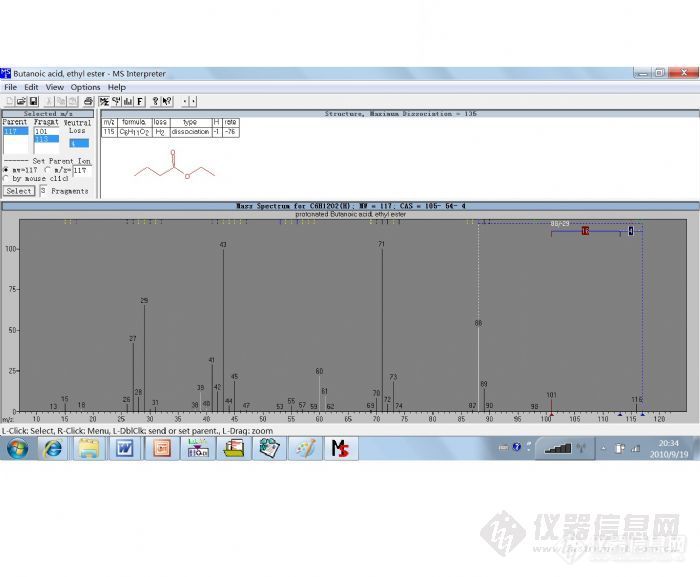
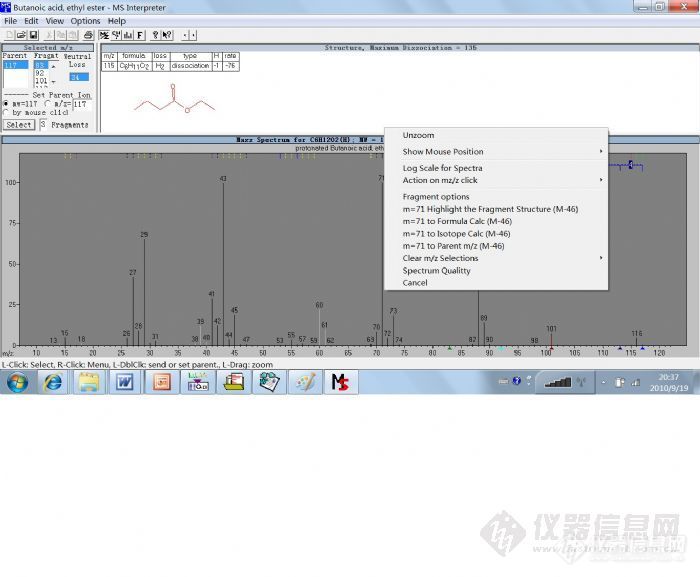
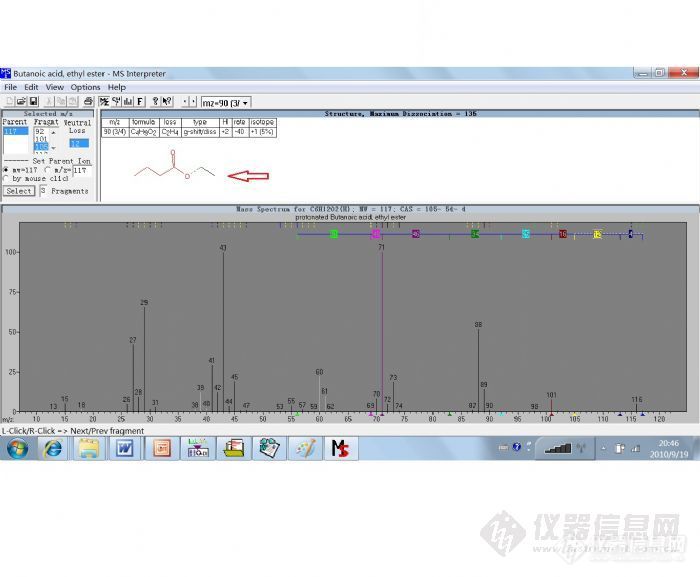
维权声明:本文为jimzhu原创作品,本作者与仪器信息网是该作品合法使用者,该作品暂不对外授权转载。其他任何网站、组织、单位或个人等将该作品在本站以外的任何媒体任何形式出现的,均属侵权违法行为,我们将追究法律责任。
NIST检索初学笔记
symmacros
第2楼2010/09/19
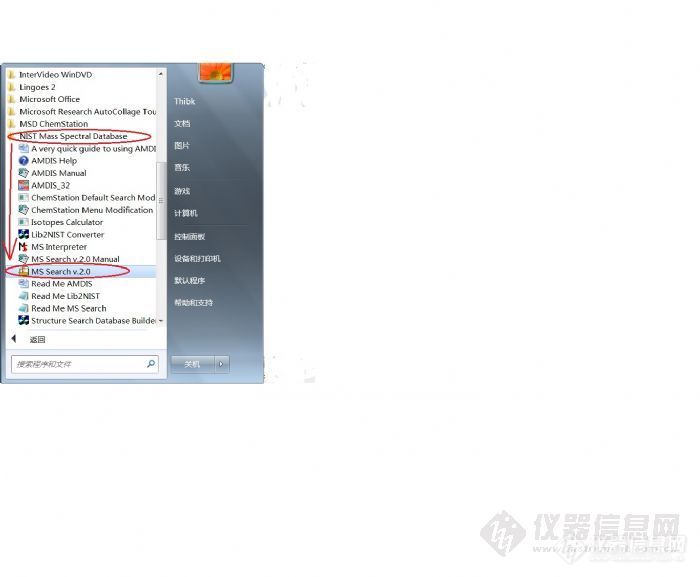
二.NIST 谱库检索(Library Search)
1.未知物的检索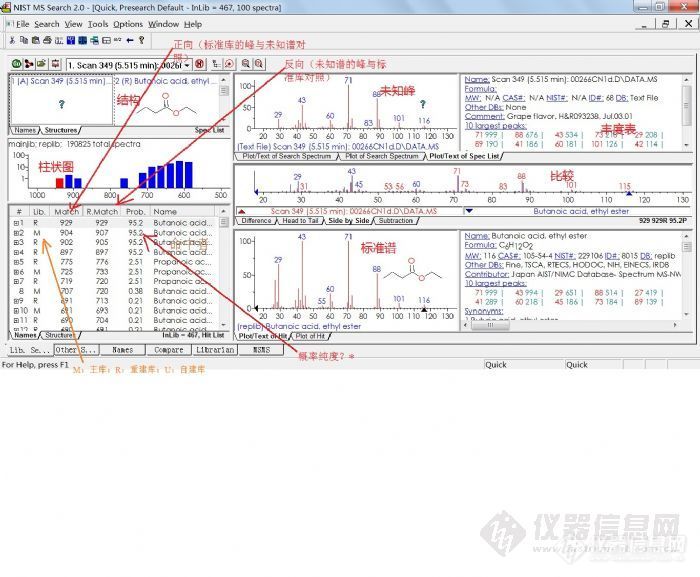
可以通过按鼠标右键进行有关切换。
