋势。高温(20℃和35 ℃)贮藏环境比低温(5 ℃)贮藏环境对品质劣化影响显著;蛋黄品质与霍夫单位的相关系数最高,可以作为预测货架期的重要指标;根据鸡蛋品质的变化规律,蛋黄因素可以建立一阶动力学模型。[/color][/size][/font] [font=宋体, SimSun][size=15px][color=#48494d]根据蛋黄品质变化数建立的模型,预测值与实测值拟合曲线的系数R2 为0.982 5,平均相对误差P 为9.32%,小于10%。较好地描述了蛋黄品质与温度之间的动力学关系。[/color][/size][/font] [font=宋体, SimSun][size=15px][color=#48494d]同时基于动态模型,确定了基于蛋黄系数的壳聚糖鸡蛋货架期预测模型。平均相对误差为7.6%,小于10%,说明基于蛋黄品质变化的鸡蛋货架期预测模型是可行的。[/color][/size][/font] [font=宋体, SimSun][size=15px][color=#48494d]刘红等研究表明目前我国食品及饮料行业保质期的测定大多依靠参照法,即经验值来进行确定,缺乏科学和标准测试方法。在我国应用较为广泛的为加速破坏性实验,所选用的方法为Q10 模型,主要研究贮藏期间温度对产品品质变化的影响。[/color][/size][/font] [font=宋体, SimSun][size=15px][color=#48494d]任亚妮等应用 ASLT 法预测软面包的货架期,实验温度选择为常温20℃、37℃ 和47 ℃,相对湿度为60%,通过检测37 ℃和47 ℃下产品的酸价、过氧化值和微生物指标(菌落总数、霉菌、大肠杆菌),并结合感官评价结果,结合Q10 模型,推算出常温贮藏条件下软面包的货架期。[/color][/size][/font] [font=宋体, SimSun][size=15px][color=#48494d]近年来,部分动力学模型和微生物生长模型也逐渐应用到我国产品保质期预测中。胡云峰等研究不同贮藏温度下鲜湿米粉的品质变化动力学模型,并应用Arrhenius 模型预测其货架期。研究结果表明鲜湿米粉的典蓝值的拟合系数较高,以典蓝值为预测目标建立的模型,经验证误差较小。[/color][/size][/font] [font=宋体, SimSun][size=15px][color=#48494d]程晓凤等研究压缩饼干货架期预测, 选择ASLT 方法结合Arrhenius 模型进行预测。在加速储藏温度条件下,测定压缩饼干酸价的变化,研究发现酸价变化较为明显,符合一级动力学模型,从而建立压缩饼干货架期预测方程,计算出产品在45 ℃下的保质期。[/color][/size][/font][/b][/b]
FOSS的定标模型目前是否有成熟的方法可转移成布鲁克的模型?
[font=宋体]不同炼厂模型是否可以共用,取决于需要检测的样品和性质。一般来说,不同炼厂的原料和工艺条件不尽相同,因此待检测物料有比较大的差别,在主成分空间中,不同炼厂的物料会出现聚类的情况,不利于建模。但是对于某些和光谱有比较明确线性相关的性质,例如族组成,是可以将不同种类样品和不同炼厂样品建立到同一模型中的。[/font]
为什么不少非线性测量模型 可按JJF1059.1评定测量不确定度 JJF1059.1—2012《测量不确定度评定与表示》(以下简称JJF1059.1),第1章范围中就指出本规范主要适用的条件之一:测量模型为线性模型、可以转化为线性的模型或可用线性模型近似的模型。其第4.2.8条也明确指出:本规范主要适用于测量模型为线性函数的情况。如果是非线性函数,应采用泰勒级数展开并忽略其高阶项,将被测量近似为输入量的线性函数,才能进行测量不确定度评定。若测量函数为明显非线性,合成标准不确定度评定中必须包括泰勒级数展开中的主要高级项。 这是因为JJF1059.1评定不确定度依据的不确定度传播律,其必要条件就是当被测量Y是由N个其他量X1,X2,…,XN通过线性测量函数f确定。 但是,在计量学中最典型的测量模型:相对误差 = (示值-真值)/真值,也是非线性测量模型。为什么平时并没有进行泰勒级数展开并忽略其高阶项,将该被测量近似为输入量的线性函数。即并没有将该测量模型进行线性化,能直接据该非线性测量模型正确地评定测量不确定度。而且在JJF1059.1之附录A.2 合成标准不确定度评定方法举例中,给出的四个例子,有两个测量模型是非线性的。JJF1059.1同样也没有进行泰勒级数展开并忽略其高阶项,将其测量模型线性化。 这是因为按JJF1059.1评定测量不确定度,进行合成标准不确定度计算时,对被测量Y与有关的输入量Xi之间函数,求输入量xi的偏导,即求输入量xi的灵敏系数。实际上相当于进行微分近似,即对于非线性函数y对于自变量Δxi = xi2-xi1的增量Δy = y2- y1。用非线性函数y对自变量在xi1处的曲面(或曲线)对于xi的切线所构成的线性函数,进行近似计算。也许这也是导致有的文献说到,不确定度传播律在求灵敏系数很困难时不适用的原因之一。 当然,如果这样的线性的近似,不满足测量任务对测量不确定度评定的要求时。则应对非线性测量函数用泰勒级数展开,并在合成标准不确定度评定中包括泰勒级数展开中的主要高阶项。如果仍不能满足测量任务对测量不确定度评定的要求,则可考虑采用JJF1059.2—2012《用蒙特卡洛法评定测量不确定度》进行不确定度评定。
[em09502]各位我现在也需要近红外模型建立及模型转移方面的相关资料,中英文皆可。希望各位同事帮帮忙。万谢万谢!!
