
GlycoSLASH:用谱聚类和谱库搜索从多个相关的LC-MS/MS数据集同时鉴定糖肽
导读:目前,对从疾病患者样本中获得的大规模糖蛋白组数据进行糖肽鉴定仍有较大难度。现有的算法采用了从少量聚糖和糖肽的注释MS/MS谱中得出的经验性和针对性的评分方案,它们也许并不能很好地推广到其他糖肽的谱图。
大家好,本周给大家分享一篇发表在Journal of Proteome Research上的文章,GlycoSLASH: Concurrent Glycopeptide Identification from Multiple Related LC-MS/MS Data Sets by Using Spectral Clustering and Library Searching[1],本文的通讯作者是来自美国印第安纳大学的Haixu Tang教授。
目前,对从疾病患者样本中获得的大规模糖蛋白组数据进行糖肽鉴定仍有较大难度。现有的算法采用了从少量聚糖和糖肽的注释MS/MS谱中得出的经验性和针对性的评分方案,它们也许并不能很好地推广到其他糖肽的谱图。其次,估算糖肽鉴定中的错误发现率(FDR)的方法尚未得到系统验证,有时可能会高估鉴定结果中的FDR。此外,大规模的人类糖蛋白组学实验可以生成数十到数百个个体疾病或对照样品的数据集,通常包含来自这些样品中不同丰度的相同聚糖/糖肽的许多谱图,然而在这些基于队列的相关研究中,缺乏能够利用冗余信息来改进和加快糖肽识别的算法。本文提出了一种名为GlycoSLASH的新型并行方法,通过谱聚类和谱库搜索在多个相关糖蛋白组学数据集中进行糖肽鉴定,利用相关样本中共享的冗余糖肽来改善鉴定结果。

图1. GlycoSLASH的工作流程:使用谱库搜索并发糖肽鉴定
GlycoSLASH工作流程如图1所示。首先,使用msCRUSH算法对输入数据集中的所有MS/MS谱进行聚类,并为每个聚类生成共识谱。根据置信度优先的标准,排除相对模糊的糖肽鉴定(GSM)后,可以发现,谱聚类减少了糖肽的错误识别,从而在多个样品中产生一致的糖肽识别结果。随后将从标记为糖肽或多肽的聚类中获得的共识谱整合到谱库中。最后,使用谱库搜索算法msSLASH对所有输入谱库中的MS/MS谱进行糖肽鉴定,与糖肽谱库中的共识谱一样具有大于阈值的余弦相似度的MS/MS谱则被识别为标记的糖肽。具有相似阈值的谱库搜索结果的FDR可以通过同时进行的多肽鉴定结果来估计:如果MS/MS谱被数据库搜索算法鉴定为未修饰的肽,但与注释为糖肽的共识谱具有大于阈值的相似度,则认为是错误鉴定。
作者用了两种数据集来评估GlycoSLASH的性能:数据集I研究了丙型肝炎病毒(HCV)相关肝硬化和早期肝细胞癌(HCC)患者血液样本中触珠蛋白的位点特异性N -糖基化;数据集II利用相同的实验方案研究肝硬化、早期和晚期HCC合并非酒精性脂肪性肝炎患者的触珠蛋白中位点特异性N-糖基化。首先使用数据集I的MS/MS谱建立了一个糖肽谱库,然后通过该谱库对数据集I和II进行搜索来鉴定糖肽。由于数据集I和II是使用相同的实验方案从人血清中获得的,由此可以测试从一个数据集建立的谱库是否足以从相关数据集进行糖肽鉴定。
表1. 基于数据集I聚类构建的谱库

