

表两个变量的相关性大小
相关系数绝对值|R| | 相关性程度 |
≥0.95 | 显著性相关 |
≥0.8 | 高度相关 |
0.5≤|R|<0.8 | 中度相关 |
0.3≤|R|<0.5 | 低度相关 |
<0.3 | 关系极弱,认为不相关 |
表 水分与光谱数据相关关系统计量
分布量纲 | 相关系数|R| |
最小值 | 0.21 |
最大值 | 0.47 |
平均值 | 0.38 |
表 相关系数法PLS建模比较
评价参数 相关系数|R| | RMSECV | RMSEP | Rp |
全波段 | 0.242 | 0.221 | 0.960 |
0.25 | 0.233 | 0.226 | 0.971 |
0.3 | 0.224 | 0.229 | 0.966 |
0.35 | 0.223 | 0.221 | 0.968 |
0.4 | 0.230 | 0.227 | 0.962 |
0.45 | 0.234 | 0.228 | 0.965 |
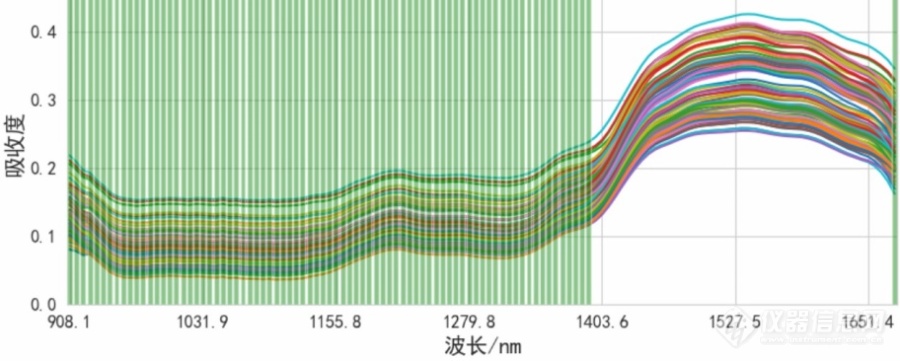
图相关系数绝对值|R|>0.35光谱波段
图 随机森林回归示意图
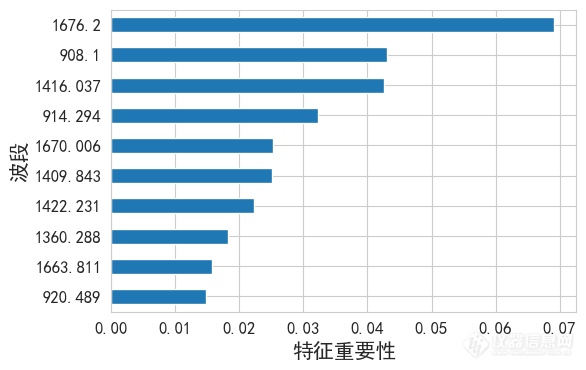
图 随机森林特征选择排名前十的特征
表 随机森林特征重要性分布
数值分布 | 特征重要性 |
最小值 | 0.0022 |
1/4分位数 | 0.0041 |
中位数 | 0.0060 |
3/4分位数 | 0.0081 |
最大值 | 0.0692 |
平均值 | 0.0080 |
表 不同特征重要性的波段模型评价
评价参数 特征重要性 | RMSECV | RMSEP | Rp |
全波段 | 0.242 | 0.221 | 0.960 |
0.0041 | 0.222 | 0.214 | 0.980 |
0.0060 | 0.216 | 0.209 | 0.983 |
0.0080 | 0.228 | 0.225 | 0.975 |
0.0081 | 0.232 | 0.230 | 0.96 |
图 随机森林波段选择
附件:

































