基于近红外光谱分析技术的2,3,5-三甲基氢醌干燥失重的建模研究
中文摘要:目的在传统的真空干燥过程中,工作人员在不同时间点多次采样,离线分析产品干燥失重,从而了解产品的干燥状态。干燥不足难以清除产品中水分与有机溶剂,需要重新抽真空延长干燥时间,期间就增加了产品暴露于空气中的时间,造成产品的氧化损失。过度干燥无疑又会浪费能源。传统方法费时费力,并且损失产品,因此研究简便快速的干燥失重分析测试与监控方法具有很大应用前景。方法采用近红外光谱分析技术结合PLS算法建立TMHQ真空干燥过程水分含量的监控模型,考察多种预处理方法与波段选择方法对模型进行优化。结果建立模型的各项参数为:RMSEC=0.0893,RMSECV=0.0943,RMSEP=0.0798,R2C=0.9713,R2P=0.9832。结论所建立的方法,模型重复性与预测能力良好,可以满足TMHQ生产中真空干燥过程水分含量快速检测,以判断干燥终点。
关键词:近红外光谱分析;2,3,5-三甲基氢醌;干燥2, 3, 5-三甲基氢醌(TMHQ)是合成维生素 E的重要中间体,可与异植醇缩合生产维生素 E。TMHQ 在空气中极易被氧化,其主要来源为人工合成以及从石油化工等行业的下脚料中提取。提取方法因工艺复杂、产率较低及产品纯度不高等问题,极大地限制了其应用范围;而人工合成方法因其原料易得、工艺相对简单、转化率高等优点获得了广泛应用。TMHQ干燥终点的确定在合成中起到关键作用。在制药领域,NIRS作为一种重要的PAT工具,已成功用于药物的原辅料评价、关键过程的监测和控制、成品的快速放行和质量监测等各个环节,为保证产品质量、降低生产成本、革新生产过程发挥了重要的作用。
1 实验仪器与试剂
1.1 仪器
Antaris Ⅱ傅里叶变换近红外光谱仪(美国Thermo Fisher公司),光纤采样附件(美国SabIR),SHB-III循环水式多用真空泵(郑州长城科工贸有限公司),BT224S电子分析天平(德国Sartorius公司),ZKXFB-2真空干燥箱(上海树立仪器仪表有限公司),扁形称量瓶(40×25mm),圆底烧瓶、布氏漏斗、抽滤瓶。RESULT近红外光谱采集软件,TQAnalyst近红外光谱分析软件,Matlab数据处理软件。
1.2 试剂
TMBQ(安耐吉试剂公司,含量99%),10%钯碳催化剂(国药集团化学试剂有限公司),无水乙醇(天津富宇精细化工),氢气(济南德祥)。
2 方法
2.1TMHQ样品的制备
20ml无水乙醇溶解2gTMBQ纯品,加入到100ml两口圆底烧瓶中,加入钯碳催化剂,使用三通连接氢气气囊,封口膜密封连接处,隔膜泵抽尽圆底烧瓶内空气,再通入氢气,重复操作三次。25℃下磁力搅拌反应。反应结束后,旋蒸浓缩至剩余少量液体,蒸馏水洗涤瓶壁上产品,减压过滤后45℃真空干燥12h,称重计算产率。