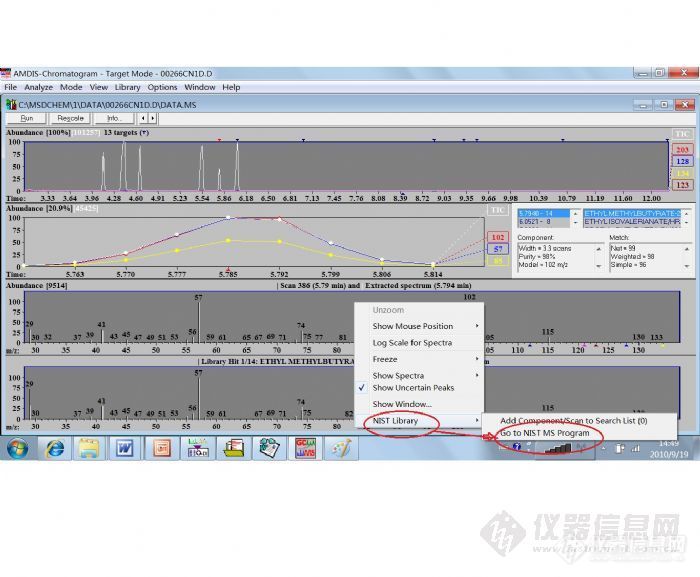
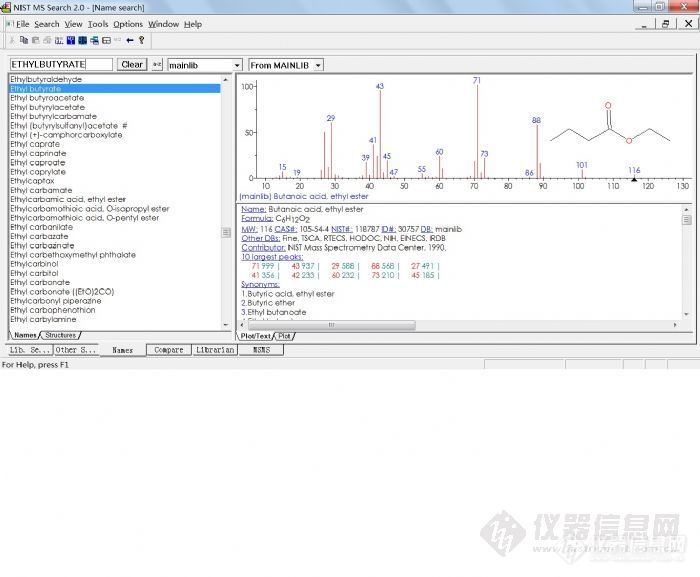
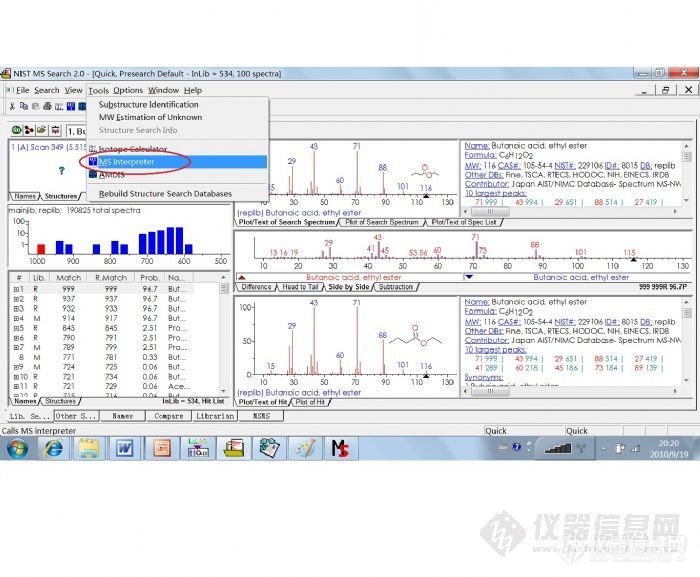
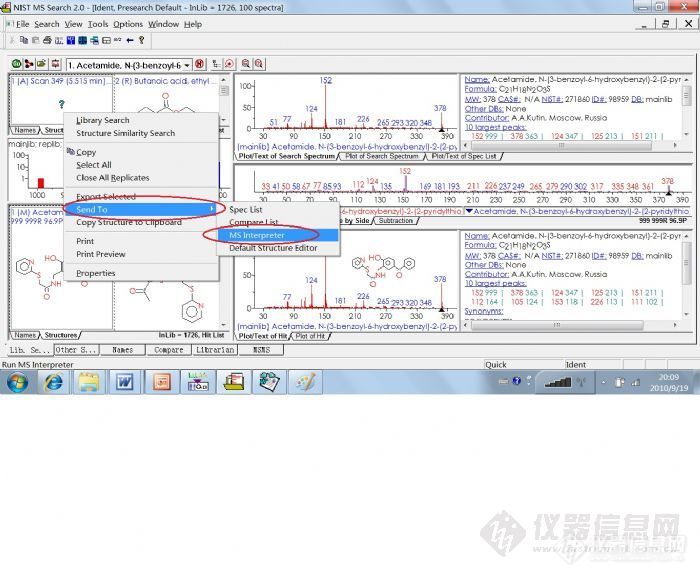
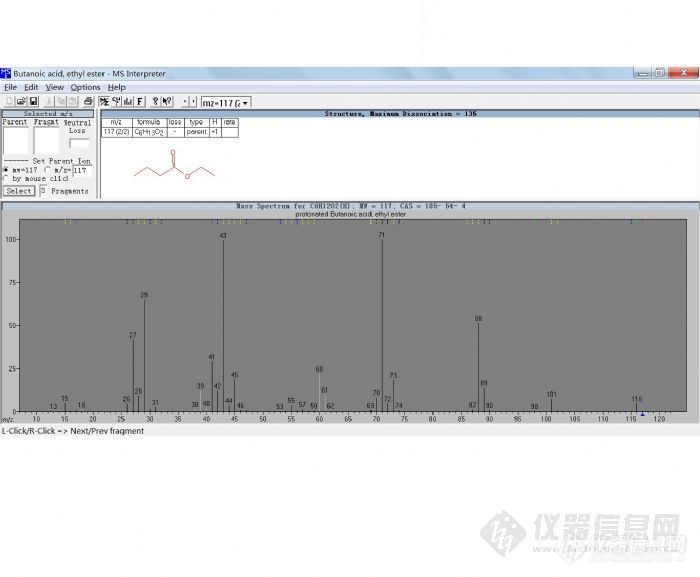
这是NIST谱库与化学工作站链接进行检索的一种方式。其检索的匹配用正向和反向两种方法表示。
质谱数据库(MS Library):
主谱库(Mainlib), 主要EI MS库, 重建谱库(replib), 保留指数库(nist ri), MS/MS谱库(nist msms),自建谱库等。
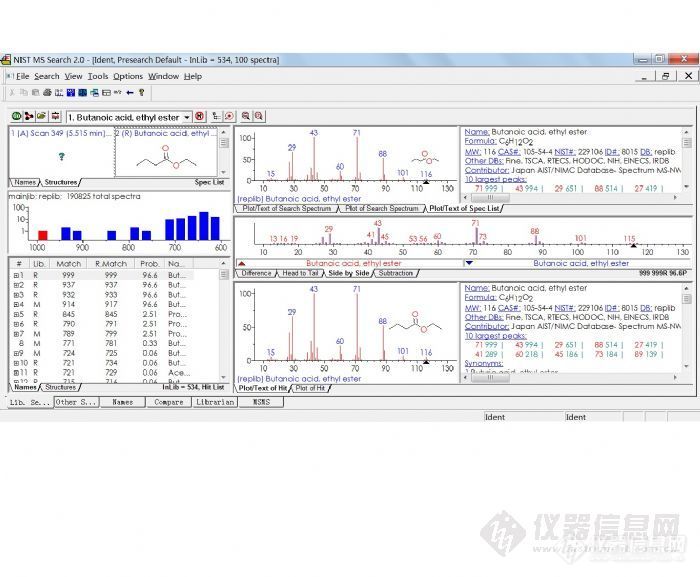
在NIST检索的结果里有Match(正检索匹配度,derect match), R . Match(逆检索匹配度,reverse Match)和Prob(概率, Probability)三个值。