关于二次离子电离的模型:1。 断键模型---解释原子二次离子形成 基本假设:离子基态假设-离子态是基态,观察到二次离子离化的概率决定于离子态是否在能量上有利于以离子形式离开表面。2。分子模型基本假设:离子只能从表面的一定距离出逃逸出来 形成的离子是由于中性分子溅射而解离 在飞离表面的原子间,因为相互碰撞而产生能量级联因此,离子解离的形成在分子离开表面的过程中发生电荷交换3。脱附解离模型基本假设:二次子轰击样品表面,导致而表面吸附分子,原子基团振动增强,而导致其电离。4。价带模型基于这样一个事实:金属离子的氧化态在二次离子基团中起重要作用
用同样的数据,同样的数学处理得到的模型为什么不一样?今天我用一组数据做一个模型,然后把这组数据按一成分含量高低排序,重新做模型,做模型的数学处理方法也是一样的。但是为什么模型不一样呢?两个模型预测另外一组数据,预测结果有的差的还很大? 这是什么原因呢? 大虾们有知道的吗? http://simg.instrument.com.cn/bbs/images/brow/em09501.gif
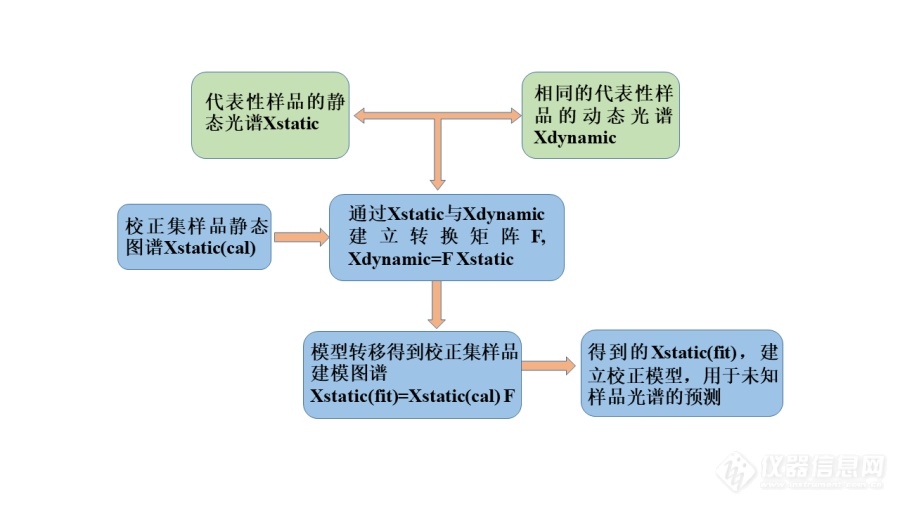
[font='times new roman'][size=18px][b]模型转移[/b][/size][/font][font='times new roman'][size=18px][b]简介[/b][/size][/font][font='times new roman'][size=16px]模型转移可以定义为光谱数据或校准模型的数学转换,以便使所开发的方法与不同的仪器或不同的测量条件兼容。[/size][/font][font='times new roman'][size=16px]模型转移[/size][/font][font='times new roman'][size=16px]的目的是确保在不同情况下获得的[/size][/font][font='times new roman'][size=16px]模型[/size][/font][font='times new roman'][size=16px]结果的互换性,而不必对每种情况进行耗时的重新校准。化学计量[/size][/font][font='times new roman'][size=16px]学[/size][/font][font='times new roman'][size=16px]用于纠正仪器和环境的差异,如仪器反应功能的变化[/size][/font][font='times new roman'][size=16px]([/size][/font][font='times new roman'][size=16px]由仪器更换部分零件或设备老化[/size][/font][font='times new roman'][size=16px]引起)[/size][/font][font='times new roman'][size=16px]、样品的物理或化学组成[/size][/font][font='times new roman'][size=16px]的[/size][/font][font='times new roman'][size=16px]改变[/size][/font][font='times new roman'][size=16px]([/size][/font][font='times new roman'][size=16px]例如[/size][/font][font='times new roman'][size=16px]颗粒[/size][/font][font='times new roman'][size=16px]大小、表面结构、粘度等[/size][/font][font='times new roman'][size=16px])[/size][/font][font='times new roman'][size=16px]及测量条件的变化[/size][/font][font='times new roman'][size=16px]([/size][/font][font='times new roman'][size=16px]如温度和湿度的变化[/size][/font][font='times new roman'][size=16px])等。在本研究中,使用[/size][/font][font='times new roman'][size=16px]相[/size][/font][font='times new roman'][size=16px]同的仪器设备采集的在线与离线[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]被解释为测量条件的变化,[/size][/font][font='times new roman'][size=16px]样品以不同的方式呈现给光谱[/size][/font][font='times new roman'][size=16px]采集[/size][/font][font='times new roman'][size=16px]系统。[/size][/font][font='times new roman'][size=16px]此外,随着光谱采集时间的推移,即使同一样品的光谱也会出现漂移、波长转变、线性或非线性改变等变化,[/size][/font][font='times new roman'][size=16px]因此[/size][/font][font='times new roman'][size=16px]建立的校正集模型需要定期进行维护。如果这些变化不通过定期采集新的校正集光谱进行维护,建立的模型会出现不可估量的误差[/size][/font][font='times new roman'][size=16px],[/size][/font][font='times new roman'][size=16px]且在线模型较离线模型的收集需要消耗更多的物料,模型的定期维护需要更多的经济投入。为了提高在线模型的精度,节省成本,减少校正集光谱收集及模型维护带来的经济成本,采用化学计量学方法对离线光谱与在线光谱间模型传递进行研究,提高了模型的精度和稳定性。[/size][/font][font='times new roman'][size=16px]离线模型的建立验证了便携式[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱仪[/color][/url]用于流化床混合过程[/size][/font][font='times new roman'][size=16px]API[/size][/font][font='times new roman'][size=16px]含量监测的可行性。由于物料的动态特性及其他影响因素的干扰,在线模型精度较低。此外,随着光谱采集时间、环境等的推移,即使同一样品的光谱也会出现漂移、线性或非线性改变等变化,[/size][/font][font='times new roman'][size=16px]故建立[/size][/font][font='times new roman'][size=16px]的校正集模型需要定期进行维护。如果这些变化不通过定期采集新的校正集光谱进行维护,建立的模型会出现不可估量的误差,给生产和检验带来不可估量的损失,且在线模型较离线模型的收集需要消耗更多的物料,模型的定期维护需要更多的经济投入。为了提高在线模型的精度,节省成本,减少校正集光谱收集及模型维护带来的经济成本,[/size][/font][font='times new roman'][size=16px]针[/size][/font][font='times new roman'][size=16px]对流化床混合过程中建立的[/size][/font][font='times new roman'][size=16px]API[/size][/font][font='times new roman'][size=16px]含量[/size][/font][font='times new roman'][size=16px]定量分析模型,采用化学计量学方法对离线光谱与在线光谱间模型传递进行研究,提高了模型的精度和稳定性,将模型转移后建立的新模型用于中试生产过程[/size][/font][font='times new roman'][size=16px]API[/size][/font][font='times new roman'][size=16px]含量的在线监测,实现了实验室到中试应用的理论和实践研究。