
基于质谱的内源性抗体从头测序的展望


导读:尽管从抗体混合物中重新组装序列仍然是艰巨的任务,但一些研究团队最近已经设法获得了令人兴奋的数据。随着现有方法的众多进步,很可能只需把这些碎片拼凑在一起,创建一个基于MS的方法,以更常规地用于抗体发现。
大家好,本周为大家分享一篇发表在mAbs上的综述,A perspective toward mass spectrometry-based de novo sequencing of endogenous antibodies1,通讯作者是来自荷兰乌得勒支大学Bijvoet生物分子研究中心的Albert J.R. Heck。
据估计,人体可以产生的抗体理论序列超过1015种,这些序列是独一无二但又高度相似的,这使得它们的表征和测序非常复杂。抗体的结构从功能上分为Fab段和Fc段,其中Fab负责与抗原结合,具有高度变异性,这种突变主要集中在Fab段的互补决定区(CDR),阐明这部分的序列对抗体的发现非常重要。 图1展示了用于抗体序列分析的三种组学策略。Bottom-up(BU)是最流行的测序方法,可以通过数据库匹配或完全的从头测序实现对抗体的序列分析,但主要用于高度纯化的重组抗体。第二种策略是通过将基于MS的技术与基因组学/转录组学相结合,例如全基因组测序或 BCR 测序,通过B细胞测序生成个性化序列数据库,将BU MS数据靶向该数据库搜索,是一个部分从头测序的流程。第三种策略是结合几种基于MS的de novo方法,如Top-down(TD)和Middle-down(MD),旨在直接从临床样本中确定选定抗体克隆的完整序列,而无需其他组学数据的帮助。
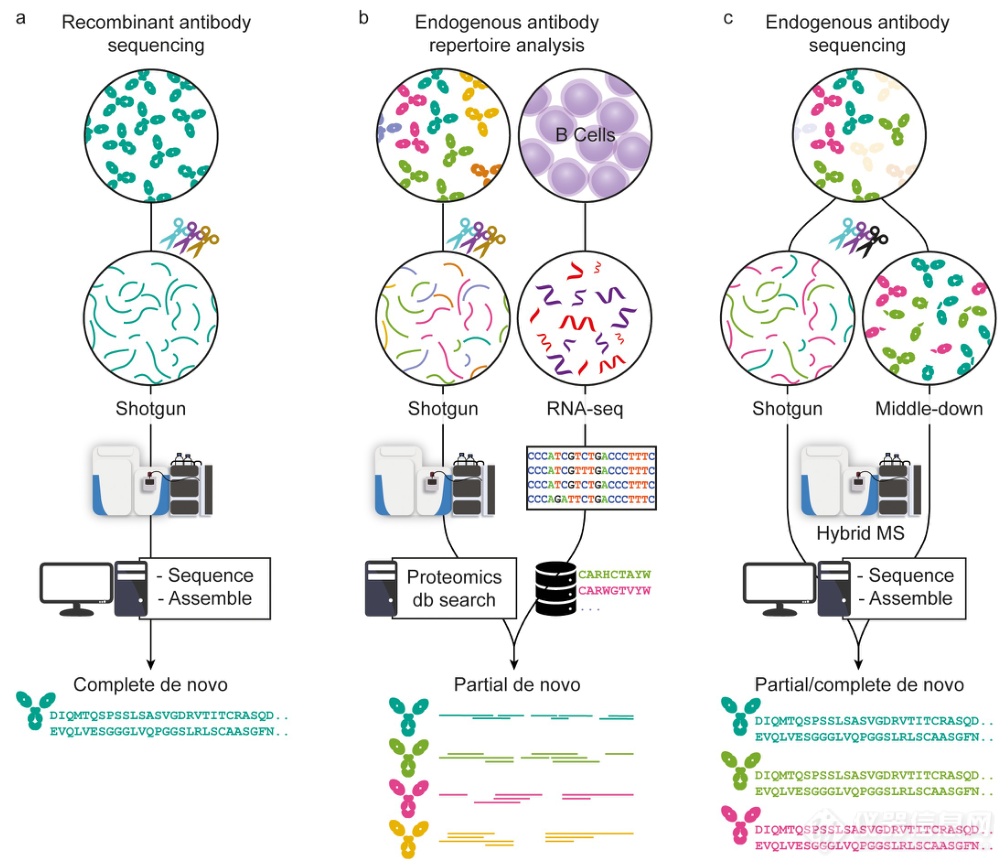
图1 基于MS的抗体测序的三种策略