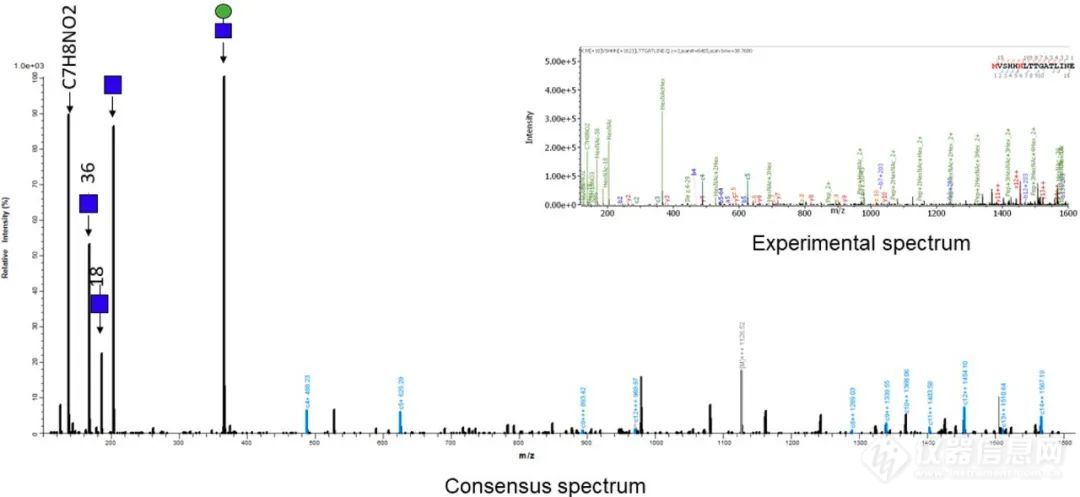
图2. 一个共识谱的例子,与识别为K.M[+15.99492]VSHHN[+1622.58161]LTTTGATLINE.Q的单个谱进行比较。该聚糖是HexNAc(4)Hex(5)。作者利用具有+2至+5电荷的质谱簇的共识谱构建了一个谱库,这些质谱簇被注释为无修饰的肽或糖肽。该谱库包括1215个代表2+至5+电荷簇的质谱(表1),其中454个被注释为糖肽。图2展示了一对共识谱和单个谱的注释示例。此外,作者利用MASCOT和Byonic的鉴定结果对质谱簇的纯度进行了检测。在这里,纯度是根据参考文献msCRUSH中描述的公式计算的,其中被Byonic识别为糖肽的簇中的质谱和被MASCOT识别为未修饰肽的簇中的质谱被认为是不同的。纯度表示簇中可能被错误识别的质谱的平均百分比;因此,在构建共识谱之前对这些GSM进行了过滤。图3显示了不同相似度截断值下每个质谱簇的纯度值。例如,当相似度截断值为0.6时,3+电荷的聚类纯度为0.97,4 +电荷的聚类纯度为0.85,当相似截断值提高到0.8时,聚类纯度基本保持不变。
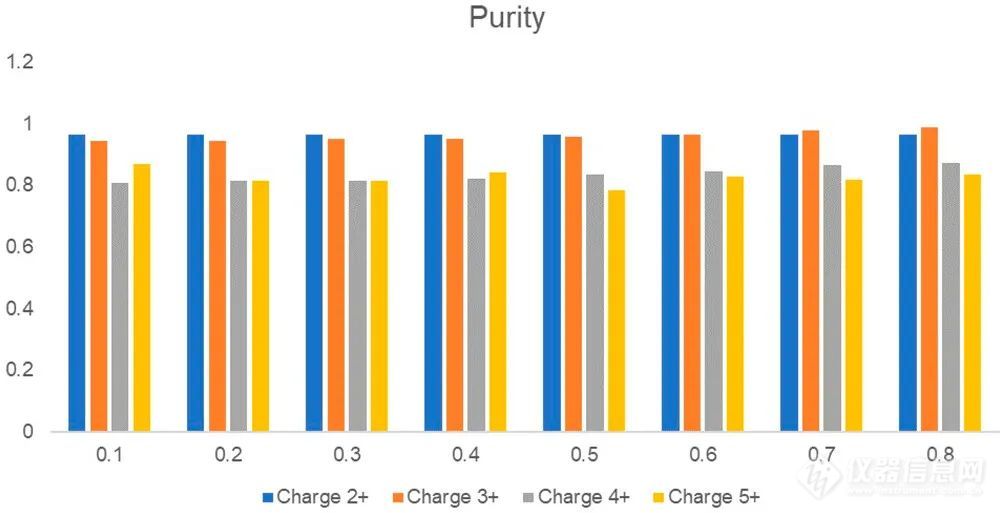
图3. 每个电荷具有不同相似度截断值的质谱簇纯度。y轴表示纯度,x轴表示用于谱聚类的相似度截断值。
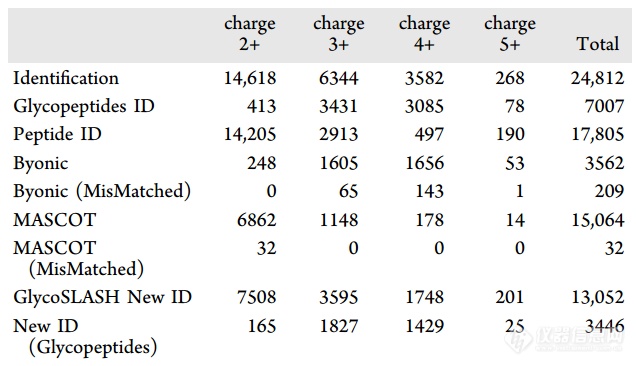
将构建的谱库用于数据集I和II中每个样品的糖肽鉴定。被查询的MS/MS谱根据谱库中(在高于截断值的基础上)相似度最高的共识谱的注释来鉴定。表2显示了数据集I中不同电荷的MS/MS谱的鉴定。GlycoSLASH在3+和4+电荷的MS/MS谱中分别将3431和3085个谱图鉴定为糖肽。相比之下,Byonic鉴定了1605个3+电荷的糖肽,其中1517个与GlycoSLASH鉴定的糖肽相同。
表2 GlycoSLASH在数据集I上鉴定多肽和糖肽
