

试用SPSS对COD和BOD进行相关分析
依次Analyze分析-Regression回归-Linear线性,出现图1窗口

图1
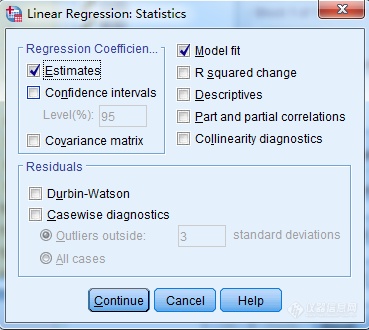
图2
图3
点击save保存,出现图4窗口。此图中Prediction values预测值框中Unstandardized未标准化是回归模型中对因变量BOD的预测值。Standardized标准化是将预测值进行标准化处理即(Y-Y均)/S。Adjusted是当某条自变量记录没参与回归方程系数估计时,所得的回归方程对其对应的预测值。S.E. of Mean predictions是预测值的均值标准误差。
Distances框下各参数意义:Mahalanobis马氏距离:自变量与其均值的距离。此值过大表明自变量取值有异常。Cook库克距离表示把一条记录从计算回归系数的样本中去除时所引起的残差变化大小。此值越大表明此记录回归系数的影响越大。Leverage values杠杆值用以测量单个观测值对拟合效果的影响程度。取值范围是0~n/(n-1)。取0表示此单个观测值对拟合无影响。
Prediction intervals预测区间框用以选择预测值的均值和单个预测值的上下置信限,默认为95%。
Residuals框中Unstandardized未标准化是观测值与预测值之差。Standardized标准化是令残差均值为0,标准差为1。Studentized学生化是用残差除以残差标准差的估计值。Delete删除表示把某条记录从样本中去除时回归所得当前记录的残差,即观测值-调整预测值。学生化删除:用剔除残差除以单个记录的标准误差。学生化与学生化剔除残差间的不同能反映补剔除的观测值在预测自身时的作用大小。
Influence Statistics影响统计框中的各子项是把记录从回归样本中剔除后计算得到的一些统计量。DfBeta剔除某条记录后回归系数的改变(包括常项)。Standardized DfBeta剔除某条记录后回归系数的改变量标准化后的值(包括常项)。当它>2/SQRT(N)时,它对回归系数有较大影响。N为自变量的记录条数。DfFit剔除某条记录后预测值的改变量。Standardized DfFit剔除某条记录后预测值的改变量标准化后的值。当它>2/SQRT(p/N)时,它对回归系数有较大影响。p为模型中的参数个数。
此界面的其它项与一元回归分析无关,就不赘述。
图4
1. 描述性的统计量,包括各变量平均数、标准偏差、有效个案数。
表1
描述统计 | |||
平均值 | 标准偏差 | 个案数 | |
BOD | 25.0195 | 7.87848 | 20 |
COD | 57.0935 | 13.75322 | 20 |