利用钯碳氢气还原2,3,5-三甲基苯醌得到TMHQ,反应完毕,使用硅藻土过滤除去钯碳,旋蒸过滤液得白色粉末及片状固体,依次用适量蒸馏水与石油醚快速洗涤。将湿样品分装于11个称量瓶中,放置在真空干燥箱中干燥。干燥箱保持恒温45℃,每隔0.5h取出装有样品的称量瓶,冷却至室温,称重并采集光谱。每个称量瓶中的样品采集11-13次光谱。
2.2TMHQ干燥失重的测定
根据2,3,5-三甲基氢醌化工行业标准(HG/T4415-2012)规定,测定TMHQ样品的干燥失重,取本品2.0~2.5g,在105℃条件下烘干至重量不再变化,水分平行测定结果应不大于0.20%,取其算数平均值。
干燥失重=(m1-m2)/(m1-m0)*100%,m1为干燥前重量,m2为干燥后重量,m0为瓶重。
2.3TMHQ近红外光谱的采集
设置波长范围4000 cm-1-10000cm-1;扫描次数32次;分辨率8 cm-1,使用光纤附件漫反射方式采谱,采集样品前采集背景以消除背景干扰,每个样品重复采集三次光谱。环境温度20℃,湿度60%。
2.4样品集划分
以8个批次为校正集,3个批次为验证集,并根据主成分得分图验证校正集与验证集样品是否分布均匀。
2.5异常样本的剔除
采用主成分分布图和学生残差-杠杆值同时判别异常离群样本,并予以剔除。
2.6预处理方法选择
主要考察一阶导数、二阶导数、MSC、SNV四种预处理方法,并与无预处理的建模结果进行对比,选择出最优预处理方法。
2.7特征波段选择
使用最优预处理方法对原始光谱预处理,消除基线漂移与仪器噪声,考察GA算法、iPLS算法、与人工选择波段三种方法选择特征波段的建模效果。
2.8重复性考察
选择3个验证集样品,每个样品连续采集10次光谱,使用建立好的模型预测每张光谱,并计算出每个样品十次预测值的均值和标准偏差。 是第i个样品的第j张光谱,第i个样品共测定ri个光谱,第i个样品的预测平均值为:
是第i个样品的第j张光谱,第i个样品共测定ri个光谱,第i个样品的预测平均值为:
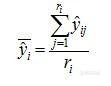
复测定的标准偏差为:
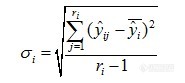
用c2检验来考察这些重复性标准偏差是否属于同一总体:
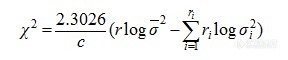
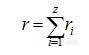
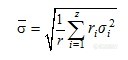