其中Prob的值是从假定此化合物是在数据库中,以及仅仅依赖在命中列表中的邻近命中的差别得出。它从分析用主库(Mainlib)检索的结果与一组重建质谱图(在重建谱库给出)得出。
计算正向检索(标准库的峰与未知谱对照,看看谱库中是否存在与未知谱相同的参考谱图)的相似系数,即匹配概率或匹配率(匹配度)。计算反向检索(未知谱的峰与标准库对照,看看标准谱中的各质量峰是否出现在未知谱中。忽略在谱库不存在的未知谱上的峰。)的相似系数,即匹配概率或匹配率(匹配度)。
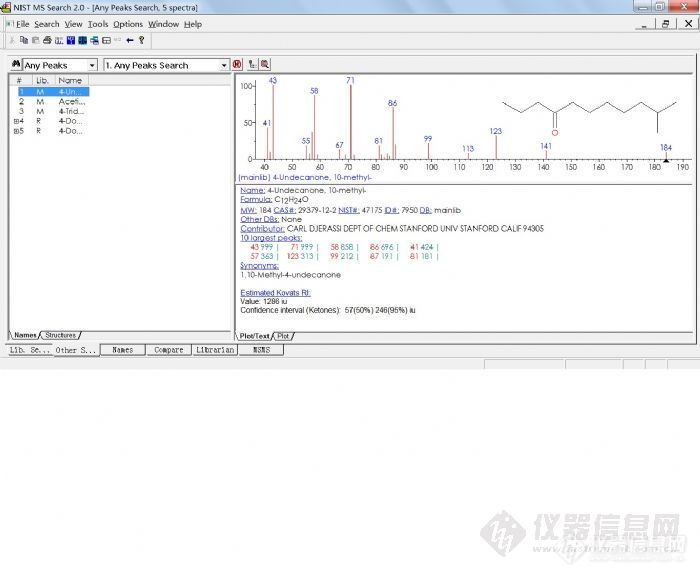
在NIST检索中匹配率最大为1000(相当PBM中100)。最好的结果是999,无峰的谱图是0。一般讲,900或更高,极好匹配; 800-900,良好匹配;700-800,尚可;低于600,差。