2. 相关性表列出相关系数矩阵及其单侧显著性水平。COD与BOD的相关系数为0.979。显著性为0.000,也说明二者显著相关。
表2
相关性 | |||
BOD | COD | ||
皮尔逊相关性 | BOD | 1.000 | .979 |
COD | .979 | 1.000 | |
显著性 (单尾) | BOD | . | .000 |
COD | .000 | . | |
个案数 | BOD | 20 | 20 |
COD | 20 | 20 | |
3.模型摘要
表中显示了输入的变量COD,有一个模型,无剔除的变量。表4是模型摘要表,提供了模型拟合情况。表中可看出R2为0.958,调整后为0.956变化极微,说明COD自变量对模型的贡献较大。显著性F的变化量为0.000,说明COD和BOD间存在显著相关。DW值=2.061,接近于2,说明回归分析残差不存在自相关,也就是相互独立的。
表3
输入/除去的变量a | |||
模型 | 输入的变量 | 除去的变量 | 方法 |
1 | CODb | . | 输入 |
a. 因变量:BOD | |||
b. 已输入所请求的所有变量。 | |||
表4
模型摘要b | |||||
模型 | R | R 方 | 调整后 R 方 | 标准估算的错误 | 德宾-沃森 |
1 | .979a | .958 | .956 | 1.65378 | 2.061 |
a. 预测变量:(常量), COD | |||||
b. 因变量:BOD | |||||
4.ANOVA方差分析表解读
观测值COD的总离差平方和为1179.339,其可解释的变差为1130.109,抽样误差引起的变差为49.230。二者方差分别为1130.109和2.735,相除得F统计量的观测值=413.203,对应的概率P值=0小于显著水平α(一般取α=0.05)也表明COD和BOD有显著相关。
表5
ANOVAa | ||||||
模型 | 平方和 | 自由度 | 均方 | F | 显著性 | |
1 | 回归 | 1130.109 | 1 | 1130.109 | 413.203 | .000b |
残差 | 49.230 | 18 | 2.735 | |||
总计 | 1179.339 | 19 | ||||
a. 因变量:BOD | ||||||
b. 预测变量:(常量), COD | ||||||
5.回归系数的估计值表
根据此表给出的模型建立的回归方程为:BOD=0.561*COD-6.996。在95%的置信概率下斜率的范围在0.503~0.619之间,常数项范围在-10~-3.597之间。
表6
系数a | ||||||||