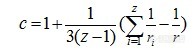
z为需要重复测定的样品数,将所得χ2与自由度(z-1)临界值比较,若χ2在临界值以下,则重复测定的所有方差属于同一总体,标准偏差均值σ可以作为近红外测定的标准偏差,近红外分析方法的重复性为z××σmax。如果χ2大于临界值,近红外分析方法的重复性随样品组分浓度不同而不同,这时,近红外分析方法的重复性不大于z××σmax(σmax为σi中的最大值)。
3结果
3.1样品集划分
选择8个批次共88个样品为校正集,3个批次共39个样品为验证集。所有样品的主成分分布图如图1。
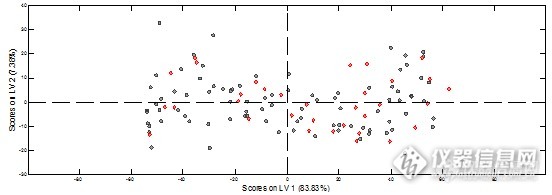
图1 样品第一第二主成分分布图
其中黑色标记代表校正集样品,红色标记为验证集样品,验证集样品均匀分布于校正集中,表明验证计划分合理,可以用于建立模型。
3.2异常样品的判别
图2为校正集样品学生残差-杠杆值分布图,图为所有样品主成分分布图,图3中椭圆虚线内的范围为95%置信范围。由两图中可见17号样品杠杆值非常高,并且超出主成分95%置信范围,判断其为异常点,予以剔除。
图2 学生残差-杠杆值分布图
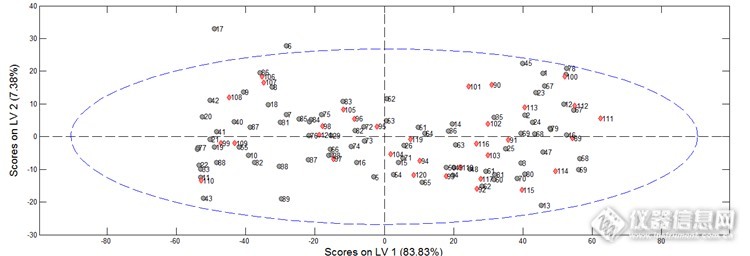
图3 95%置信范围主成分分布图
3.3预处理方法考察
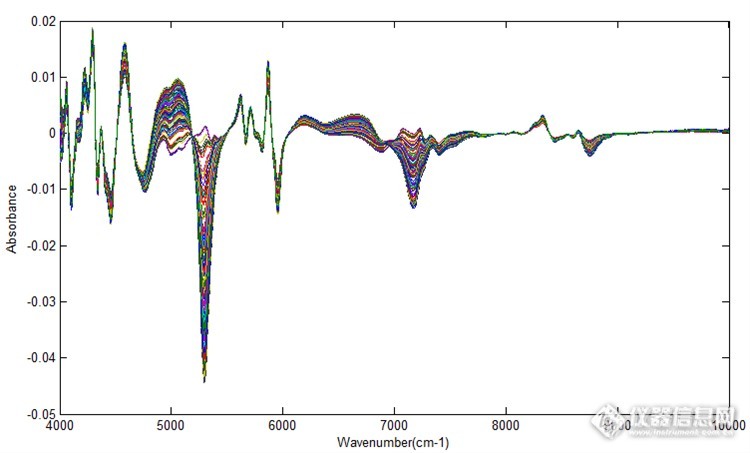
图4为所有样品原始光谱,由于对固体样品采用光纤漫反射的采谱方式,固体颗粒对光的散射作用导致基线漂移严重。分别采用一阶导数、二阶导数、MSC、SNV四种方法对原始光谱预处理,谱图如图5。经过预处理后基线漂移都得到很好的改善,并且有吸收差异的特征波段凸现出来,为波段选择提供了参考。经过导数处理的光谱基线更加平坦,出现的尖峰表示原始光谱中相互重叠多重峰在求导后已明显分离。表1为使用以上预处理方法建立PLS模型后的评价参数汇总。
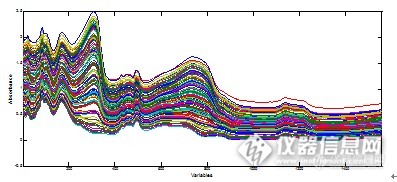
图4 原始近红外光谱图
 a
a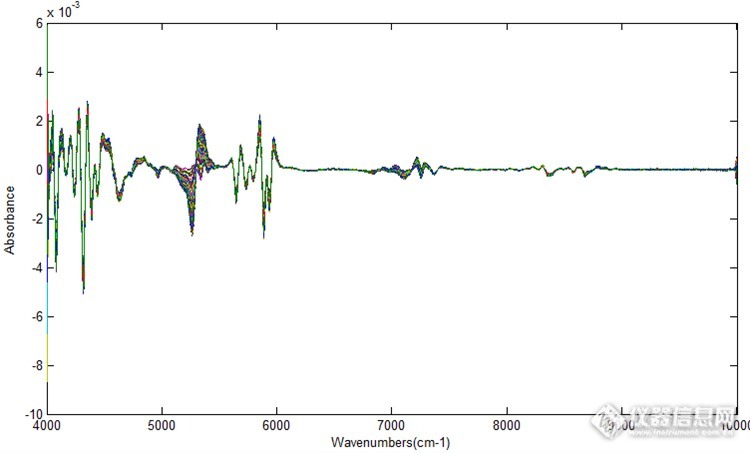 b
b
 c
c  d
d
图5 经过预处理后的光谱图(自上到下为abcd,a为一阶导数处理,b为二阶导数处理,c为MSC处理,d为SNV处理)
表1 不同预处理方法建模结果
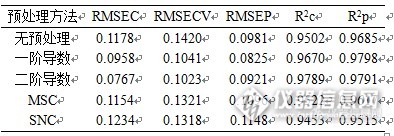
MSC、SNV只是处理谱图数据,而没有考虑浓度阵,因此有可能损失有价值信息,或者对噪声去除不完全。经过求导预处理的的模型评价参数比MSC与SNV要好,其中一阶导数与二阶导数建模效果相差不大,但是一阶导数预处理的RMSEP值最小,预示模型预测值与真实值偏差最小,模型预测能力较强,因此以一阶导数为最佳预处理方法。
