

恨没早看见,一篇文章把误差讲透了

刘彦刚
第1楼2022/06/01
2、误差偶然(随机误差、不定误差)
偶然误差指,由于在测定过程中一系列有关因素微小的随机波动而形成的具有相互抵偿性的误差。
(1)误差偶然(随机误差、不定误差)特点误差偶然(随机误差、不定误差)特点就个体而言是不确定的,产生的的这种误差的原因是不固定的,它的来源往往也一时难以察觉,可能是由于测定过程中外界的偶然波动、仪器设备及检测分析人员某些微小变化等所引起的,误差的绝对值和符号是可变的,检测结果时大时小、时正时负,带有偶然性。但当进行很多次重复测定时,就会发现,误差偶然(随机误差、不定误差)具有统计规律性,即服从于正态分布。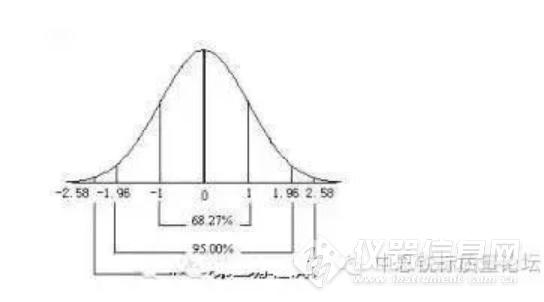
如果用置信区间〔-△、△〕,来限制这条曲线(因为我们不可将试验无限次的做下去,即使做得再多,检测结果的误差愈来愈接近于零,但永远也不会等于零),这样得到截尾正态分布,该正态分布图较好地描述了符合该类分布的偶然误差(随机误差,不定误差)出现的客观规律,且具有以下的基本性质(偶然误差的四性)。
a.单峰性:绝对直小的误差比绝对值大的误差,出现的机会多得多(±1σ占68.3﹪)b.对称性:绝对值相等的正、负误差出现的概率相等;c.有界性:在一定条件下,有限次的检测中,偶然误差的绝对值不会超出一定的界限;d.抵偿性:相同条件下,对同一量进行检测,其偶然误差的平均值,随着测量次数的无限增加,而趋于零。
抵偿性是偶然误差最本质的统计特性,凡有抵偿性的误差都可以按偶然误差处理。
显然,从误差的曲线本身就提供了决定了这类误差的理论根据,即用在相同条件下的一系列测量数值的算术平均值来表示分析结果,这样的平均值是比较可靠的。但,在实际工作中,进行大量的、无限次的测定显然是不真实的。因而,必须根据实际情况、根据对检测结果要求的不同,采取适当的检测次数。
采用数理统计方法以证明:
标准偏差在±1σ内的检测结果,占全部结果的68.3﹪;标准偏差在±2σ内的检测结果,占全部结果的95.5﹪;准偏差在±3σ内标的检测结果,占全部结果的99.7﹪;而误差>±3σ内的检测结果,仅占全部结果的0.3﹪;而且,由正态分布曲线可以看出,σ3 > σ2 > σ1,σ 值愈小,曲线愈陡,偶然误差的分布愈密集,反之,σ 值愈大,曲线愈平坦,偶然误差的分布就愈分散。
3、粗大误差(简称粗差、也称过失误差、疏忽误差)
粗大误差指,在一定测量条件下,测量值明显偏离实际值所形成的误差(亦称离群值)。
粗大误差指,明显超出测定条件下预期的误差,即是明显歪曲检测结果的误差。
(1)粗大误差的来源产生粗大误差的原因有主观因素,也有客观因素。例如,由于实验人员的疏忽、失误,造成检测时的错读、错记、错算或电压不稳定到致使仪器波动导致检测结果出现的异常值等。含有粗大误差的检测结果成为“坏值”,坏值应想办法予以发现和剔除。
(2)粗大误差的消除剔除粗大误差最常用的方法是莱依达(即3S)准则(3S即3倍的标准偏差),该准则要求检测结果的次数不能小于10次,否则不能剔除任何“坏值”,对于非从事计量检测工作而言,进行检验10次以上的分析化学不太现实,因此,我们采取4 法和Q检验法。在后面将逐一以介绍。
以上我们较详细的介绍了系统误差、偶然误差及粗大误差。区别三类误差的主要依据是人们对误差的掌握程度和控制的程度,能掌握其数值变化规律的,则认为是系统误差;掌握其统计规律的,则认为偶然(随机)误差;实际上未掌握规律的认为是粗大误差。由于掌握和控制的程度受到需要和可能两方面的制约,当检测要求和观察范围不同时、掌握和控制的程度也不同,就会出现同一误差在不同的场合下属于不同的类别。因而,系统误差与偶然误差没有一条不可逾越的明显界限(只能是一个过渡区)。而且,两者在一定条件下可能互相转化。
例如,某一产品,由于其用途不同其精度要求也不同,对于精度要求高的,出现的粗大误差,对于精度要求低的产品而言属于随机误差。同样,粗大误差和数值很大随机误差间的也没有明显的界限,也存在类似的转化。因而,如果想刻意的划定不同类别间的误差的界限,是没有必要的。
误差理论在质量控制中的应用
利用误差理论对日常检验工作进行质量控制,有着重要的意义。如在《实验室资质认定评审准则》的5.7结果质量控制中的5.7.1提出了质量控制的几种方法:
a.定期使用有证标准物质,开展内部质量控制;
b.参加实验室之间的比对或能力试验;
c.使用不同的方法进行重复性检测;
d.对留存样品进行再检测;
e.分析同一样品不同特性结果的相关性。
1、利用系统误差和偶然误差对日常检验工作进行质量控制