[/size][/font][font='times new roman'][size=16px]目前,模型转移方法主要包括两大类:光谱数据的模型传递法和结果校正的[/size][/font][font='times new roman'][size=16px]模型传递法[/size][/font][font='times new roman'][size=16px][color=#080000][73, 74][/color][/size][/font][font='times new roman'][size=16px]。其中光谱数据的模型传递包括光谱吸光度及波长(或波数)的校正两个方面。在诸多模型传递方法中,分段直接标准化法[/size][/font][font='times new roman'][size=16px](Piecewise direct standardization,[/size][/font][font='times new roman'][size=16px] [/size][/font][font='times new roman'][size=16px]PDS)[/size][/font][font='times new roman'][size=16px]是最常用的方法之一,也是常用的评价模型传递新方法的参比方法,在模型传递方法中占有重要地位。另一个常用的方法是分段反向标准化法[/size][/font][font='times new roman'][size=16px](Piecewise reverse standardization,[/size][/font][font='times new roman'][size=16px] [/size][/font][font='times new roman'][size=16px]PRS)[/size][/font][font='times new roman'][size=16px]。[/size][/font][font='times new roman'][size=16px]PDS[/size][/font][font='times new roman'][size=16px][color=#080000][75, 76][/color][/size][/font][font='times new roman'][size=16px]法和[/size][/font][font='times new roman'][size=16px]PRS[/size][/font][font='times new roman'][size=16px]法在原理相同的,但数据转换方向不同。[/size][/font][font='times new roman'][size=16px]PDS[/size][/font][font='times new roman'][size=16px]法是将辅仪器[/size][/font][font='times new roman'][size=16px](slave instrument)[/size][/font][font='times new roman'][size=16px]的光谱数据向主仪器方向转换或者将精度低的光谱数据向精度高的方向转换,[/size][/font][font='times new roman'][size=16px]PRS[/size][/font][font='times new roman'][size=16px]法相反,是将将精度高的光谱数据向精度低的方向转换。[/size][/font][font='times new roman'][size=16px]采用化学计量学方法对离线光谱和在线光谱间模型传递进行研究,提高了模型精度,节省了校正集收集及模型维护成本,实现了由实验室到工厂实际应用的理论和实践研究,具体计算过程如图所示,研究内容主要包括:[/size][/font][font='宋体'][size=16px]①[/size][/font][font='times new roman'][size=16px]流化床混合过程中,标准离线光谱[/size][/font][font='times new roman'][size=16px]([/size][/font][font='times new roman'][size=16px]Xstatic[/size][/font][font='times new roman'][size=16px])[/size][/font][font='times new roman'][size=16px]的收集和标准在线光谱[/size][/font][font='times new roman'][size=16px]([/size][/font][font='times new roman'][size=16px]Xdynamic[/size][/font][font='times new roman'][size=16px])[/size][/font][font='times new roman'][size=16px]的收集。[/size][/font][font='宋体'][size=16px]②[/size][/font][font='times new roman'][size=16px]通过标准离线光谱[/size][/font][font='times new roman'][size=16px]([/size][/font][font='times new roman'][size=16px]Xstatic[/size][/font][font='times new roman'][size=16px])[/size][/font][font='times new roman'][size=16px]和标准在线光谱[/size][/font][font='times new roman'][size=16px]([/size][/font][font='times new roman'][size=16px]Xdynamic[/size][/font][font='times new roman'][size=16px])[/size][/font][font='times new roman'][size=16px]建立转换矩阵[/size][/font][font='times new roman'][size=16px][b]F[/b][/size][/font][font='times new roman'][size=16px]。