3.4特征波段的选择
3.4.1iPLS方法选择结果
使用FordwardiPLS方法,最大主成分数设定为20,分别考察以50、100、200个变量为基础的建模效果。红色虚线是全波段建模的RMSECV,红色与绿色条带的高度代表以此条带的变量建模所得RMSECV,从图6中可见,绿色条带的RMSECV值最小,因此绿色条带是被选择用于建模的波段,红色条带则表示不被选择的区域。表2为不同变量基础的模型参数。变量基础为50,所选波段区间为5542 cm-1-5731cm-1,变量基础为100,所选波段区间为7085cm-1-7467cm-1,变量基础为200,所选波段区间为5542 cm-1-6309cm-1。
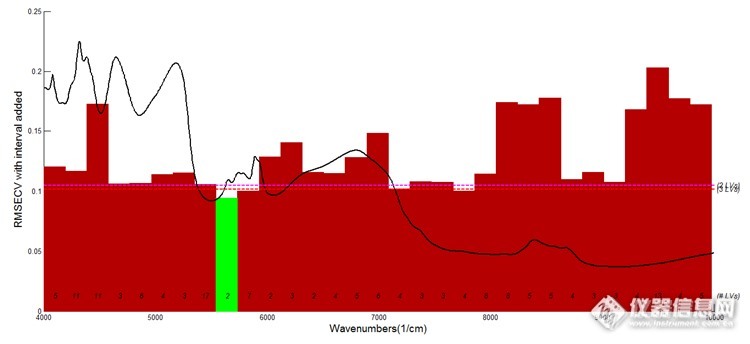
图6 iPLS算法选择变量结果图(变量基础50)
表2各变量基础的模型参数

3.4.2 GA算法选择结果
GA算法以遗传理论与自然选择为理论基础,对于一个光谱矩阵,随机产生一部分子集,计算每个自己的RMSECV,将RMSECV值高的子集舍弃,利用余下的子集繁衍并允许一定的变异率,迭代计算直至达到最低的RMSECV。
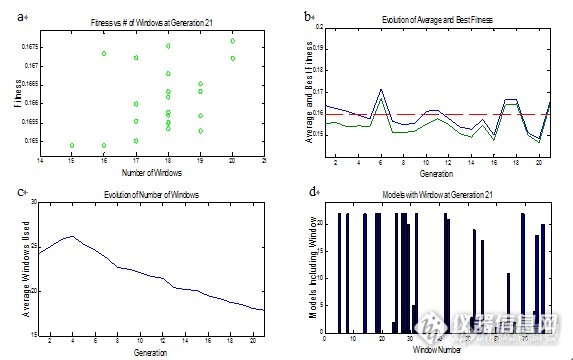
图7 GA算法运行结果图
图7为GA算法运行结果,变异率0.01%,交叉率50%,运行次数100次,重复运行3遍。b图中绿色折线表示最优适应性变化线,蓝色折线代表平均适应性变化线,两折线随迭代次数的增加逐渐相聚,在第21代时交汇,此时选择的变量为最优变量。c图表示变量数目随遗传代数的变化趋势,优势变量在遗传中将被多次采用,而与回归分析无关的变量在遗传筛选中被淘汰,变量总数较最初有所精简。d图表示在第21代时,每个个体平均选择的变量的数量。
图8中使用红色代表高RMSECV,蓝色代表低RMSECV,部分波段只有红色条带而没有蓝色条带,表示这一波段因RMSECV较高而没有被选择,例如图中a区域;图中蓝色条带部分例如b区域RMSECV值较低,在多次遗传迭代中被多次采用,表明这一波段包含较多有效信息。GA算法选出4003.85cm-1-4077.07cm-1,4312.13cm-1-4385.35cm-1,4543.34cm-1-4616.56cm-1,5391.11cm-1-5464.33cm-1,7472.00cm-1-7545.22cm-1,8319.77cm-1-8392.99cm-1,9784.10cm-1-9857.32cm-17个波段共14个变量,在平均光谱图9中为红色标出部分。