通过BU方法进行的从头测序需要高度的序列覆盖,理想情况下,抗体中的每个序列位置都由多个重叠的肽段支持。通过缩短酶的孵育时间、微波辅助水解,或使用具有协同序列特异性的多种酶,可以产生较长的肽段或较多的重叠序列。图2所示的工作使用总共9种蛋白酶(包括特异性和非特异性)成功地从头测序抗 FLAG-M2小鼠mAb全长。通过覆盖整个CDR的高分肽获得了高置信度的CDR序列,所选择的6条肽段来自5种不同蛋白酶的消化。
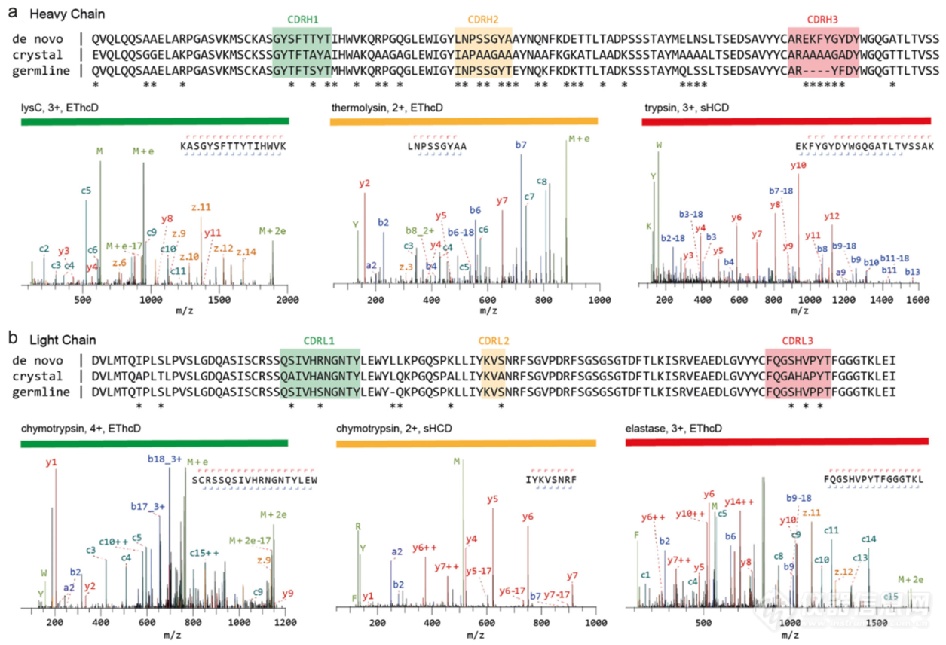
图2 单克隆抗体Anti-FLAG M2的测序。
对于抗体这种具有高度变异性的蛋白质,通常无法获得完整和准确的序列数据库来进行匹配。相反,可以使用来自基因组或转录组实验的同源序列。抗体种编码每个区域的基因可作为种系序列获得,基于序列对齐或序列标签提取的容错片段匹配算法可以使用同源数据库对实验确定的序列进行评分。同源序列数据库还可以作为种系模板来辅助从头测序肽段的组装。
TD/MD策略虽存在对分子量较大蛋白的电离效率低、分辨率低等限制,但近年该领域的一些进展也报告了相对较高的序列覆盖率。Shaw 等人报道了使用现代仪器将完整的 mAb 在非变性状态下片段化(图3)。通过在单个串联 MS 实验中结合 ECD 和 HCD,获得了曲妥珠单抗 42% 的轻链序列覆盖率和 20% 的重链序列覆盖率。产生的碎片谱不仅包含多电荷主链碎片产物,还包含链间二硫键断裂产生的完整轻链。
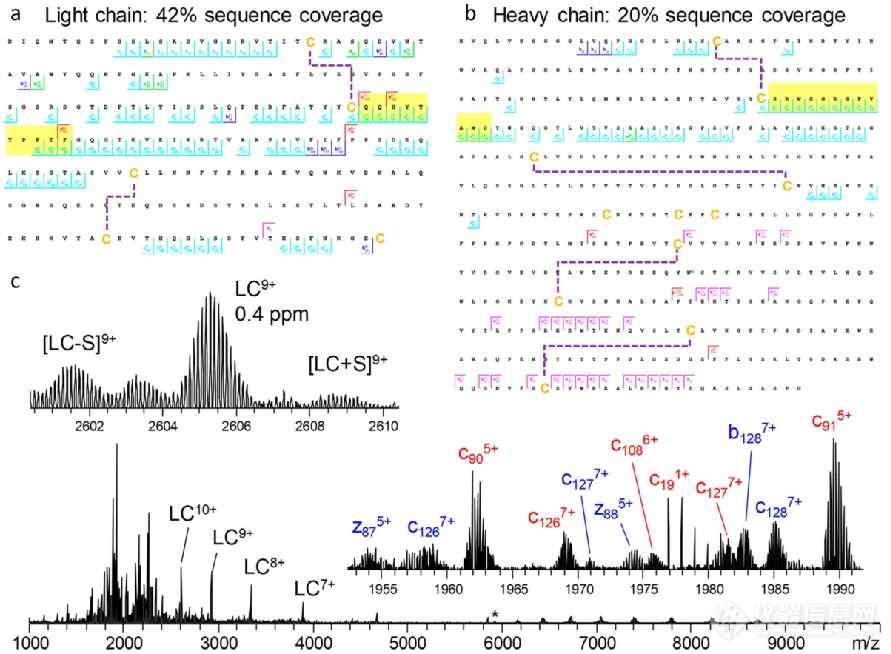
图3 轻链 (a) 和重链 (b) 片段图显示了曲妥珠单抗上 ECD 和 HCD 组合产生的序列覆盖率。二硫键用虚线表示,CDR3 区域以黄色高亮显示。(c)为完整曲妥珠单抗的 25+ 电荷态的相应碎片谱,插图显示了轻链的 9+ 电荷态和各种碎片离子。红色和蓝色碎片离子标签分别对应轻链和重链。星号表示质量选择的母离子。
