基于“吸光度-浓度变化率”波段选择方法提高近红外光谱建模能力
近红外光谱定量分析是一种二级分析方法,利用校正模型对未知含量或性质参考值的样品基于近红外光谱数据进行预测,以测定未知待测样品的浓度或性质参考值,根据预测结果评价模型的预测能力和有效性。由于近红外光谱吸收峰严重重叠,信号吸收较弱,背景干扰严重。因此需要运用波段选择方法提取有效波段,常用的波段选择方法包括前向间隔偏最小二乘法(forwardintervalpartialleastsquares, FiPLS)、反向间隔偏最小二乘法(backwardintervalpartialleastsquares, BiPLS),相关系数法(correlationcoefficient, CC)和无信息变量消除算法(uninformativevariableelimination, UVE)等。
本实验对近红外建模物质的浓度与吸光度的变化率进行研究,提出了新的波段选择方法:“吸光度-浓度变化率”方法(Ratioof absorbance to concentration,RATC),弥补了常用波段选择的缺陷,构建了血浆蛋白含量检测模型。
1材料
1.1试剂
血浆样品(山东泰邦生物制品有限公司,中国);去离子水。
1.2仪器和软件
AntarisⅡ傅里叶变换近红外光谱仪,液体采样附件;液体玻璃小管(4×50mm,KimbleChase 德国);Matlab2015a(美国Mathworks公司);PLS_Toolbox工具箱(美国EigenvectorResearch)。
2方法
2.1光谱采集
采用傅里叶变换近红外光谱仪(Antaris II FT-NIR)液体温控透射采样模块,控制温度为37℃下,采集原料人血浆样品光谱。光谱扫描范围和分辨率为10000-4000cm-1和8cm-1,扫描次数为32次,参比为空气,每隔1小时校正背景。实验室环境为温度26℃,湿度30%。
2.2 校正集验证集划分方法
需要划分校正集和验证集的样品:原料人血浆样品20份,近红外光谱建模属性为总蛋白含量值;
2.3 数据处理及模型建立
研究采用MATLAB2015a数学软件以及PLS_Toolbox 1.95工具箱对光谱数据进行处理,对建模物质的吸光度和浓度进行变化率分析,选出用于建模的波数点,针对近红外光谱分析技术的建模分析,以验证均方根误差(RMSEP)值作为其建模预测能力的主要指标。通过讨论不同物质的近红外光谱分析模型建模结果,验证所提波段选择方法的可行性和应用性。
3 “吸光度-浓度变化率”波段选择原理及方法
本文提出了一种近红外光谱模型的波段选择方法,基于“吸光度浓度变化率”对校正样品集中所有样品进行波段选择,其具体过程为:
步骤1:预先设定校正样品集中共有n个样品,每个样品光谱中共有N个变量,对于校正样品集所有样品来说,每个变量则有n个吸光值和n个浓度值;其中,N和n均为大于1的正整数;
步骤2:依次计算每个变量下相邻样品的吸光值差值和浓度差值的比值V,最终在每个变量下得到(n-1)个比值V,再计算所有比值V的平均值Vmean;
Vi=|(Ai-Ai+1)|/(Ci-Ci+1) ; (1)
Vmean= (2)
(2)
Ai表示第i个样品的吸光值,Ai+1表示第i+1样品的吸光值;
Ci表示第i个样品的浓度值,Ci+1表示第i+1个样品的浓度值;
V1表示第1个样品与其相邻的第2个样品的吸光值差值和浓度差值的比值;
V2表示第2个样品与其相邻的第3个样品的吸光值差值和浓度差值的比值;
V3表示第3个样品与其相邻的第4个样品的吸光值差值和浓度差值的比值;
V4表示第4个样品与其相邻的第5个样品的吸光值差值和浓度差值的比值;
Vn-1表示第n-1个样品与其相邻的第n个样品的吸光值差值和浓度差值的比值。