[/size][/font][font='宋体'][size=16px]③[/size][/font][font='times new roman'][size=16px]将采集到的校正集样品离线光谱[/size][/font][font='times new roman'][size=16px]X[/size][/font][font='times new roman'][size=16px]static[/size][/font][font='times new roman'][size=16px]([/size][/font][font='times new roman'][size=16px]cal[/size][/font][font='times new roman'][size=16px])[/size][/font][font='times new roman'][size=16px]通过转换矩阵得到新的校正集建模光谱[/size][/font][font='times new roman'][size=16px]X[/size][/font][font='times new roman'][size=16px]static[/size][/font][font='times new roman'][size=16px](fit)=[/size][/font][font='times new roman'][size=16px]Xstatic[/size][/font][font='times new roman'][size=16px]([/size][/font][font='times new roman'][size=16px]cal[/size][/font][font='times new roman'][size=16px]) [/size][/font][font='times new roman'][size=16px][b]F[/b][/size][/font][font='times new roman'][size=16px].[/size][/font][font='宋体'][size=16px]④[/size][/font][font='times new roman'][size=16px]将得到的校正集光谱矩阵[/size][/font][font='times new roman'][size=16px]X[/size][/font][font='times new roman'][size=16px]static[/size][/font][font='times new roman'][size=16px](fit)[/size][/font][font='times new roman'][size=16px]用于建立校正集模型,用于未知样品的预测。[/size][/font][font='宋体'][size=16px]⑤[/size][/font][font='times new roman'][size=16px]模型传递后与原在线模型及离线模型的比较。[/size][/font][font='宋体'][size=16px]⑥[/size][/font][font='times new roman'][size=16px]将模型转移后的模型用于中试流化床混合过程在线监测并对测量结果进行评价。[/size][/font][align=center][img]https://ng1.17img.cn/bbsfiles/images/2020/09/202009102207075705_1626_3890113_3.png[/img][/align][align=center][font='times new roman']模型转移计算流程图[/font][/align]
[b]卷积神经网络模型发展及应用转载地址:[/b]http://fcst.ceaj.org/CN/abstract/abstract2521.shtml [img]https://oss-emcsprod-public.modb.pro/image/editor/20220802-9243a15c-bcd6-4a63-921e-932f257a1e05.png[/img][img=,690,212]https://ng1.17img.cn/bbsfiles/images/2022/08/202208021122351500_3641_5785239_3.png!w690x212.jpg[/img]深度学习是机器学习和人工智能研究的最新趋势,作为一个十余年来快速发展的崭新领域,越来越受到研究者的关注。卷积神经网络(CNN)模型是深度学习模型中最重要的一种经典结构,其性能在近年来深度学习任务上逐步提高。由于可以自动学习样本数据的特征表示,卷积神经网络已经广泛应用于图像分类、目标检测、语义分割以及自然语言处理等领域。[b]首先分析了典型卷积神经网络模型为提高其性能增加网络深度以及宽度的模型结构,分析了采用注意力机制进一步提升模型性能的网络结构,然后归纳分析了目前的特殊模型结构,最后总结并讨论了卷积神经网络在相关领域的应用,并对未来的研究方向进行展望。[/b]卷积神经网络(convolutional neural network,CNN) 在计算机视觉[1- 5]、自然语言处理[6- 7]等领域已被广泛 应用。在卷积神经网络兴起之前,主要依靠人工针对特定的问题设计算法,比如采用 Sobel、LoG(Laplacian of Gaussian)、Canny、Prewitt 等[8- 11]算子进行边 缘 检 测 ,采 用 Harris、DoG(difference of Gaussian)、FAST(features from accelerated segment test)、SIFT (scale invariant feature transform)等[12-15]用于角点等特 征检测,并且采用传统分类器如 K近域、支持向量机、 稀疏分类器等[16- 18]进行分类。特征提取和分类器的 设计是图片分类等任务的关键,对分类结果的好坏 有着最为直接的影响。卷积神经网络可以自动地从 训练样本中学习特征并且分类,解决了人工特征设计 的局限性。神经网络的思想起源于1943年McCulloch 和 Pitts 提出的神经元模型[19],简称 MCP 神经元模 型。它是利用计算机来模拟人的神经元反应的过 程,具有开创性意义。此模型将神经元反应简化为 三个过程:输入信号线性加权、求和、非线性激活。1958 年到 1969 年为神经网络模型发展的第一阶段, 称为第一代神经网络模型。在 1958 年 Rosenblatt 第 一次在 MCP 模型上增加学习功能并应用于机器学 习,发明了感知器算法[20],该算法使用 MCP 模型能够 采用梯度下降法从训练样本中自动学习并更新权 值,并能对输入的多维数据进行二分类,其理论与实 践的效果引起了神经网络研究的第一次浪潮。1969 年美国数学家及人工智能先驱 Minsky在其著作中证 明感知器本质上是一种线性模型[21],只能处理线性分 类问题,最简单的异或问题都无法正确分类,因此神 经网络的研究也陷入了近二十年的停滞。1986 年到 1988 年是神经网络模型发展的第二阶段,称为第二 代神经网络模型。1986 年 Rumelhart 等人提出了误 差反向传播算法(back propagation algorithm,BP)[22]。BP 算法采用 Sigmoid 进行非线性映射,有效解决了 非线性分类和学习的问题,掀起了神经网络第二次 研究高潮。BP 网络是迄今为止最常用的神经网络, 目前大多神经网络模型都是采用 BP网络或者其变化 形式。早期神经网络缺少严格数学理论的支撑,并 且在此后的近十年时间,由于其容易过拟合以及训 练速度慢,并且在 1991 年反向传播算法被指出在后 向传播的过程中存在梯度消失的问题[23],神经网络再 次慢慢淡出人们的视线。1998 年 LeCun 发明了 LeNet-5,并在 Mnist 数据 集达到 98%以上的识别准确率,形成影响深远的卷积 神经网络结构,但此时神经网络的发展正处于下坡 时期,没有引起足够的重视。从感知机提出到 2006 年以前,此阶段称为浅层 学习,2006 年至今是神经网络的第三阶段,称为深度 学习。深度学习分为快速发展期(2006—2012 年)和 爆发期(2012 年至今),2006 年 Hinton 提出无监督的 “逐层初始化”策略以降低训练难度,并提出具有多 隐层的深度信念网络(deep belief network,DBN)[24], 从此拉开了深度学习大幕。随着深度学习理论的研究和发展,研究人员提 出了一系列卷积神经网络模型。为了比较不同模型 的质量,收集并整理了文献中模型在分类任务上的 识别率,如图 1所示。由于部分模型并未在 ImageNet 数据集测试识别率,给出了其在 Cifar-100 或 Mnist数 据集上的识别率。其中,Top-1识别率指的是 CNN 模型预测出最大概率的分类为正确类别的概率。Top-5 识别率指的是 CNN 模型预测出最大概率的前 5 个分 类里有正确类别的概率。