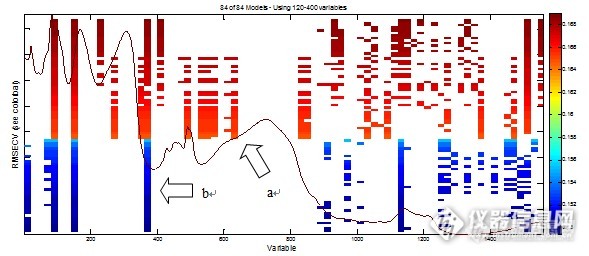
图8 GA算法运行结果图
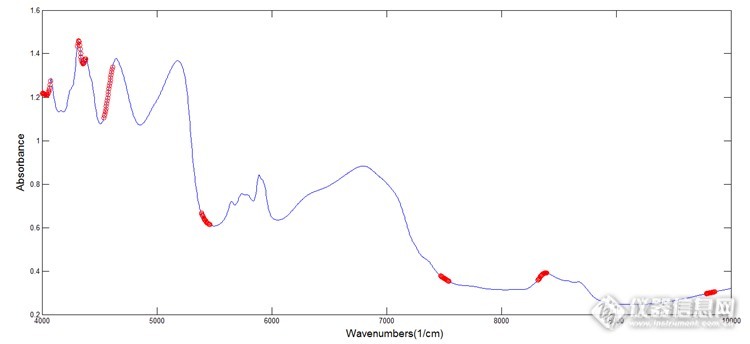
图9 GA算法选出的波段区间
3.4.3人工选择结果
算法选择波段更倾向于数学意义,以参数值判断最优区间,对于目标物质的化学意义关注不够,虽然计算准确,但是缺乏灵活性,波段选择略显盲目。因此参考算法选择结果与水的近红外特征吸收人工选择特征波段。

图10 人工选择变量
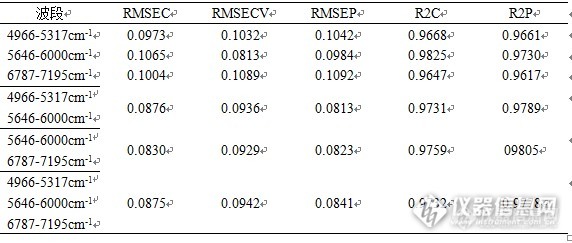
经过基线校正后,原始光谱与一阶导数预处理光谱在4966cm-1-5317cm-1,5646cm-1-6000cm-1,6787cm-1-7195cm-1吸收差异明显,在图10中为红色方框标注。上述使用iPLS与GA算法选择出的部分波段与这些波段也有交集,两种算法在5000-1-6000-1范围内均有选出波段。通常水的O-H伸缩振动一级倍频吸收在7000cm-1左右,弯曲振动与伸缩振动的组合频在5155cm-1左右,此三处波段与水的特征吸收波段极为相近。以这三个波段单独或组合建模结果如表3,通过对比可见,5646cm-1-6000cm-1与6787cm-1-7195cm-1两个波段组合建模的结果最好。
表3 人工选择波段模型评价参数
3.5最终模型
对比几种方法的评价参数发现,通过人工选择的方法选择变量所建模型的RMSEC、RMSECV最低,R2C最高,说明模型内部预测能力高;而通过iPLS方法选择变量所建模型的RMSEP最低,R2p最高,说明模型对未知样品预测能力强。因此本实验iPLS方法确定的变量建立最终模型。最优模型预测值与HPLC参比值线性关系如图11,。
表4 不同波段选择方法模型参数对比

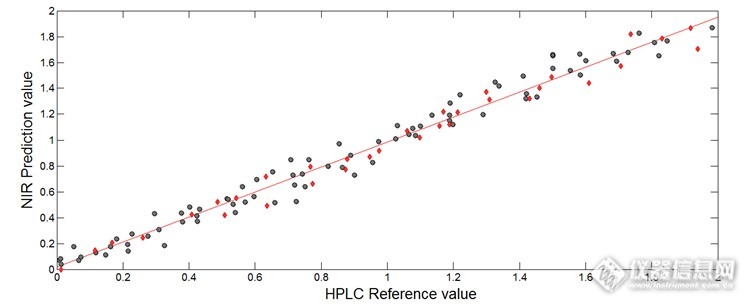
图11 最优模型NIR预测值与HPLC参考值对比图
3.6重复性考察
采集3个验证集样品光谱,对TMBQ含量模型进行重复性测试,每样品采集10次光谱。预测结果见表5。
表5 重复性考察结果
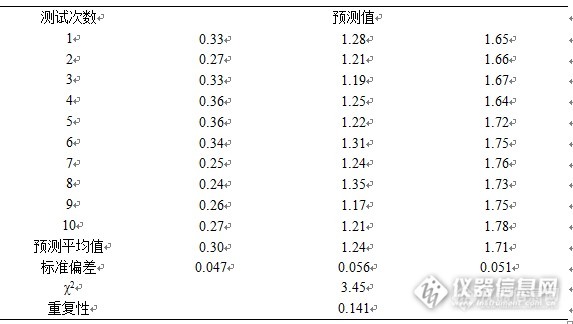
自由度为2时,χ2临界值为5.99。实际χ2小于临界值,近红外光谱分析方法重复性为,可以满足分析应用。
3.7模型预测
通过主成分分析对数据降维,前三个主成分解释了光谱的94.17%的变异,其中第一主成分(PC1)占83.83%,第二主成分(PC2)占7.38%,第三主成分(PC3)占2.96%。PC1能够解释光谱83.83%的变异,解释了大部分光谱信息,其得分随采样时间点的变化可以代表总体样本的变化趋势,如图11。