对正向检索来讲,任何峰只要在未知谱或标准谱中之一出现,都会降低匹配值。对反向检索而讲,任何峰只要在标准谱出现,而未知谱中没有,也会降低匹配值。
如果正向的匹配率低,反向的匹配率高,说明未知峰谱可能是混合物的谱图,或者本底干扰严重。
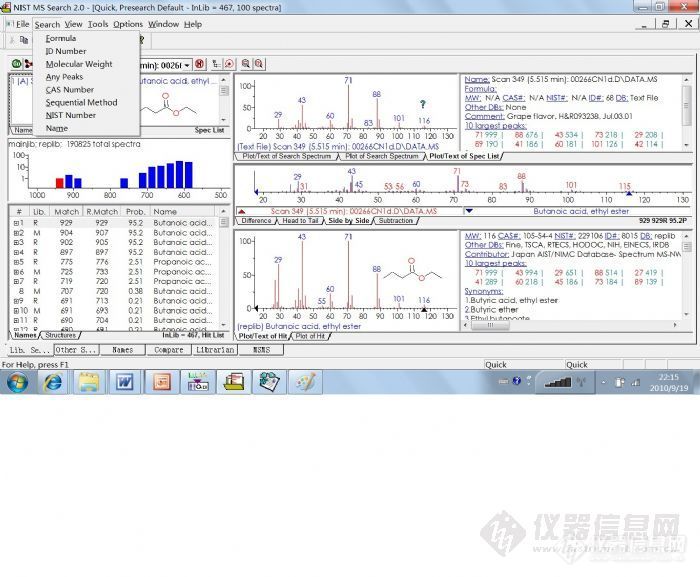
估计保留指数Estimated Kovats RI: Value: (例如丙二醇 724 iu)是从化合物的化学结构自动估计而来,稍有参考价值。而后面的文献的RI值是比较准,具有参考价值。
symmacros
第6楼2010/09/19
四.同位素计算 (Isotope Calculator)
点击Tools/ Isotope Calculate出现同位素计算窗口。
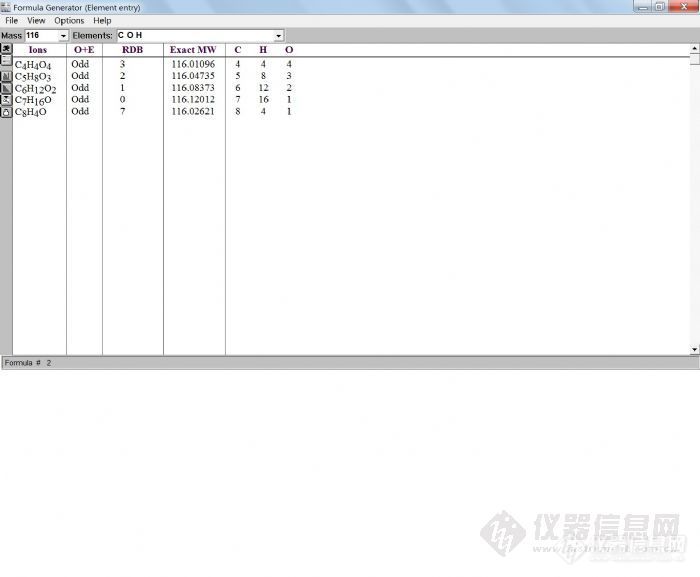
输入化合物分子式即可得到相应的同位素丰度。例如输入C6H12O2,可以看到:
质量数 丰度