2012 年,由 Alex Krizhevshy 提出的 AlexNet给卷 积神经网络迎来了历史性的突破。AlexNet 在百万 量级的 ImageNet数据集上对于图像分类的精度大幅 度超过传统方法,一举摘下了视觉领域竞赛 ILSVRC2012的桂冠。自 AlexNet之后,研究者从卷积神经网 络的结构出发进行创新,主要有简单的堆叠结构模 型,比如 ZFNet、VGGNet、MSRNet。堆叠结构模型通 过改进卷积神经的基本单元并将其堆叠以增加网络 的深度提升模型性能,但仅在深度这单一维度提升 模 型 性 能 具 有 瓶 颈 ;后 来 在 NIN(network in network)模型提出使用多个分支进行计算的网中网结 构模型,使宽度和深度都可增加,具有代表性的模型 有 Inception 系列模型等;随着模型深度以及宽度的 增加,网络模型出现参数量过多、过拟合以及难以训 练等诸多问题。ResNet 提出残差结构后,为更深层 网络构建提出解决方案,随即涌现出很多残差结构模 型,比如基于 ResNet 改进后的 ResNeXt、DenseNet、 PolyNet、WideResNet,并且 Inception也引入残差结构 形成了 Inception-ResNet-block,以及基于残差结构并 改进其特征通道数量增加方式的 DPResNet;与之前 在空间维度上提升模型性能的方法相比,注意力机 制模型通过通道注意力和空间注意力机制可以根据 特征通道重要程度进一步提升模型性能,典型的模 型为 SENet、SKNet 以及 CBAM(convolutional block attention module)。传统的卷积神经网络模型性能十分优秀,已经 应用到各个领域,具有举足轻重的地位。由于卷积 神经网络的模型十分丰富,有些模型的结构或用途 比较特殊,在本文中统称为特殊模型,包括具有简单的结构和很少参数量的挤压网络模型 SqueezeNet,采 用无监督学习的生成对抗网络模型(generative adversarial network,GAN),其具有完全相同的两路网络 结构以及权值的孪生神经网络模型 SiameseNet,以 及通过线性运算生成其他冗余特征图的幽灵网络 GhostNet。由于卷积神经网络的一系列突破性研究成果, 并根据不同的任务需求不断改进,使其在目标检测、 语义分割、自然语言处理等不同的任务中均获得了 成功的应用。[b]基于以上认识,本文首先概括性地介绍了卷积 神经网络的发展历史,然后分析了典型的卷积神经 网络模型通过堆叠结构、网中网结构、残差结构以及 注意力机制提升模型性能的方法,并进一步介绍了 特殊的卷积神经网络模型及其结构,最后讨论了卷 积神经网络在目标检测、语义分割以及自然语言处 理领域的典型应用,并对当前深度卷积神经网络存 在的问题以及未来发展方向进行探讨。[img=,690,387]https://ng1.17img.cn/bbsfiles/images/2022/08/202208021123119824_325_5785239_3.png!w690x387.jpg[/img][/b][img]https://oss-emcsprod-public.modb.pro/image/editor/20220802-51d3c121-d787-4a08-a7a4-a7f9ecb3a33d.png[/img][b]转载文章,如有侵权,请联系我删除[/b]
水是生命的源泉,是生命体系中的重要组成部分,作为地球上最丰富的物质,大家可能认为没有什么会比水更普通。尽管它的特性早已人尽皆知,外观也寻常不过,以至于人们可能觉得水或多或少和其他的物质是一样的。但实际上,水的奇特之处独一无二。比如说,如果4 ℃的水比冰的密度小,那么湖泊和河流就会从底部开始结冰,里面的生物也将会被逐渐冻死;如果水吸收热量的能力没有那么强,那么我们整颗星球或许早就成为一颗“火球”;如果身体内的水分子不能携带足够的化学物质,那么动植物就都因营养不良而灭绝……因此,关于水分子的结构与功能特性研究一直是非常活跃的课题,甚至于在science成立150周年,将水的结构研究列为一个世纪难题。但即使如此,水的结构依然是一个很“神秘”、没有被完全理解的课题。对于水氢键网络结构的描述,主要有两种说法。一种是水的混合模型,包括强氢键和弱氢键形成的两种形式的水的混合。1967年,G. E. Walrafen通过对水和电解质溶液温度效应的拉曼光谱的研究提出了水以强氢键和弱氢键两种键合形式存在的。1992年发表在JACS的一篇文章也认同了这一观点,并指出弱氢键键合的水指的是弱的、无方向的范德华作用力,并且在空间中均匀分布。强氢键键合的水,分子间以较强的、有方向的力结合在一起,通常是以氢键或者极性相互作用连接的。之后,在2001年,AC上发表一篇文章使用二维相关NIR光谱分析技术和主成分分析对水结构进行了研究。文献指出水中存在弱氢键和强氢键键合的水,并且随温度的变化一种水含量增加,伴随着另一种水含量的减少。2006年,使用同样的方法研究了温度影响的水的NIR光谱。文献指出水的20-80℃的[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]有三种光谱成分,非对称氢键键合的水、对称氢键键合的水以及随温度变化不明显的间隙水。但是混合模型并不能完整的解释水的结构,比如说在液态水或者D2O中,由于伸缩振动带的宽度和不对称性,很难从光谱中分解水的结构,所以无法得出结论液态水是否存在不同的局部区域。所以用混合模型很难解释和归属液态水的光谱特征。因此又有人同时提出连续模型,连续模型是指分子间相互作用的参数认为是连续平滑函数,不会倾向于特定的分子间距离或能量。在连续模型中,强度分布反映的是分子间距离的变化或者在液体水中可获得的一些其他结构参数(频率、谱带宽度)的变化。通过将红外、拉曼光谱转换为和已知参数相关的分布函数,比如O-H伸缩频率和分子间距离的分布函数来解释光谱的变化。1967年发表的一篇文章使用IR光谱研究了温度和压力对水光谱的影响,结果表明高密度的水中不存在非氢键连接的OD基团或者明确结构的小分子水团簇,支持了连续模型的理论。之后又有科学家表明在液态水中氢键的能量和几何参数是连续统计分布的,通过把吉布斯正态分布应用到液态水的总体谐振子上,可以计算吸收带的光谱参数。进一步支持了液态水连续模型的观点。2005年研究者通过飞秒二维红外光谱结合分子动力学模拟研究了液态水的结构,文章指出分子可以通过两种方式控制氢键连接的结构,一是通过热激活破坏氢键结构,在找到新的氢键结构形式之前,生成不固定的氢键结构,二是通过不频繁但是快速的氢键转化过程,在邻近分子之间没有氢键连接的这种结构可以认为是一个过渡状态。二维红外光谱测量结果表明氢键连接结构和非氢键连接结构经历了不同驰豫动力学,非氢键连接重新恢复到氢键连接在时间规模上是最快的。模拟的结果表明绝大多数非氢键连接的结构实际上是氢键连接的一部分,并且最终所有分子都会回到氢键连接的结构,非氢键连接结构本质上是不稳定并且在液态水中是没有无关紧要的结构。所以对于水的结构到底是什么样子,还需要我们不断的进行研究和探索,希望早日可以揭开水神秘的“面纱”。
[font=宋体][font=宋体]在模型的应用过程中,原料种植环境和工艺条件等的改变或调整都会导致模型不再适用,这时就需要进行模型的更新和维护。模型的更新过程需要收集多个有代表性的新样本,然后,按照常规建模流程添加到原模型校正集中,重新建立模型。如果进行了模型更新则需要重新进行验证过程。对模型更新验证集的要求与新建模型时相同,原有的验证集样本可以用于新模型的验证,但是,必须补充代表新范围或新类型的样本。读者可参考分子光谱多元校正定量分析通则[/font] [font=Times New Roman](GB/T[/font][/font][font='Times New Roman'] 29858[/font][font=宋体][font=Times New Roman]-[/font][/font][font='Times New Roman']2013[/font][font=宋体][font=Times New Roman])[/font][font=宋体]。[/font][/font]
研究中药时,其研究模型是怎么定的呢?