通过比较GlycoSLASH(使用相同的相似度截断值0.6)和MASCOT对未修饰肽的鉴定结果来估计谱库搜索的FDR,对于电荷2+的二级谱,MASCOT识别出6862个未修饰的肽,其中只有32个(0.05%)与GlycoSLASH的识别结果不同。在电荷为 3+ 和 4+ 的情况下,两者鉴定的所有未修饰肽的结果相同。如果报告的谱库与查询谱之间的相似度大于截断值(0.6),并认为MASCOT鉴定结果全部正确,那么鉴定到不同肽的比例远低于1%。基于此,可以认为在截断值0.6时谱库搜索的FDR远低于1%。
通过对从数据集I构建的谱库搜索来识别数据集II中的糖肽,GlycoSLASH的鉴定结果如表3所示。通过谱库检索,共鉴定出72,784个多肽,其中32.3%为糖肽,共鉴定出270个独特的糖肽。这些结果和识别率与数据集I的结果具有可比性。
表3 GlycoSLASH在数据集II上鉴定多肽和糖肽

作者在本研究中证明了从一个数据集建立的谱库足以从相关数据集中识别糖肽。这项工作着重分析了免疫纯化的糖蛋白中的N糖肽,然而,谱库搜索方法可以扩展到复杂样品的一般糖蛋白组学研究,只要能够获得来自相关样品的多个糖蛋白组学数据集。利用这样一个全面的文库进行谱库搜索,将进一步提高糖蛋白组学数据中糖肽的鉴定。
撰稿:夏淑君
编辑:李惠琳
文章引用:GlycoSLASH: Concurrent Glycopeptide Identification from Multiple Related LC-MS/MS Data Sets by Using Spectral Clustering and Library Searching
李惠琳课题组网址www.x-mol.com/groups/li_huilin
参考文献
1. Sujun Li, Jianhui Zhu, David M. Lubman, He Zhou, and Haixu Tang. Journal of Proteome Research 2023 22 (5), 1501-1509
来源于:仪器信息网


李惠琳课题组
总阅读量 0






仪器优选·液质联用仪
更多




相关会议
更多




热门评论
最新资讯
新闻专题
更多推荐