为保证检测结果的稳定性和准确性,通过用标准物质进行质量监控,具体的做法是:用一标准物质或用检测结果稳定、均匀的在有效期内的样品,在规定的时间间隔内,对同一(标物)样品进行重复检测,将检测结果汇成曲线。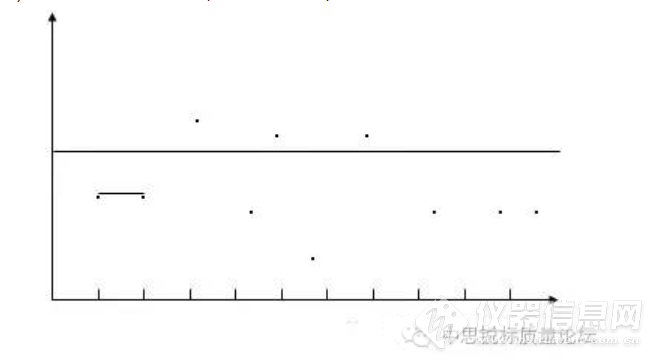
通过坐标上检测点的结果,将其联成线,通过曲线可判定误差的类型:
a.假设我们每10天检测一次,共有10个点,而这10个点在标准值之间上下波动,无规律可言,则说明是偶然误差,是正常状态;
b.当检测的结果呈现出规律性,或在真值线以上、或在真值线以下、或呈现一条斜线,则视为出现了系统误差,这种情况下,应查找出现系统的原因,并找到消除系统误差的原因。
2、参加实验室间比对和能力验证
a.实验室间比对
参加实验室之间的比对,也是进行质量控制的一种方法,在进行实验室比对时,应充分考虑比对样品的均匀度及稳定性,如果比对样品满足不了以上条件,则比对结果毫无意义。
b.能力验证
利用实验室检测数据的的比对,确定实验室从事特定测试活动的技术能力。能力验证一般由省级以上技术监督局或国家认监委组织。
3、使用不同的方法进行重复性检测
通过使用不同的检测方法,用同一样品、同一检测人员、相同环境条件下进行的重复性检测,以减少检测方法带来的系统误差。
4、对留存样品进行再检测
对留样进行再检测,即实验室资质认定现场考核方法之一,称之为“样品复测”。样品复测包括“盲样检测”即用已知结果的标准物质进行的检测;另一种样品复测的方法,即在样品的有效期内,对样品进行的再检测。样品的再检测是考核样品结果的复现性或再现性,即在不同时间、不同人员(也可是原检测人员)、不同地点及不同检测方法等,通过样品的复现性用以考核检测人员独立操作的能力,通过结果误差的分析,对实验室的质量进行有效控制。
5、分析同一样品不同特性结果的相关性
每个产品或样品的各项结果都有相关性,正如人的正常高度和体重有一定的比例一样,当过重或过轻都不正常一样。如酱油的全氮与氨基酸态氮有一定的比例关系,其关系为正比关系、电流和电阻有一定的关系,其关系是反比关系一样,任何样品或产品不同特性结果都有相关性,通过特性结果的相关性,可判断产品的正常与否,正如一份发酵酒,如果它的固形物很低,而含糖量又符合要求,其特性结果的相关性存在问题,就应考虑产品的质量问题了。内容来源:网络 由小析姐整理编辑
刘彦刚
第3楼2022/06/03
应该没有必要提供充分的数据,来证明“准确度高,精密度必然好”。再给出一下两定义:
1、准确度准确度指,检测结果与真实值之间相符合的程度(检测结果与真实值之间差别越小,则分析检验结果的准确度越高)。
2、精密度精密度指,在重复检测中,各次检测结果之间彼此的符合程度(各次检测结果之间越接近,则说明分析检测结果的精密度越高)。
例如:由准确度等级给出:最大允许误± 0.01,那么一般来说,其精密度应该使其测量结果相差应该在-0.01~+0.01间吧。否则怎么保证最大允许误± 0.01呢!
路云
第4楼2022/06/03
你这个最大允许误差±0.01,通常是指误差的最佳估计值(或者是多次误差测量结果的平均值)落在该范围内,是对偏移程度的约束,并非对离散程度的约束。否则为什么规程/规范除了有最大允许误差技术要求外,还有“示值重复性”(或“示值变动性”)要求呢?“示值误差”满足要求,“示值变动性”就一定满足要求吗?如果一定能满足要求,那规程/规范就没有必要规定和检测这一离散性指标了。
举例来说,假如某仪器的最大允许误差为±1.0,实际误差为+0.1,应该说准确吧。但实际误差的波动范围从-0.9~+1.0,尽管都满足±1.0的要求,但离散区间的宽度高达1.9。您说报告这台仪器“实际误差+0.1,示值变动性1.9”的测量结果可靠吗?
再比如另一台同型号同规格的,示值重复性(或示值变动性)非常小的仪器,实际示值误差也是+0.1,但实际误差的波动范围在0.0~+0.2之间,离散区间的宽度只有0.2。相比前一台仪器,报告它“实际误差+0.1,示值变动性0.2”的测量结果的可靠程度就要高得多。
对比这两个案例就不难证明,“准确度高,精密度必然好”这句话是不成立的。不要忘了,偏移性和离散性是完全不同的两个概念,前者表示的是“准确度”,后者表示的是“精密度”(或者叫“可靠度”,也叫“离散度”),定量表征前者的指标是“误差”,定量表征后者的是“重复性”。“误差”没有表示离散程度的功能,“重复性”也没有表示准确程度的功能。两者不容混淆。

































