推荐厂家
暂无
暂无




蛋白质与多肽蛋白质粉 人类的营养物质有许多种类,最为重要的为蛋白质,碳水化合物和脂肪,其它则是微量营养物质,如维生素、电解质和微量元素等。虽然每一种营养物质对人体来说都是不可或缺的,但绝大多数的营养学家都会有充分的理由认为,真正最重要的营养物质是蛋白质。一、蛋白质是构成人体的基本物质。 蛋白质是由氨基酸通过肽链相连而构成的,它是人体包括骨骼、肌肉、皮肤和脑的重要物质基础,同时氨基酸也是生成核酸的基本物质。我们知道,核酸既形成遗传密码,也是体内储存能量的基本物质。因而从根本上说,人体是由蛋白质组成的。构成人体蛋白质的生理功能概括有如下三个方面:1)人体组织的主要构成成份:如肌肉、骨骼、血液、皮肤、神经、肝、心等等。2)具有特殊生理功能:可以这样说,人类的一切生理活动都与蛋白质有关。如酶蛋白能催化机体的一切化学反应,包括蛋白质、脂肪、碳水化合物的消化等;载脂蛋白运送脂肪;血红蛋白运送氧;激素蛋白调节代谢与生理活动包括情感;血浆白蛋白调节渗透压、运输金属离子、胆红素和抗生素等。3)供给机体能量:成年人每日约需要更新400g蛋白质,每克蛋白质彻底分解能释放出约4 Kcal的热量。4)为机体提供氮原料:人体内所必需的嘧啶、嘌呤、肌酸、胆碱、肾上腺素、肉碱、牛磺酸等,都是以多肽、氨基酸为原料的。表1. 世界粮食组织(FAD)和世界卫生组织(WHO)根据中国人的体质和膳食结构推荐的中国人蛋白质的摄入量(RNLs)。年 龄蛋白质RNL(g/d) 初生—6个月 1.5-3 1岁 35 3岁 45 5岁 55 7岁 60 9岁 65 10-16岁 75-85 成年女性 65 成年男性 75 妊娠 +15 乳母 +20 根据统计资料:由于贫困、工作紧张、精神压力、减肥节食、以及肠胃疾病、癌症、贫血、肾病、各种结核病、肝硬化、腹水、烧伤、失血等,以及老龄人均不同程度地存在着蛋白质的摄入不足。 上世纪80年代以来,我国营养学家对7个省18个贫困地区,1万名学龄前儿童进行了为期4年的连续调查,发现营养不良现象非常严重,其中蛋白质的摄入量不足WHO规定的60%。近年社会医学工作调查,在发达地区由于生活节奏加快,精神压力异常增加,以及办公室白领阶层的减肥节食,也导致蛋白质摄入不足,代谢异常的人群增加。二、蛋白质缺乏的体征和临床症状 单纯的蛋白质营养不良又叫加西长病,这或许是来源于非洲的单词,单纯的能量不足时叫消瘦;临床上通常把这两种现象叫单纯性蛋白质能量营养不良症或PEM。单纯的PEM症在临床上较少见到,但在慢性消耗性疾病患者中则常见,尤其是在癌症患者和艾滋病的患者中几乎占到90%以上。 现代都市和贫困地区存在着相当数量的蛋白质营养不良族群,他们的临床表现主要是能量损失或不足,如体力不支、睡眠不安、怕冷、怕热、性冷淡、无法进行正常的体力劳动和运动,其次为肌肉组织萎缩、皮肤松驰;腿部、脸部易水肿、脂肪肝、无名皮疹、伤口愈合不良、记忆力下降、视力减弱等。再者免疫力低下易感冒、感染。在做血检时通常会发现这些族群的血浆蛋白处于正常值的下限,其中白蛋白、转铁蛋白、甲状腺素结合前体蛋白和视轴蛋白(retinol-binding protein)均处于低水平时,患者易于感染各种疾病并且出现早衰症状,如果是儿童则感染后死亡率增加30%-40%,对于这类人群WHO的专家最好的建议就是迅速补充优质(或全价)的蛋白质。三、优质蛋白质和劣质蛋白质的区别。 要弄清楚何为优质蛋白质?何为劣质蛋白质?我们要引入什么是必需氨基酸的概念。