116 100.00,
117 6.91819
118 0.60327
119 0.03082
以及120,121同位素的丰度
可以点击在某一质量数上点击,就可以把这个质量数的丰度作为100,其它质量数与其进行比较计算出相当丰度。即Max值。
再举个例子:C3H12Br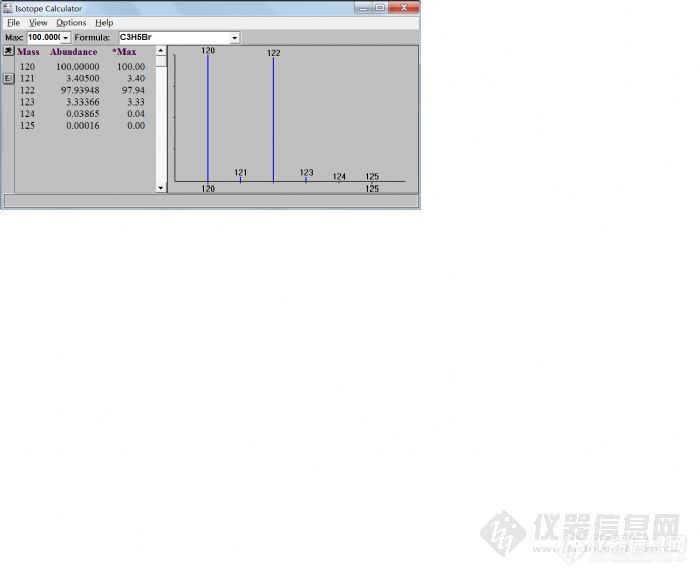
可以在Option菜单或通过左边的工具栏选择进入其它功能。
symmacros
第8楼2010/09/20
五.需要请教网友的问题
1. 想请教大家,如何导入质谱数据文件?
我是在安捷伦的工作站上安装Nist Search软件(嵌入整合到安捷伦里面),并从安捷伦的质谱数据分析(Data Analysis)的Spectrum菜单下的Nist Search进入Nist Search2.0的软件,来分析质谱数据。想请教大家,如果单独启动NIST Search的话(不通过安捷伦的工作站),质谱数据文件如何导入或调入到NIST Search里面?或者你们是怎样进入NIST Search的?谢谢。
用过一种方法是,从Amdis中进入Nist Search。Amdis是能够独立运行的软件。这样就不需要工作站。但Nist Search能不能单独运行还是不知道。
2. 除重建谱库是从主谱库复制而来, 数量少外,(Mainlib)和重建谱库(Replib)还有什么区别?
3. 只知道Estimated Kovats RI是从化合物的化学结构,如醇的结构,醛的结构等自动估计而来。请问哪位朋友知道是什么依据,计算公式来估计的?请问这个计算的原理,具体怎样计算,依据什么参数?
例如下面是丙二醇的估计保留指数。
Estimated Kovats RI:
Value: 724 iu
Confidence interval (Alcohols): 41(50%) 176(95%) iu
这里面的数字41(50%) 176(95%)是怎么来的?