在近红外运用过程中,有一个常常被人提起的说法,就是“近红外光谱分析法的测定结果不如参考方法的准确”。这已经基本成为大家在应用近红外时的常识了。但真想真如此吗? 我们知道,近红外模型的数据来源是通过传统方法得到的近红外分析方法作为间接的分析方法,在人们认识上,其准确度必然低于直接分析法(也就是定标方法)。但褚小立博士做过一个实验,结论指出,在精度相对较差的情况下,近红外光谱预测出的数据更接近于真值(具体情况请参见附件文献其理论依据是,通过大量样本的光谱分析和化学计量学统计处理,已经将结果回归到正常范围。 在你心中,在你的认识里,近红外的预测结果与实验结果谁的误差大些? 近红外能不能冲破“近红外光谱分析法的测定结果不如参考方法的准确”的魔咒,成为国标制定的新的方向,甚至是在一些工作中成为强制执行的质控标准?
ARIMA模型一般是利用预测变量的过去值、当前值和误差值进行预测。那么如何利用含有自变量的ARIMA模型进行预测?模型阶数的确定方法还是一样的么?模型的参数怎么确定呢?有什么软件可以实现还是继续用eviews?希望高手帮助解答,谢谢。
建立近红外模型之后,怎样验证模型或者评价模型的好坏?
前几天看到坛里的一则帖子:《从一次曲线看二次曲线》,很简单地表达了自己的看法:相关系数与拟合模型无关。我自己也编写过原子吸收软件,很清楚相关系数是怎样算出来的。根据《数学手册》上的定义,相关系数只与自因变量的统计特性有关,而与所用的拟合模型是没有关系的。不过帖主“冰山”同学很快就贴出某软件的截图反驳了我的观点,贴图上很清楚显示不同的拟合模型有着不同的“相关系数”。这是什么回事呢?要搞清楚这个问题,需要搞清楚一个概念,即何为相关系数?其实相关系数是表示两个变量的相关程度的,一个模型中的自因变量如果存在单调性,如变量A增加则变量B增加(或者减小),以及相反,变量A减小则变量B减小(或增加),我们说两个A与B变量之间存在很强 的相关性。那么相关性的大小有如何计算呢?人们用的是线性相关系数R,它是一个衡量自因变量之间线性关系的一个指标。如果线性相关系数等于1或者-1,说明因变量可以用自变量的一次方程完美表达。因此,线性相关系数和所选择的拟合方程式确实是没有关系的,因为它只对线性方程有意义。那么如何比较两条工作曲线的优劣了。通常,人们会用剩余误差来说明工作曲线的质量。所谓剩余误差,指的是对所有实验样本的因变量与模型估计值之差的平方求和,不过这个数值有些主观,因为它与因变量的取值范围有关。例如,显然,一个取值在1000附近的变量显然比在0.1 附近取之的变量有大得多的误差,因此更“客观的”指标是所谓的“相对剩余误差”,即总剩余误差除以变量变异数(所有实验样本的变量与其算术平均值之差的平方求和)所得之结果。很显然,这个“相对剩余误差”(Qse)越小,拟合质量越好,它与所选择的拟合方程模型是相关的。对于线性拟合模型,Qse^2和R^2之和恰好等于1,所以在线性拟合模型中,常用线性相关系数的平方来说明拟合质量,因为这个值越大(越接近1),拟合质量越好,这很符合人们的思维习惯。对于非线性拟合方程,所谓的相关系数已经不适用了,于是,人们用1减去Qse^2杜撰出一个“相关系数”,更确切地说,这个系数实际上是“模型相关系数”。个人认为,分析软件中的相关系数,还是用“模型相关系数”更加合适。
提 要 通过 1949 年以来在各种出版物上已发表的 27 种生物多样性模型分析发现,大多数多样性模型在理论上是不完善的。例如,被应用最广泛的 Shannon 模型至少有 4 个缺点:①没有考虑物种间生物量的区别;②如果要使用 Shannon 模型,每种物种的个数或每种景观单元的个数不能小于 100;③模型中没有隐含面积参数;④不能够表达多样性的丰富性方面。因此,作者推举了一种理论上完善的综合生物多样性模型,并为了满足实际操作和生物多样性自相似性研究的需要,对其中的一些参数进行了修正。关键词 多样性;丰富性;均一性;理论模型[img]http://www.instrument.com.cn/bbs/images/affix.gif[/img][url=http://www.instrument.com.cn/bbs/download.asp?ID=103383]生物多样性模型研究[/url]
[b][font=宋体]一、模型传递[/font][/b][font=宋体][url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]容易受外界因素干扰而发生扰动或者变化,例如温度、湿度、样本形态、仪器漂移或仪器更换等,导致建立的模型难以适应新的应用场景。通过建立不同条件下光谱、模型系数或预测结果的关系,从而消除预测偏差的方法称为模型转移[/font][sup][font=宋体][font=Times New Roman][[/font][/font][/sup][sup][font='Times New Roman']68][/font][/sup][font=宋体][font=宋体],常见的方法包括斜率截距法([/font][font=Times New Roman]Slope/bias,S/B[/font][font=宋体])、专利算法[/font][/font][font='Times New Roman'][font=宋体]([/font][/font][font=宋体][font=Times New Roman]Shenks [/font][/font][font='Times New Roman']a[/font][font=宋体][font=Times New Roman]lgorithm[/font][/font][font='Times New Roman'][font=宋体])[/font][/font][font=宋体]、直接标准化[/font][font='Times New Roman'][font=宋体]([/font][/font][font=宋体][font=Times New Roman]Direct [/font][/font][font='Times New Roman']s[/font][font=宋体][font=Times New Roman]tandardization[/font][/font][font='Times New Roman'], [/font][font=宋体][font=Times New Roman]DS[/font][/font][font='Times New Roman'][font=宋体])[/font][/font][font=宋体]、分段直接标准化[/font][font='Times New Roman'][font=宋体]([/font][/font][font=宋体][font=Times New Roman]Piecewise [/font][/font][font='Times New Roman']d[/font][font=宋体][font=Times New Roman]irect [/font][/font][font='Times New Roman']s[/font][font=宋体][font=Times New Roman]tandardization[/font][/font][font='Times New Roman'], [/font][font=宋体][font=Times