营养生理学家、生化学家发现构成人体蛋白质的氨基酸共有21种,而这些氨基酸中其中有4种是可以由体内含碳和含氮底物自己合成的,被称为非必需氨基酸,还有10个必需的氨基酸,是人类机体无法制造需要从饮食中摄取的,另有7个是介于这两者之间的被称为条件必需氨基酸。表2. 必需、条件必需和非必需氨基酸 必需氨基酸条件必需氨基酸 非必需氨基酸 亮氨酸牛黄酸 丙氨酸 异亮氨酸酪氨酸 谷氨酸 缬氨酸甘氨酸 天冬氨酸 赖氨酸丝氨酸 天冬酰胺 苯丙氨酸(酪氨酸)脯氨酸 蛋氨酸(半胱氨酸)谷氨酰酸 苏氨酸 胱氨酸 色氨酸 组氨酸 精氨酸 虽然蛋白质广泛存在于许多动物性和植物性食物中,但是必需氨基酸的构成异差很大,WHO把“蛋白质其组成恰好符合人体需要”的蛋白质称为理想蛋白质,在自然界这种理想的蛋白质普遍认为是鸡蛋蛋白,因此就把鸡蛋蛋白作为衡量蛋白质优劣的参照蛋白,科学家把它作为一把尺子来衡量各种蛋白质,并制定出标准,以4种必需氨基酸为最低限来决定其优劣,即色氨酸、苏氨酸、赖氨酸或者蛋氨酸(半胱氨酸)。 通过比较科学发现,肉、鱼、蛋、牛奶、乳酪含有优质蛋白,大豆、花生、豌豆也含有较多的高质量蛋白。进一步研究发现它们都不够完美,因而要求大家对优质的动物性蛋白和植物性蛋白进行了科学搭配才是最完美的全价蛋白质(complete protein)。表3. 部分高质量蛋白
蛋白质的英文名词来源于希腊文,其含义是“第一”和“基本的”。反映了蛋白质是生命活动中最基本的和最重要的物质。蛋白质由碳、氢、氧、氮4种主要元素组成,有的蛋白质还含有硫、磷等其他元素。如血红蛋白含有铁、甲状腺球蛋白含有碘等。蛋白质的基本结构单位是氨基酸。氨基酸的特点是在分子一端含有氮和氢元素组成的化学基团——氨基。动物不能合成氨基,只有植物有利用硝酸盐合成氨基的能力。所以在动物饲养中,要依靠含有氨基酸、蛋白质的饲料,使家畜、家畜等生产蛋白质(净肉)。 蛋白质由一长串氨基酸链组成。一般都很长,如血红蛋白是由580个氨基酸组成。但氨基酸种类只有20种,在蛋白质中按严格的顺序排列,构成多种多样的生物专一性的蛋白质。由于人体不能合成氨基酸,只能从食物中获得蛋白质,并在肠内将蛋白质分解成各种氨基酸,这些氨基酸被吸收后,重新合成人体的特殊蛋白质。合成蛋白质的主要器官是肝脏。 从蛋白质这个名字看,好像蛋白质来源离不开蛋。其实动物、植物以及其他生物体都含有蛋白质。虽然最常党见的蛋白质——蛋清是白色的。但并非所有蛋白质都是白色的。血液上的血红蛋白是红色的,绿色植物的叶绿蛋白是绿色的。 同碳水化物和脂肪相比,蛋白质的两个代谢特点,一是它主要在代谢中发挥作用,而不是分解后为人体提供能量;二是蛋白质代谢的起点和终点都是蛋白质,即起点是人体的异蛋白质(如鱼的蛋白质,鸡肉蛋白质等),而终点则成了人体特有的蛋白质。蛋白质由氨基酸组成,是另一种重要的供能物质,每克蛋白质提供4卡路里的热量。但蛋白质的更主要的作用是生长发育和新陈代谢。过量的摄入蛋白质会增加肾脏的负担。因此蛋白的摄入要根据营养状况、生长发育要求达到供求平衡。通常蛋白摄入所产生的热量约占总热量的20%左右为宜。
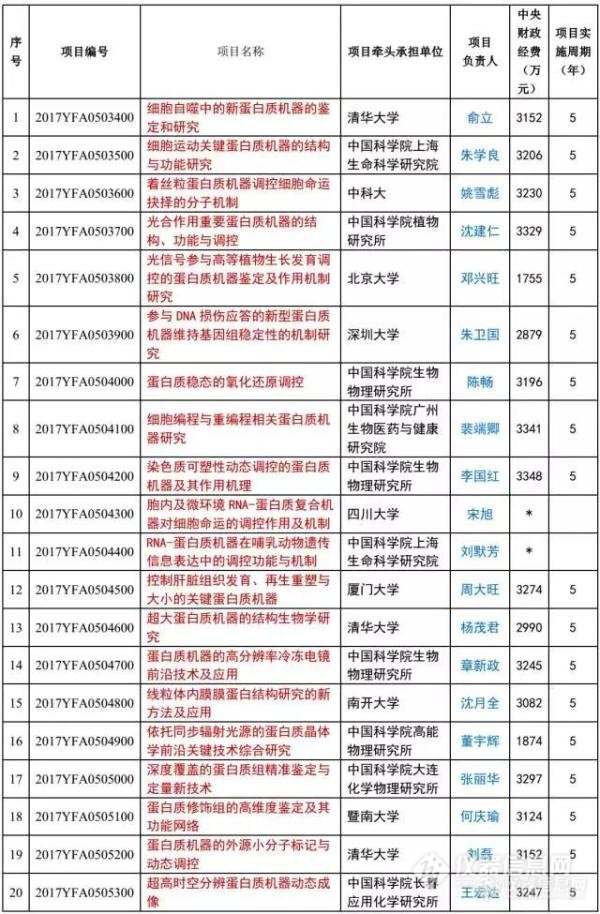
