近红外光谱的定量建模目标是连续变量,例如,某化学组分的浓度或可连续取值的理化性质。根据《多元分子光谱校正定量分系统则》GB/T 29858-2013,定量分析建模过程主要包括:样本选择、可行性模型的建立、奇异样本剔除、光谱预处理、波长选择和多元校正建模等,如图5-12所示。
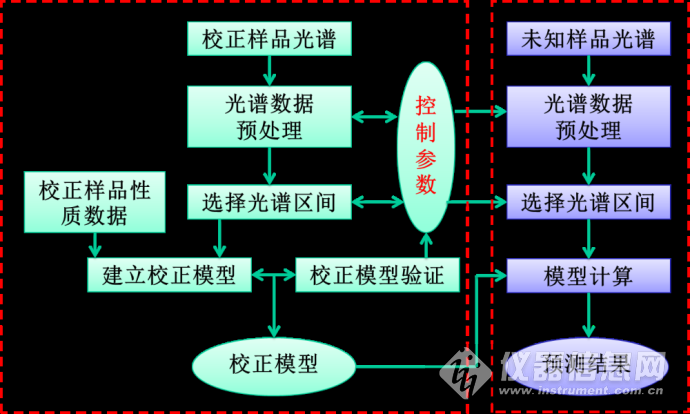
图5-12 建立定量校正模型与预测分析的流程示意图
一、样品的选择
样本的选择应遵循代表性和均匀覆盖的原则。校正集中的样本应包含使用该模型预测的待测样本中可能存在的所有化学成分,且校正集的化学成分浓度范围应涵盖使用该模型预测的待测样本中可能遇到的浓度范围,以保证待测样本的预测是通过模型内插进行分析的;校正集浓度或性质范围最好还应大于或等于参考方法的再现性标准偏差,即再现性除以2.77大小的5倍,至少不低于3倍。在整个变化范围内,校正集中样本的化学成分浓度是均匀分布的;校正集中的样本数量应足够多,以能统计确定光谱变量与校正成分浓度或性质之间的关系。
根据待测样本的复杂性,确定建立校正模型所需样本数量。如待测样本含有较少的浓度变化成分,则存在的光谱变量数较少,使用相对数量较少的校正样本便可确定光谱与样本成分浓度或性质之间的关系。如待测样本含有较多的浓度变化成分,则需较多的校正样本建立校正模型。对复杂的混合物,获得理想的校正集非常困难。只有通过建立模型初步确定模型所需光谱变量,才能确定校正样本数量是否足够。对于应用多元校正方法建模,如果使用3个或更少的因子数k(又名隐变量数、或潜变量数)建立校正模型,剔除奇异样本后校正集应至少含有24个样本;如果使用大于3的变量数k建立校正模型,剔除异常样本后校正集应至少含有6k个样本,如果建模数据进行了均值中心化预处理,剔除异常样本后校正集应至少含有6(k+1)个样本,这样,才能够保证模型中含有至少20个自由度以进行统计检验,同时保证有足够的样本数量确定光谱变量与校正成分浓度或性质之间的关系。上述样本数量要求仅为满足统计学的最低要求,实际中应根据影响建模影响因素(如环境温湿变化等)和可行性分析,探索确定合适的样本数量。
验证集中的样本应包含使用模型分析的待测样本中可能存在的所有化学组成和浓度范围。在整个变化范围内,验证集中样本的化学成分浓度是均匀分布的。验证集中的样本数量应足够多,以便能统计确定光谱变量与待校正的成分浓度或性质之间的关系。对复杂的混合物,获得一个理想的验证集非常困难。验证集中的样本数量取决于模型的复杂性。如待测样本含有较少浓度变化的成分,则光谱变量较少,使用数量较少的验证样本便可确定光谱与浓度或性质之间的关系。如待测样本含有较多浓度变化的成分,验证模型时需较多数量的验证样本。在验证过程中最好使用能通过模型内插进行分析的样本。如果模型使用了5个或更少的潜变量(k),内插样本数不能少于20;如果模型使用了大于5的潜变量,则验证集中的内插样本数应不少于4k,请读者参阅GB/T 29858-2013。
此外,根据参考值范围内样本分布的概率密度对样本加权也是一种有效的方法,以保证建立一个在整个参考值范围内都有效的模型。
二、可行性模型的建立
对于一个新的应用领域,当不能确定能否利用近红外光谱建立多元校正模型时,应进行可行性研究,以确定样本近红外光谱与其成分浓度或性质间是否存在相关关系,是否能够建立满足实际需求的模型。若可行,则扩充完善模型并验证模型。请读者可参阅GB/T 29858-2013。
三、光谱预处理
为消除光谱测量过程中引入的噪声等无关信号对模型的不利影响,宜在模型建立前采用光谱预处理方法对光谱数据进行预处理。常用光谱预处理方法包括背景扣除、散射校正、噪声去除和尺度缩放四大类。每类预处理也包含很多种算法,具体内容在本章5.4节有详细介绍。
如何从众多的光谱预处理方法中选择合适的预处理方法是个难点。预处理方法的选择一般通过两种途径:一种是观察法(Visual Inspection),即观察光谱信号特点选择相应的预处理方法;另一种途径是根据建模性能的优劣反过来选择预处理方法(Trial-and-error Strategy)。不仅单一的预处理方法可以使用,组合预处理以及集成预处理方法都可以使用。