New Roman]PDS[/font][/font][font='Times New Roman'][font=宋体])[/font][/font][font=宋体]、光谱空间转换[/font][font='Times New Roman'][font=宋体]([/font][/font][font=宋体][font=Times New Roman]S[/font][/font][font='Times New Roman']pectral space transformation, SST[font=宋体])[/font][/font][font=宋体]、典型相关性分析[/font][font='Times New Roman'][font=宋体]([/font][/font][font=宋体][font=Times New Roman]Canonical [/font][/font][font='Times New Roman']c[/font][font=宋体][font=Times New Roman]orrelation [/font][/font][font='Times New Roman']a[/font][font=宋体][font=Times New Roman]nalysis[/font][/font][font='Times New Roman'], [/font][font=宋体][font=Times New Roman]CCA[/font][/font][font='Times New Roman'][font=宋体])[/font][/font][font=宋体],交替三线性分解[/font][font='Times New Roman'][font=宋体]([/font][/font][font=宋体][font=Times New Roman]Alternating tri-linear [/font][/font][font='Times New Roman']d[/font][font=宋体][font=Times New Roman]ecomposition[/font][/font][font='Times New Roman'], [/font][font=宋体][font=Times New Roman]ATLD[/font][/font][font='Times New Roman'][font=宋体])[/font][/font][font=宋体]光谱标准化和多级同时成分分析[/font][font='Times New Roman'][font=宋体]([/font][/font][font=宋体][font=Times New Roman]M[/font][/font][font='Times New Roman']ulti-level simultaneous component analysis[/font][font=宋体][font=Times New Roman],MSCA[/font][/font][font='Times New Roman'][font=宋体])[/font][/font][sup][font='Times New Roman'][69][/font][/sup][font=宋体]。[/font][font=宋体]因子分析是将数据在低维空间中表示的一类方法,利用因子分析将高维空间中的光谱转移转化为低维空间中的抽象因子,这能够有效降低模型转移的复杂程度。例如,联合独立分块分析[/font][font='Times New Roman'][font=宋体]([/font][/font][font=宋体][font=Times New Roman]J[/font][/font][font='Times New Roman']oint and unique multiblock analysis[font=宋体])[/font][/font][sup][font='Times New Roman'][70][/font][/sup][font=宋体]、域不变偏最小二乘[/font][font='Times New Roman'][font=宋体]([/font][/font][font=宋体][font=Times New Roman]D[/font][/font][font='Times New Roman']omain-invariant partialleastsquares[font=宋体])[/font][/font][sup][font='Times New Roman'][71][/font][/sup][font='Times New Roman'][font=宋体]、[/font][/font][font=宋体]等仿射不变式[/font][font='Times New Roman'][font=宋体]([/font][/font][font=宋体][font=Times New Roman]A[/font][/font][font='Times New Roman']ffine invariance[font=宋体])[/font][/font][sup][font='Times New Roman'][72][/font][/sup][font=宋体]等。张等[/font][sup][font='Times New Roman'][73][/font][/sup][font=宋体]在此基础上提出了一种基于权重系数的模型转移方法[/font][font='Times New Roman'][font=宋体]([/font][/font][font=宋体][font=Times New Roman]C[/font][/font][font='Times New Roman']alibration transfer based on the weight matrix[font=宋体])[/font][/font][font=宋体],该方法在偏最小二乘权重系数的基础上构造模型转移函数,转化偏最小二乘权重为得分,将光谱间的转化关系变换为光谱与得分矩阵间的转化,简化了模型转移的复杂程度,提高了模型转移的可靠性。[/font][font=宋体]基于拉格朗日乘子法的正则化方法不但能够实现模型的平滑、稀疏等特性,还能够自由结合多种约束实现模型转移和模型更新。此类方法通过超参[/font][font='Times New Roman'][font=宋体]([/font][/font][font=宋体][font=Times New Roman]Hyper-parameter[/font][/font][font='Times New Roman'][font=宋体])[/font][/font][font=宋体]来平衡效率[/font][font='Times New Roman'][font=宋体]([/font][/font][font=宋体]目标函数[/font][font='Times New Roman'][font=宋体])[/font][/font][font=宋体]和模型复杂程度[/font][font='Times New Roman'][font=宋体]([/font][/font][font=宋体]约束条件[/font][font='Times New Roman'][font=宋体])[/font][/font][font=宋体]的关系,但需要通过交互验证或者外部验证决定合适的参数。