基因组(genome)包含的遗传信息经转录产生mRNA,一个细胞在特定生理或病理状态下表达的所有种类的mRNA称为转录子组(transcriptome)。很显然,不同细胞在不同生理或病理状态下转录子组包含的mRNA的种类不尽相同。mRNA经翻译产生蛋白质,一个细胞在特定生理或病理状态下表达的所有种类的蛋白质称为蛋白质组(proteome)。同理,不同细胞在不同生理或病理状态下所表达的蛋白质的种类也不尽相同。蛋白质是基因功能的实施者,因此对蛋白质结构,定位和蛋白质-蛋白质相互作用的研究将为阐明生命现象的本质提供直接的基础。生命科学是实验科学,因此生命科学的发展极大地依赖于实验技术的发展。以DNA序列分析技术为核心的基因组研究技术推动了基因组研究的日新月异,而以基因芯片技术为代表的基因表达研究技术为科学家了解基因表达规律立下汗马功劳。在蛋白质组研究中,二维电泳和质谱技术的黄金组合又为科学家掌握蛋白质表达规律再铸辉煌。蛋白质组学(proteomics)就是指研究蛋白质组的技术及这些研究得到的结果。蛋白质组学的研究试图比较细胞在不同生理或病理条件下蛋白质表达的异同,对相关蛋白质进行分类和鉴定。更重要的是蛋白质组学的研究要分析蛋白质间相互作用和蛋白质的功能。蛋白质组学的研究内容包括:1.蛋白质鉴定:可以利用一维电泳和二维电泳并结合Western等技术,利用蛋白质芯片和抗体芯片及免疫共沉淀等技术对蛋白质进行鉴定研究。2.翻译后修饰:很多mRNA表达产生的蛋白质要经历翻译后修饰如磷酸化,糖基化,酶原激活等。翻译后修饰是蛋白质调节功能的重要方式,因此对蛋白质翻译后修饰的研究对阐明蛋白质的功能具有重要作用。3.蛋白质功能确定:如分析酶活性和确定酶底物,细胞因子的生物分析/配基-受体结合分析。可以利用基因敲除和反义技术分析基因表达产物-蛋白质的功能。另外对蛋白质表达出来后在细胞内的定位研究也在一定程度上有助于蛋白质功能的了解。Clontech的荧光蛋白表达系统就是研究蛋白质在细胞内定位的一个很好的工具。4.对人类而言,蛋白质组学的研究最终要服务于人类的健康,主要指促进分子医学的发展。如寻找药物的靶分子。很多药物本身就是蛋白质,而很多药物的靶分子也是蛋白质。药物也可以干预蛋白质-蛋白质相互作用。在基础医学和疾病机理研究中,了解人不同发育、生长期和不同生理、病理条件下及不同细胞类型的基因表达的特点具有特别重要的意义。这些研究可能找到直接与特定生理或病理状态相关的分子,进一步为设计作用于特定靶分子的药物奠定基础。不同发育、生长期和不同生理、病理条件下不同的细胞类型的基因表达是不一致的,因此对蛋白质表达的研究应该精确到细胞甚至亚细胞水平。可以利用免疫组织化学技术达到这个目的,但该技术的致命缺点是通量低。LCM技术可以精确地从组织切片中取出研究者感兴趣的细胞类型,因此LCM技术实际上是一种原位技术。取出的细胞用于蛋白质样品的制备,结合抗体芯片或二维电泳-质谱的技术路线,可以对蛋白质的表达进行原位的高通量的研究。很多研究采用匀浆组织制备蛋白质样品的技术路线,其研究结论值得怀疑,因为组织匀浆后不同细胞类型的蛋白质混杂在一起,最后得到的研究数据根本无法解释蛋白质在每类细胞中的表达情况。虽然培养细胞可以得到单一类型细胞,但体外培养的细胞很难模拟体内细胞的环境,因此这样研究得出的结论也很难用于解释在体实际情况。因此在研究中首先应该将不同细胞类型分离,分离出来的不同类型细胞可以用于基因表达研究,包括mRNA和蛋白质的表达。LCM技术获得的细胞可以用于蛋白质样品的制备。可以根据需要制备总蛋白,或膜蛋白,或核蛋白等,也可以富集糖蛋白,或通过去除白蛋白来减少蛋白质类型的复杂程度。相关试剂盒均有厂商提供。蛋白质样品中的不同类型的蛋白质可以通过二维电泳进行分离。