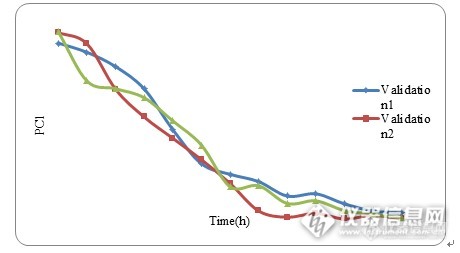
图12 验证集第一主成分得分值变化
比较验证集样品的参考值与预测值,能够更加清晰观察模型的预测能力,如图12所示,真空干燥过程中,水分含量的参考值与测定值变化趋势一致,数值相差不大,无明显差别,表明模型预测能力良好。
三批次验证集样品6h干燥失重均小于标准规定的0.2%,表明真空干燥6h已达到干燥终点,图13中6h处,水分含量趋近于0,并且曲线不再变化,这与近红外预测值一致。
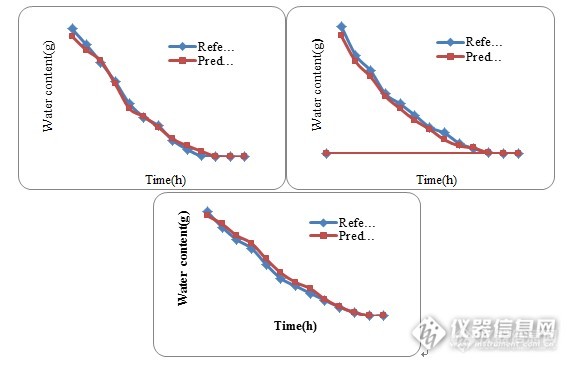
图13 验证集TMHQ样品水分含量预测结果
本实验采用近红外光谱分析技术结合PLS算法建立TMHQ真空干燥过程水分含量的监控模型,考察多种预处理方法与波段选择方法对模型进行优化。经考察,模型重复性与预测能力良好,可以满足TMHQ生产中真空干燥过程水分含量快速检测,以判断干燥终点。
参考文献
杨礼义, 钱东, 张茂昆. 双金属催化剂催化合成三甲基氢醌工艺研究. 石化技术与应用, 2000,18(2): 68-69.
Meng X J, Sun Z H, Lin S, etal. Catalytic hydroxylationof 2, 3, 6-trimethylphenol with hydrogen peroxide over copper hydroxyphosphate(Cu2(OH)PO4). Appl Catal A-Gen,. 2002,236(1): 17.
钱东,唐成国,杨礼义等, 2,3,5-三甲基氢醌的合成及其质量的影响因素. 化学试剂, 2001, 23(5), 265~266.
杨国红,张玉珍,张茹英。RP—HPLC测定三甲基氢醌的含量. 天然气化工, 2006,31(4): 63-65.
WORKMAN等著. 近红外光谱解析实用指南. 褚小立译. 北京; 化学工业出版社,2009.
Marcelo Blanco a, Miguel Castillo a, RafaelBeneyto. Study of reaction processes by in-line near-infrared spectroscopy incombination with multivariate curve resolution Esterification of myristic acidwith isopropanol. Talanta 2007.72(2), 519-525.



