张等[/font][sup][font='Times New Roman'][74][/font][/sup][font=宋体][font=宋体]在此基础上提出了一种基于岭回归的模型更新方法,将预测优化目标和模型系数的[/font][font=Times New Roman]2[/font][font=宋体]范数约束结合起来,实现了模型系数的更新,解决了由于仪器漂移或样本变化引起的模型预测能力和可靠性变差的问题。[/font][/font][font=宋体]通常,使用标准样本的模型转移方法的结果相对更加准确,然而,其应用性受到限制。邵学广课题组提出了一系列无需标准样本的模型转移方法,例如,双模型策略[/font][font='Times New Roman'][font=宋体]([/font][/font][font=宋体][font=Times New Roman]Dualmodelstrategy[/font][/font][font='Times New Roman'][font=宋体])[/font][/font][sup][font='Times New Roman'][75][/font][/sup][font=宋体]、偏最小二乘校正[/font][font='Times New Roman'][font=宋体]([/font]PLS-[/font][font=宋体][font=Times New Roman]c[/font][/font][font='Times New Roman']orrected[font=宋体])[/font][/font][sup][font='Times New Roman'][76][/font][/sup][font=宋体]和线性模型校正[/font][font='Times New Roman'][font=宋体]([/font][/font][font=宋体][font=Times New Roman]L[/font][/font][font='Times New Roman']inear model correction, [/font][font=宋体][font=Times New Roman]LMC[/font][/font][font='Times New Roman'][font=宋体])[/font][/font][sup][font='Times New Roman'][77][/font][/sup][font=宋体]方法。这些算法不需要使用在不同仪器或者不同条件下采集的标准样本的[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url],因此,可以用于无标准光谱的模型维护和增强。张等[/font][sup][font='Times New Roman'][78][/font][/sup][font=宋体][font=宋体]在[/font][font=Times New Roman]LMC[/font][font=宋体]基础上提出的修正线性模型校正[/font][/font][font='Times New Roman'][font=宋体]([/font][/font][font=宋体][font=Times New Roman]M[/font][/font][font='Times New Roman']odified linear model correction[/font][font=宋体][font=Times New Roman],[/font][/font][font='Times New Roman']m[/font][font=宋体][font=Times New Roman]LMC[/font][/font][font='Times New Roman'][font=宋体])[/font][/font][font=宋体]方法利用拉格朗日乘子法,将预测优化目标函数与不同条件下模型系数相关性约束相结合,实现了对不同仪器设备基础上建立的分析模型高效、快速的无标准样本转移。此外,张等[/font][sup][font='Times New Roman'][79][/font][/sup][font=宋体][font=宋体]提出了利用相关系数约束结合全局游湖算法实现了无参数的模型增强([/font][font=Times New Roman]P[/font][/font][font='Times New Roman']arameter-free calibration enhancement[font=宋体])[/font][/font][font=宋体]框架,包括无监督、半监督和全监督的模型转移、维护和增强等多种应用情况。[/font][font=宋体][font=宋体]以上所介绍的这些方法,又称为[/font][font=宋体]“软拷贝”转移模型,值得近红外用户关注的是,随着仪器制造技术的不断提高,近红外仪器之间的光学性能差异越来越小,仪器之间的光谱测量结果具有很好的重现性,将原机模型或光谱“硬拷贝”到新光谱仪上就能正常使用,省去了复杂的“软拷贝”计算工作。[/font][/font]
《土壤水环境中污染物运移双点吸附解吸动力学模型》摘要:在考虑对流弥散、平衡/非平衡双点吸附解吸、微生物降解等情况下,建立了土壤环境中有机污染物迁移转化的动力学模型,并给出了有限差分解。在此模型的基础上,详细讨论了有机污染物在土壤中的分布规律,并对一阶吸附解吸速率常数k和平衡吸附点位所占总点位的比例f进行了灵敏度分析。分析研究表明:参数k对于土壤中有机污染物浓度分布有着重要的影响,其影响程度又与非平衡吸附点位所占总点位的比例(1-f)有关;污染后期土壤吸附相的存在,也会起到增加土壤水溶质浓度的作用,且k越大,这种作用越明显。1 引言2 数学模型的建立2.1 污染物在土壤中迁移转化的控制方程2.2 定解条件3 数学模型的有限差分解4 模型分析4.1 有机污染物在土壤中的分布规律4.2 对模型参数k 的分析4.3 平衡吸附点位所占比例f 对参数k 的灵敏度的影响5 结论本文建立了双点平衡/动力学吸附溶质运移模型,并用有限差分法对其进行了离散,通过编制的相应程序对模型进行了初步研究。研究表明:(1)土壤中各点的浓度随着时间的增加,总是呈现先增加后减小的趋势,且在某一时刻形成一个峰值;随着深度的增加,这个峰值会逐渐减小;远离输入端的峰值要比靠近输入端的峰值出现的晚一些。(2)靠近输入端的土壤前期浓度要比远离输入端的土壤前期浓度大很多,而靠近输入端的土壤后期浓度要比远离输入端的土壤后期浓度略小些。(3)停止污染物输入之前,对应于每一时刻的土壤水相浓度沿深度均呈递减趋势,且随着时间的增加,土壤中各点的浓度也不断地增加。停止污染物输入之后,呈现先上升再下降的趋势,而且随着时间的增加,浓度的峰值逐渐降低且峰值点沿深度逐渐下移。(4)在污染后期土壤吸附相的存在,在一定程度上也会增加土壤水的溶质浓度。(5)参数k 对于土壤中浓度分布有着重要的影响; k 的敏感性与非平衡吸附点位所占总点位的比例有关,比例越大, k 的敏感性越强。







 我要推广仪器
我要推广仪器
 下载APP
下载APP