如果利用预处理后的光谱数据建立的模型在校正、交互验证和外部验证时效果接近,且接近参考方法的准确率,则预处理方法可行,否则,可尝试其他预处理方法或者方法组合。
四、波长选择
对校正集原始光谱数据或预处理后光谱数据进行统计分析,选择随成分含量变化而变化明显的波长或频率来建立模型要比采用全波长范围建立的模型效果更好。在建立校正模型之前,宜采用波长选择方法选择校正所需的波长。波长选择方法众多,具体算法在本章5.5节有详细介绍。根据保留波长数、变量分布以及性能提高程度来选择合适研究体系的波长选择方法。
五、校正模型的建立
对于确定能利用近红外光谱多元校正方法的应用领域,可直接建立能符合实际需求的校正模型。收集足够数量的样本,采集样本光谱,测定样本成分浓度或性质参考值。测定参考值前,需要采用奇异样本识别方法剔除奇异样本或极为相近的样本,以避免不必要的参考值测定,降低参考值测定成本。
选择合适的校正样本和验证样本分别组成校正集和验证集。根据待分析体系的复杂程度和化学计量学可提供的多元校正算法,选择合适的算法。多元校正算法包括5.7部分讲到的多元线性回归(MLR)、主成分回归(PCR)、偏最小二乘回归(PLS)、人工神经网络(ANN)、支持向量回归(SVR)、极限学习机(ELM)和深度学习算法(DL)。
选择合适的数据预处理方法对数据进行预处理,选择合适的建模波长或波段,建立校正模型。处理校正集光谱、验证集光谱及待测样本光谱时应采用相同的光谱预处理方法和波长选择方法。利用验证集对校正模型进行验证,如果校正模型有效且模型的预测能力满足实际需求,则模型建立完毕;如果模型预测能力不能满足实际需求或模型有效性可疑,则检查模型建立中的每个步骤,选择其他算法或建模条件,重新建立模型,直至模型符合要求。
六、定量模型性能的评价
多元校正模型的预测效果需要经过对样本进行预测来评价。对校正集中的样本进行预测,评价模型的自测能力。对验证集的样本进行预测,评价模型的外部预测能力。
评价多元校正模型预测准确度的指标包括:交叉验证均方根误差(Root mean square error of cross validation, RMSECV)、预测均方根误差(Root mean square error of prediction, RMSEP)、校正集相关系数(Correlation coefficient of calibration, Rc)、预测集相关系数(Correlation coefficient of prediction, Rp)、剩余预测偏差(The ratio of the standard error of prediction to the standard deviation of thereference values, RPD)。其中,均方根误差越小(RMSECV/RMSEP)、相关系数(Rc/Rp)和RPD越高,表明模型预测能力越好。
多元校正模型还容易存在过拟合和欠拟合的问题。过拟合是对校正集自身的样本预测效果很好,但是对外部样本预测效果很差。欠拟合则反之。通过对比校正集的RMSECV、Rc与预测集的RMSEP、Rp的差异程度,可以判断模型是否过拟合。
多元校正模型还存在稳定性的问题。模型稳定性通常将模型运行多次,计算多次建模得到的均方根误差、相关系数、RPD等指标的均值以及方差。这些参数的方差越大,说明多元校正模型的稳定性越差。
直接作图显示模型的预测能力也是常用的模型评价方法。以目标分析物的实际测量值为横坐标,以模型的预测值为纵坐标,画散点,然后再进行线性集合。如果模型能够100%地准确预测待测样本,拟合结果应该是y=x的对角线,相关系数为1。因此,根据散点分布情况以及拟合线的斜率、截距、相关系数等来评价模型的预测能力。



