模型 | 未标准化系数 | 标准化系数 | t | 显著性 | B 的 95.0% 置信区间 | |||
B | 标准错误 | Beta | 下限 | 上限 | ||||
1 | (常量) | -6.996 | 1.618 | -4.325 | .000 | -10.395 | -3.597 | |
COD | .561 | .028 | .979 | 20.327 | .000 | .503 | .619 | |
a. 因变量:BOD | ||||||||
6. 残差分析
残差分析是指由回归方程计算所得的预测值与实际样本值之间的差距。这是回归方程的重要部分。如果回归方程能反映自变量与因变量的特征和变化规律,则残差不应有明显的规律性和趋势性。
从表7 的残差统计表及图5的直方图和图6的正态概率图可看出残差基本上服从正态分布。图7的残差散点图中也可看出回归标准化残差都在±3以内,无异常值,也说明残差是相互独立的。
表7
残差统计a | |||||
最小值 | 最大值 | 平均值 | 标准偏差 | 个案数 | |
预测值 | 12.1929 | 43.5507 | 25.0195 | 7.71229 | 20 |
标准预测值 | -1.663 | 2.403 | .000 | 1.000 | 20 |
预测值的标准误差 | .370 | .984 | .500 | .156 | 20 |
调整后预测值 | 12.1814 | 42.7406 | 24.9627 | 7.64728 | 20 |
残差 | -3.49569 | 3.76431 | .00000 | 1.60967 | 20 |
标准残差 | -2.114 | 2.276 | .000 | .973 | 20 |
学生化残差 | -2.187 | 2.355 | .016 | 1.018 | 20 |
剔除残差 | -3.74192 | 4.02947 | .05678 | 1.76890 | 20 |
学生化剔除残差 | -2.480 | 2.751 | .010 | 1.119 | 20 |
马氏距离 | .004 | 5.774 | .950 | 1.378 | 20 |
库克距离 | .000 | .339 | .051 | .088 | 20 |
居中杠杆值 | .000 | .304 | .050 | .073 | 20 |
a. 因变量:BOD | |||||
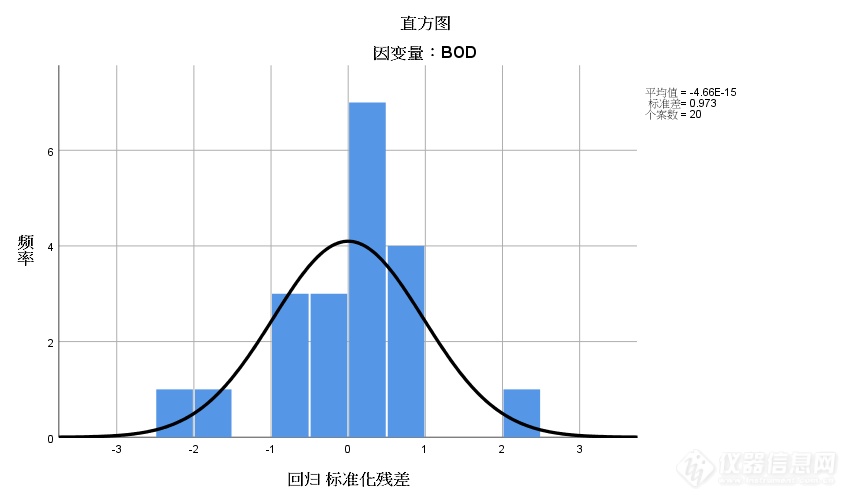
图5
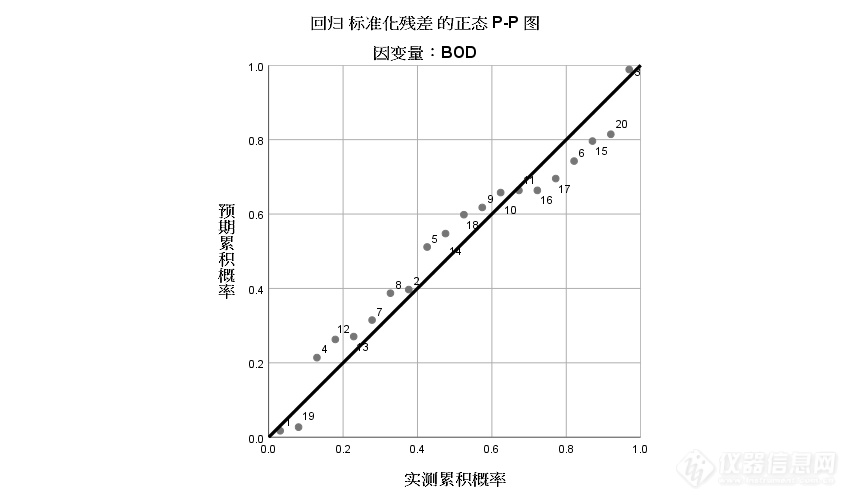
图6
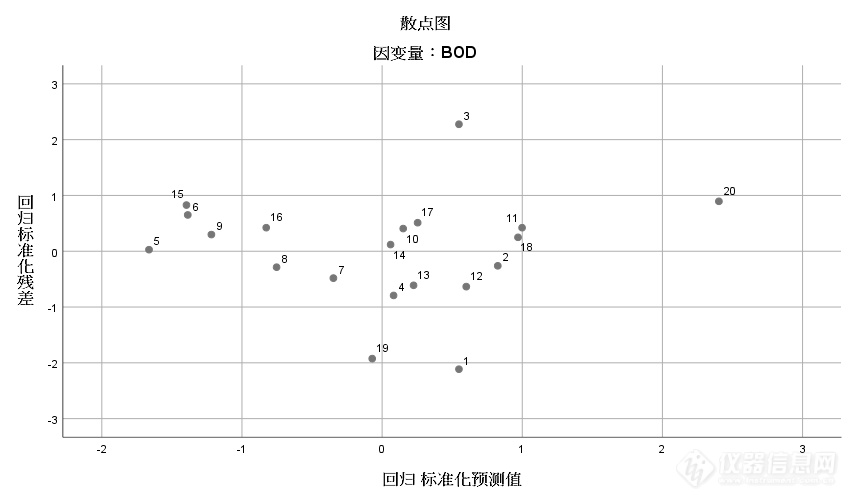
图7

