步骤3:对于校正样品集中样品光谱的N个变量来说,得到N个Vmean值,将N个变量按照其Vmean值进行排序;
步骤4:按照Vmean值由大变小的顺序依次选择出相应变量,直至所有变量全部选完,停止建模,记录所有情况的建模结果。
其中,Vmean值越大,则代表吸光值因浓度变化所产生的响应越大,同时Vmean即为所提出的波段选择方法的关键值,命名为“吸光度-浓度变化率”值。从Vmean值最大的变量开始建模,随后按照Vmean值由大变小的顺序,采取依次增加一个变量的方法,开始建立近红外光谱模型,简化流程图如图4-1所示。
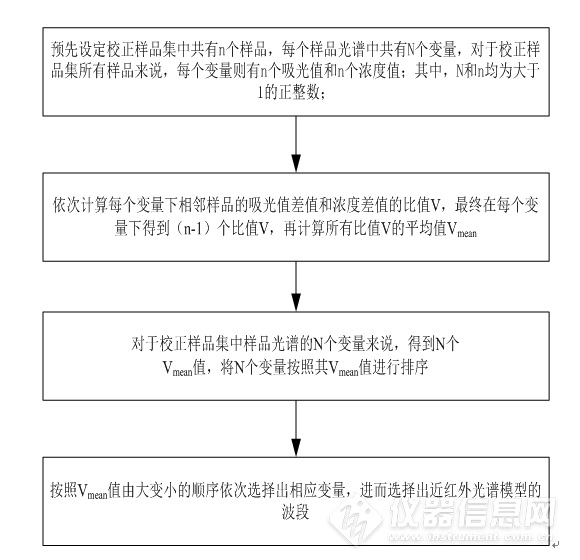
图4-1“吸光度-浓度变化率”波段选择方法简化流程图
具体应用例证如图4-2所示:校正样品集有20个样品,其浓度值分别为C1,C2,…,C20。

图4-2“吸光度-浓度变化率”波段选择方法具体例证过程
本文将所提出的波段选择方法用于血浆蛋白含量检测模型的构建中,讨论血浆蛋白含量变化同样品吸光度之间的变化率,进而选择合适的波段用于建模。
4 实验结果
4.1 近红外建模样品集划分
对三种样品进行校正集和验证集的划分结果如表4-1所示,其结果全部满足验证集的参数值范围在校正集之内,同时对于不同样品的不同属性的校正集和验证集来说,其平均值和标准偏差值也比较接近,满足近红外光谱建模校正集和验证集的划分要求。
表4-1不同样品不同属性的校正集验证集数据统计结果
| 样品 (检测参数) | 样品集 | 样本数 | 最大值 | 最小值 | 平均值 | 标准偏差 |
| 原料人血浆 (蛋白含量值) | 校正集 | 15 | 76.80 | 40.56 | 59.34 | 12.31 |
| 验证集 | 5 | 73.16 | 41.89 | 57.56 | 11.65 |
| 玉米 (水分值) | 校正集 | 60 | 10.99 | 9.38 | 10.22 | 0.39 |
| 验证集 | 20 | 10.94 | 9.64 | 10.27 | 0.36 |
| 玉米 (蛋白质含量值) | 校正集 | 60 | 3.83 | 3.09 | 3.50 | 0.18 |
| 验证集 | 20 | 3.82 | 3.18 | 3.48 | 0.18 |
| 玉米 (油脂值) | 校正集 | 60 | 9.71 | 7.66 | 8.73 | 0.53 |
| 验证集 | 20 | 9.60 | 8.11 | 8.49 | 0.32 |
| 玉米 (淀粉值) | 校正集 | 60 | 66.47 | 62.83 | 64.62 | 0.90 |
| 验证集 | 20 | 65.60 | 63.63 | 64.91 | 0.48 |
| 汽油 (辛烷值) | 校正集 | 45 | 89.60 | 83.40 | 87.15 | 1.57 |
| 验证集 | 15 | 88.70 | 84.50 | 87.25 | 1.46 |
4.2 血浆样品近红外光谱建模结果
4.2.1“吸光度-浓度变化率”方法在血浆蛋白含量建模中的应用
利用“吸光度-浓度变化率”方法对血浆样品进行数据分析,得到每个波数点下的Vmean值如图4-3所示,按照其Vmean值由大到小排列波数点,依次递增波数点个数进行建模,即得到不同近红外光谱模型结果。
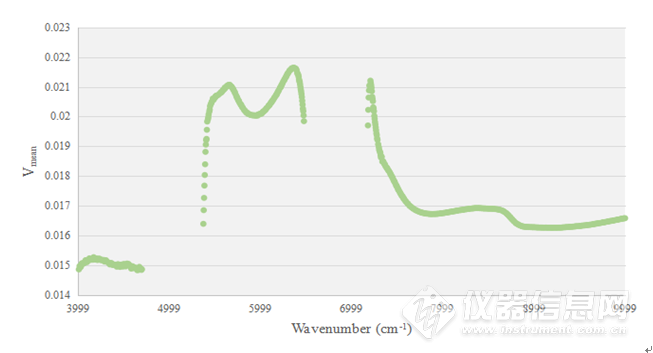
图4-3血浆样品不同波数点的Vmean值
近红外光谱血浆蛋白含量建模结果如图4-4所示,最小的RMSEP值为0.495,模型的RPD值为23.535>3,无模型过拟合现象,所涉及变量数为50个,具体波数点如表4-2所示。获得最佳模型的波数点大部分都分布在6200-6400cm-1,分析此处的特征吸收峰信息,多为N-H的一级倍频信息。