将抗体测序拓展到内源性抗体存在许多挑战。首先,血浆中单个克隆的中位浓度约为 1 µg/mL,比 mAb 低几个数量级,并且单个克隆的分离极具挑战性,使测序过程进一步复杂化;因为大多数软件工具专为组装单个抗体而设计,当数据代表几个相似的 Ig 序列时可能导致分析失败。此外,在复杂的内源性多克隆抗体混合物中,由于来自恒定区的序列信息被放大并抑制CDR的信号,因此通常无法检测到CDR区的关键序列。使用多组学方法,例如通过使用来自同一供体的基因组学或转录组学数据补充 BU MS 数据,可以绕过从头测序的一些具有挑战性的方面。
Guthals等人报道了一个例子,使用糖蛋白B抗原从患者的血清中纯化抗体后,进行了完整质量和BU MS分析(图4c)。通过半自动软件PolyExtend用完整质量来检索抗体混合物中最丰富的物种的平均质量,并以此来约束BU MS数据导出的序列结果。在最近的一项研究中,Bondt等人从败血症患者的血清中制备IgG1的Fab亚基,成功地在不经过抗原特异性捕获的条件下,通过MD/BU结合和ETD活化的MS方法,在一个供体的血清中直接对一个高丰度的抗体克隆进行从头测序(图4d)。首先,从IMGT数据库中选择高度匹配的轻链和重链种系模板。然后用采集的从头测序数据来迭代和改进这些模板,产生最终的成熟序列。值得注意的是,确定的序列包含的突变比BCR测序研究报告的突变率所预期的要多,这表明蛋白质水平测序和基因水平测序之间存在潜在的差异。
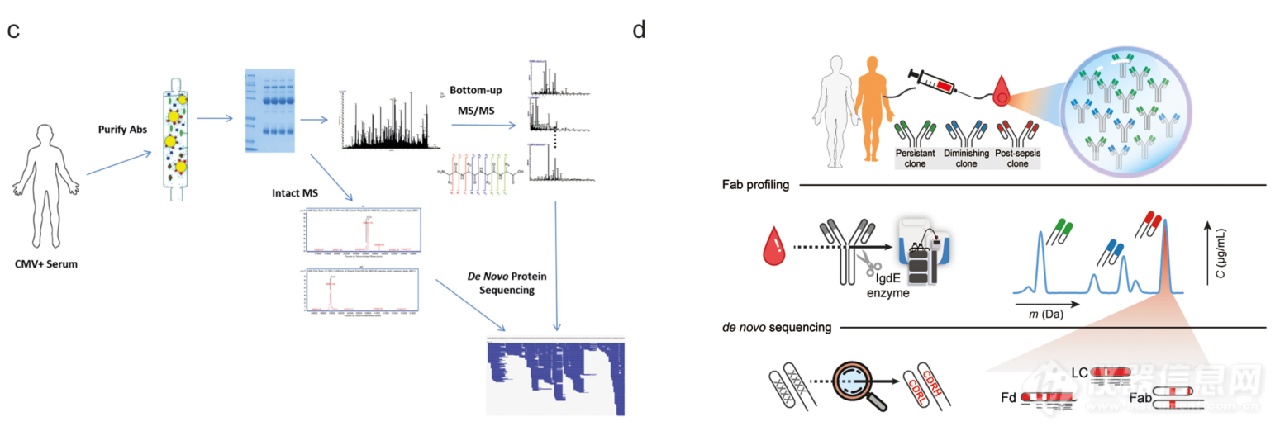
图4
尽管从抗体混合物中重新组装序列仍然是艰巨的任务,但一些研究团队最近已经设法获得了令人兴奋的数据。随着现有方法的众多进步,很可能只需把这些碎片拼凑在一起,创建一个基于MS的方法,以更常规地用于抗体发现。所有近期发表的这些策略概念的验证为更高效的下一代方法铺平了道路。
来源于:仪器信息网













热门评论
最新资讯
新闻专题
更多推荐