二维电泳可以将不同种类的蛋白质按照等电点和分子量差异进行高分辨率的分离。成功的二维电泳可以将2000到3000种蛋白质进行分离。电泳后对胶进行高灵敏度的染色如银染和荧光染色。如果是比较两种样品之间蛋白质表达的异同,可以在同样条件下分别制备二者的蛋白质样品,然后在同样条件下进行二维电泳,染色后比较两块胶。也可以将二者的蛋白质样品分别用不同的荧光染料标记,然后两种蛋白质样品在一块胶上进行二维电泳的分离,最后通过荧光扫描技术分析结果。胶染色后可以利用凝胶图象分析系统成像,然后通过分析软件对蛋白质点进行定量分析,并且对感兴趣的蛋白质点进行定位。通过专门的蛋白质点切割系统,可以将蛋白质点所在的胶区域进行精确切割。接着对胶中蛋白质进行酶切消化,酶切后的消化物经脱盐/浓缩处理后就可以通过点样系统将蛋白质点样到特定的材料的表面(MALDI-TOF)。最后这些蛋白质就可以在质谱系统中进行分析,从而得到蛋白质的定性数据;这些数据可以用于构建数据库或和已有的数据库进行比较分析。实际上像人类的血浆,尿液,脑脊液,乳腺,心脏,膀胱癌和磷状细胞癌及多种病原微生物的蛋白质样品的二维电泳数据库已经建立起来,研究者可以登录www.expasy.ch/www/tools.html等网站进行查询,并和自己的同类研究进行对比分析。Genomic Solution可以为研究者提供除质谱外的所有蛋白质组学研究工具,包括二维电泳系统,成像系统及分析软件,胶切割系统,蛋白质消化浓缩工作站,点样工作站等;同时还可以提供相关试剂和消耗品。LCM-二维电泳-质谱的技术路线是典型的一条蛋白质组学研究的技术路线,除此以外,LCM-抗体芯片也是一条重要的蛋白质组学研究的技术路线。即通过LCM技术获得感兴趣的细胞类型,制备细胞蛋白质样品,蛋白质经荧光染料标记后和抗体芯片杂交,从而可以比较两种样品蛋白质表达的异同。Clontech最近开发了一张抗体芯片,可以对378种膜蛋白和胞浆蛋白进行分析。该芯片同时配合了抗体芯片的全部操作过程的重要试剂,包括蛋白质制备试剂,蛋白质的荧光染料标记试剂,标记体系的纯化试剂,杂交试剂等。对于蛋白质相互作用的研究,酵母双杂交和噬菌体展示技术无疑是很好的研究方法。Clontech开发的酵母双杂交系统和NEB公司开发的噬菌体展示技术可供研究者选用。关于蛋白质组的研究,也可以将蛋白质组的部分或全部种类的蛋白质制作成蛋白质芯片,这样的蛋白质芯片可以用于蛋白质相互作用研究,蛋白表达研究和小分子蛋白结合研究。Science,Vol.293,Issue 5537,2101-2105,September 14,2001发表了一篇关于酵母蛋白质组芯片的论文。该文主要研究内容为:将酵母的5800个ORF表达成蛋白质并进行纯化点样制作芯片,然后用该芯片筛选钙调素和磷脂分子的相互作用分子。最后有必要指出的是,传统的蛋白质研究注重研究单一蛋白质,而蛋白质组学注重研究参与特定生理或病理状态的所有的蛋白质种类及其与周围环境(分子)的关系。因此蛋白质组学的研究通常是高通量的。适应这个要求,蛋白质组学相关研究工具通常都是高度自动化的系统,通量高而速度快,配合相应分析软件和数据库,研究者可以在最短的时间内处理最多的数据。

 400-886-5615
400-886-5615
 留言咨询
留言咨询
 400-807-5250
留言咨询
400-807-5250
留言咨询
 留言咨询
留言咨询









 我要推广仪器
我要推广仪器
 下载APP
下载APP