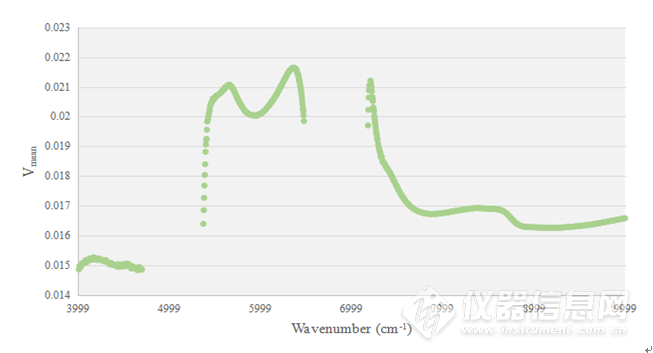
图4-4 血浆蛋白样品近红外光谱分析技术的建模结果
表4-2血浆蛋白样品进行近红外光谱分析技术的建模变量
| 波数(cm-1) | 波数(cm-1) | 波数(cm-1) | 波数(cm-1) | 波数(cm-1) |
| 6363.940 | 6360.083 | 6321.514 | 6294.515 | 6267.517 |
| 6367.797 | 6387.082 | 6317.657 | 6414.080 | 6425.651 |
| 6371.654 | 6390.938 | 6313.800 | 6417.937 | 6263.660 |
| 6356.226 | 6340.798 | 6402.509 | 6290.658 | 6259.803 |
| 6375.511 | 6336.941 | 6309.943 | 6286.801 | 7208.608 |
| 6352.369 | 6329.228 | 6406.366 | 6282.944 | 6255.946 |
| 6348.512 | 6333.084 | 6306.086 | 6421.794 | 6429.508 |
| 6379.368 | 6398.652 | 6302.229 | 6279.087 | 6252.089 |
| 6383.225 | 6394.795 | 6410.223 | 6275.230 | 7204.751 |
| 6344.655 | 6325.371 | 6298.372 | 6271.374 | 6433.365 |
4.2.2 同常规波段选择方法的近红外光谱建模比较
为考察“吸光度-浓度变化率”方法的预测能力高低,将其同其他常规变量选择方法 (FiPLS, BiPLS, CC, UVE) 对相同光谱数据进行处理,建立的近红外模型结果对比如图4-5所示。从图4-5中可明显看出,同其他变量选择方法相比,RATC得到了最小的RMSEP值(RMSEP=0.495g/L)。综上所述,对于原料人血浆样品的总蛋白定量来说,RATC方法减少了参与近红外光谱建模的变量数,提高了血浆蛋白含量建模的预测能力,是一种有效的变量选择方法。

图4-5 不同血浆蛋白含量的近红外光谱建模结果比较
5小结
本文基于吸光度浓度变化率来对校正样品集中所有样品进行波段选择;其过程为:预先设定校正样品集中共有n个样品,每个样品光谱中共有N个变量,对于校正样品集所有样品来说,每个变量则有n个吸光值和n个浓度值;其中,N和n均为大于1的正整数;依次计算每个变量下相邻样品的吸光值差值和浓度差值的比值V,最终在每个变量下得到(n-1)个比值V,再计算所有比值V的平均值Vmean;对于校正样品集中样品光谱的N个变量,得到N个Vmean值,将N个变量按照其Vmean值进行排序;按照Vmean值由大变小的顺序依次选择出相应变量,直至所有变量全部选完,停止建模,记录所有情况的建模结果。
同常规波段选择方法比较,该方法从三个方面进行了改进,不仅减少了参与近红外光谱建模变量的数目,提高了近红外光谱模型的预测能力。丰富了近红外光谱模型的波段选择方法,给近红外光谱模型使用者提供“吸光度-浓度变化”波段选择方法。同时由于是根据物质的近红外光谱吸光度和浓度的关系建立的波段选择方法,某种程度上,该方法更能够反应物质的化学信息,即吸光度随着浓度变化率,使得该波段选择方法具有广泛的可行性和通用性。



































